 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-TanH: Hardware Efficient Activations For Deep Learning
Oct 21, 2019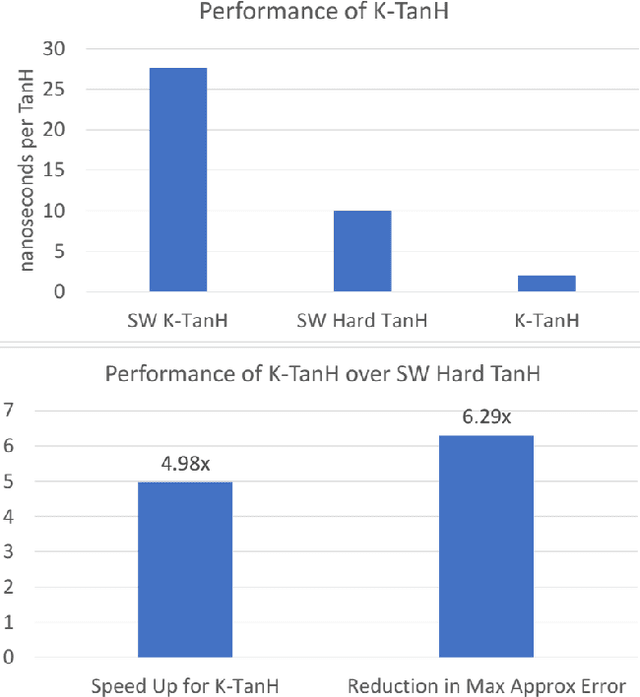
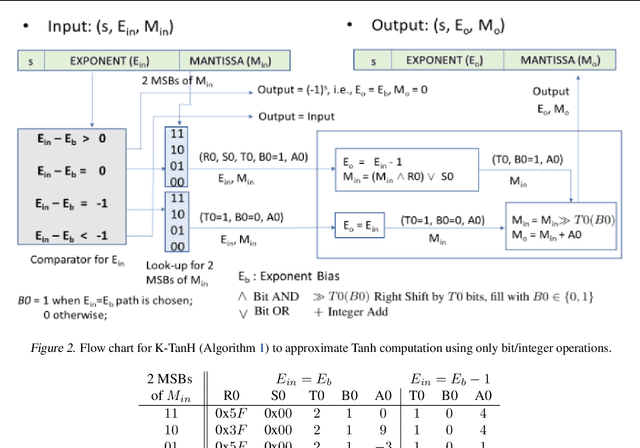

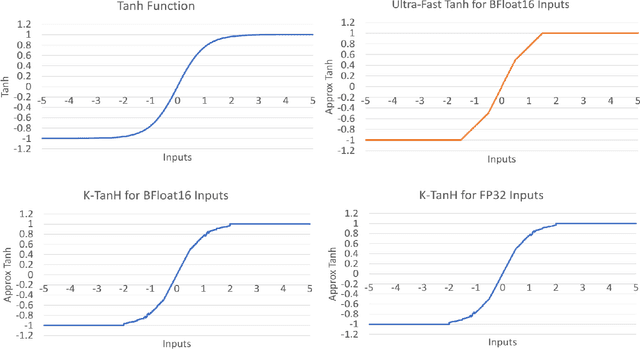
We propose K-TanH, a novel, highly accurate, hardware efficient approximation of popular activation function Tanh for Deep Learning. K-TanH consists of a sequence of parameterized bit/integer operations, such as, masking, shift and add/subtract (no floating point operation needed) where parameters are stored in a very small look-up table (bit-masking step can be eliminated). The design of K-TanH is flexible enough to deal with multiple numerical formats, such as, FP32 and BFloat16. High quality approximations to other activation functions, e.g., Swish and GELU, can be derived from K-TanH. We provide RTL design for K-TanH to demonstrate its area/power/performance efficacy. It is more accurate than existing piecewise approximations for Tanh. For example, K-TanH achieves $\sim 5\times$ speed up and $> 6\times$ reduction in maximum approximation error over software implementation of Hard TanH. Experimental results for low-precision BFloat16 training of language translation model GNMT on WMT16 data sets with approximate Tanh and Sigmoid obtained via K-TanH achieve similar accuracy and convergence as training with exact Tanh and Sigmoid.