 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Far Can Disaggregation Go? A Design-Space Exploration of Attention-FFN Disaggregation for Efficient MoE LLM Serving
May 27, 2026Modern large language model (LLM) inference has progressively disaggregated to keep pace with growing model sizes and tight TTFT and TPOT service-level objectives: from chunked-prefill aggregation, to prefill-decode (P/D) disaggregation, and most recently to operator-level Attention-FFN Disaggregation (AFD). This trend is especially important for mixture-of-experts (MoE) models, where memory-bound attention, compute-intensive expert FFNs, and MoE dispatch/combine communication create distinct resource demands. AFD further exposes this heterogeneity by placing attention and MoE-FFN execution on separate GPU groups. Each level of disaggregation deepens the scheduling design space across workload characteristics, resource allocation, and interconnect topology, raising the central question: when does each level actually pay off? We systematically characterize this trade-off for MoE inference across realistic workloads spanning input/output sequence lengths, prefix-KV reuse, and per-user latency constraints. Using chunked-prefill and P/D disaggregation as baselines, we study the benefits and limits of AFD at scale through a framework that fuses on-device kernel measurements with high-fidelity network simulation. Under strict TTFT/TPOT SLOs, AFD sustains around 4k tokens/s of system throughput on DeepSeek-V3.2 across chat, coding, and agentic-coding workloads, where non-AFD deployments are infeasible. We distill concrete takeaways for jointly optimizing throughput and interactivity, including how to partition attention and FFN across GPUs as a function of workload and model architecture, providing design principles for current rack- and cluster-scale deployments as well as future disaggregated AI infrastructure.
A Multi-Stage Validation Framework for Trustworthy Large-scale Clinical Information Extraction using Large Language Models
Apr 07, 2026Large language models (LLMs) show promise for extracting clinically meaningful information from unstructured health records, yet their translation into real-world settings is constrained by the lack of scalable and trustworthy validation approaches. Conventional evaluation methods rely heavily on annotation-intensive reference standards or incomplete structured data, limiting feasibility at population scale. We propose a multi-stage validation framework for LLM-based clinical information extraction that enables rigorous assessment under weak supervision. The framework integrates prompt calibration, rule-based plausibility filtering, semantic grounding assessment, targeted confirmatory evaluation using an independent higher-capacity judge LLM, selective expert review, and external predictive validity analysis to quantify uncertainty and characterize error modes without exhaustive manual annotation. We applied this framework to extraction of substance use disorder (SUD) diagnoses across 11 substance categories from 919,783 clinical notes. Rule-based filtering and semantic grounding removed 14.59% of LLM-positive extractions that were unsupported, irrelevant, or structurally implausible. For high-uncertainty cases, the judge LLM's assessments showed substantial agreement with subject matter expert review (Gwet's AC1=0.80). Using judge-evaluated outputs as references, the primary LLM achieved an F1 score of 0.80 under relaxed matching criteria. LLM-extracted SUD diagnoses also predicted subsequent engagement in SUD specialty care more accurately than structured-data baselines (AUC=0.80). These findings demonstrate that scalable, trustworthy deployment of LLM-based clinical information extraction is feasible without annotation-intensive evaluation.
Visual Word Sense Disambiguation with CLIP through Dual-Channel Text Prompting and Image Augmentations
Feb 06, 2026Ambiguity poses persistent challenges in natural language understanding for large language models (LLMs). To better understand how lexical ambiguity can be resolved through the visual domain, we develop an interpretable Visual Word Sense Disambiguation (VWSD) framework. The model leverages CLIP to project ambiguous language and candidate images into a shared multimodal space. We enrich textual embeddings using a dual-channel ensemble of semantic and photo-based prompts with WordNet synonyms, while image embeddings are refined through robust test-time augmentations. We then use cosine similarity to determine the image that best aligns with the ambiguous text. When evaluated on the SemEval-2023 VWSD dataset, enriching the embeddings raises the MRR from 0.7227 to 0.7590 and the Hit Rate from 0.5810 to 0.6220. Ablation studies reveal that dual-channel prompting provides strong, low-latency performance, whereas aggressive image augmentation yields only marginal gains. Additional experiments with WordNet definitions and multilingual prompt ensembles further suggest that noisy external signals tend to dilute semantic specificity, reinforcing the effectiveness of precise, CLIP-aligned prompts for visual word sense disambiguation.
HARNESS: Human-Agent Risk Navigation and Event Safety System for Proactive Hazard Forecasting in High-Risk DOE Environments
Nov 13, 2025Operational safety at mission-critical work sites is a top priority given the complex and hazardous nature of daily tasks. This paper presents the Human-Agent Risk Navigation and Event Safety System (HARNESS), a modular AI framework designed to forecast hazardous events and analyze operational risks in U.S. Department of Energy (DOE) environments. HARNESS integrates Large Language Models (LLMs) with structured work data, historical event retrieval, and risk analysis to proactively identify potential hazards. A human-in-the-loop mechanism allows subject matter experts (SMEs) to refine predictions, creating an adaptive learning loop that enhances performance over time. By combining SME collaboration with iterative agentic reasoning, HARNESS improves the reliability and efficiency of predictive safety systems. Preliminary deployment shows promising results, with future work focusing on quantitative evaluation of accuracy, SME agreement, and decision latency reduction.
Understanding and Optimizing Multi-Stage AI Inference Pipelines
Apr 16, 2025The rapid evolution of Large Language Models (LLMs) has driven the need for increasingly sophisticated inference pipelines and hardware platforms. Modern LLM serving extends beyond traditional prefill-decode workflows, incorporating multi-stage processes such as Retrieval Augmented Generation (RAG), key-value (KV) cache retrieval, dynamic model routing, and multi step reasoning. These stages exhibit diverse computational demands, requiring distributed systems that integrate GPUs, ASICs, CPUs, and memory-centric architectures. However, existing simulators lack the fidelity to model these heterogeneous, multi-engine workflows, limiting their ability to inform architectural decisions. To address this gap, we introduce HERMES, a Heterogeneous Multi-stage LLM inference Execution Simulator. HERMES models diverse request stages; including RAG, KV retrieval, reasoning, prefill, and decode across complex hardware hierarchies. HERMES supports heterogeneous clients executing multiple models concurrently unlike prior frameworks while incorporating advanced batching strategies and multi-level memory hierarchies. By integrating real hardware traces with analytical modeling, HERMES captures critical trade-offs such as memory bandwidth contention, inter-cluster communication latency, and batching efficiency in hybrid CPU-accelerator deployments. Through case studies, we explore the impact of reasoning stages on end-to-end latency, optimal batching strategies for hybrid pipelines, and the architectural implications of remote KV cache retrieval. HERMES empowers system designers to navigate the evolving landscape of LLM inference, providing actionable insights into optimizing hardware-software co-design for next-generation AI workloads.
Advancing NLP Security by Leveraging LLMs as Adversarial Engines
Oct 23, 2024This position paper proposes a novel approach to advancing NLP security by leveraging Large Language Models (LLMs) as engines for generating diverse adversarial attacks. Building upon recent work demonstrating LLMs' effectiveness in creating word-level adversarial examples, we argue for expanding this concept to encompass a broader range of attack types, including adversarial patches, universal perturbations, and targeted attacks. We posit that LLMs' sophisticated language understanding and generation capabilities can produce more effective, semantically coherent, and human-like adversarial examples across various domains and classifier architectures. This paradigm shift in adversarial NLP has far-reaching implications, potentially enhancing model robustness, uncovering new vulnerabilities, and driving innovation in defense mechanisms. By exploring this new frontier, we aim to contribute to the development of more secure, reliable, and trustworthy NLP systems for critical applications.
FRED: Flexible REduction-Distribution Interconnect and Communication Implementation for Wafer-Scale Distributed Training of DNN Models
Jun 28, 2024



Distributed Deep Neural Network (DNN) training is a technique to reduce the training overhead by distributing the training tasks into multiple accelerators, according to a parallelization strategy. However, high-performance compute and interconnects are needed for maximum speed-up and linear scaling of the system. Wafer-scale systems are a promising technology that allows for tightly integrating high-end accelerators with high-speed wafer-scale interconnects, making it an attractive platform for distributed training. However, the wafer-scale interconnect should offer high performance and flexibility for various parallelization strategies to enable maximum optimizations for compute and memory usage. In this paper, we propose FRED, a wafer-scale interconnect that is tailored for the high-BW requirements of wafer-scale networks and can efficiently execute communication patterns of different parallelization strategies. Furthermore, FRED supports in-switch collective communication execution that reduces the network traffic by approximately 2X. Our results show that FRED can improve the average end-to-end training time of ResNet-152, Transformer-17B, GPT-3, and Transformer-1T by 1.76X, 1.87X, 1.34X, and 1.4X, respectively when compared to a baseline waferscale 2D-Mesh fabric.
Demystifying Platform Requirements for Diverse LLM Inference Use Cases
Jun 03, 2024



Large language models (LLMs) have shown remarkable performance across a wide range of applications, often outperforming human experts. However, deploying these parameter-heavy models efficiently for diverse inference use cases requires carefully designed hardware platforms with ample computing, memory, and network resources. With LLM deployment scenarios and models evolving at breakneck speed, the hardware requirements to meet SLOs remains an open research question. In this work, we present an analytical tool, GenZ, to study the relationship between LLM inference performance and various platform design parameters. Our analysis provides insights into configuring platforms for different LLM workloads and use cases. We quantify the platform requirements to support SOTA LLMs models like LLaMA and GPT-4 under diverse serving settings. Furthermore, we project the hardware capabilities needed to enable future LLMs potentially exceeding hundreds of trillions of parameters. The trends and insights derived from GenZ can guide AI engineers deploying LLMs as well as computer architects designing next-generation hardware accelerators and platforms. Ultimately, this work sheds light on the platform design considerations for unlocking the full potential of large language models across a spectrum of applications. The source code is available at https://github.com/abhibambhaniya/GenZ-LLM-Analyzer .
Leveraging Large Language Models to Extract Information on Substance Use Disorder Severity from Clinical Notes: A Zero-shot Learning Approach
Mar 18, 2024
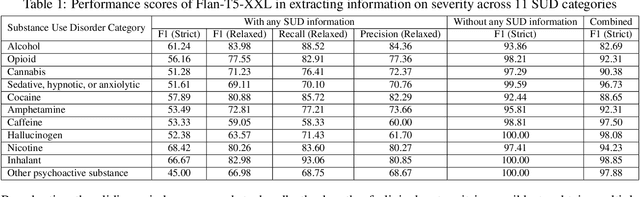


Substance use disorder (SUD) poses a major concern due to its detrimental effects on health and society. SUD identification and treatment depend on a variety of factors such as severity, co-determinants (e.g., withdrawal symptoms), and social determinants of health. Existing diagnostic coding systems used by American insurance providers, like the International Classification of Diseases (ICD-10), lack granularity for certain diagnoses, but clinicians will add this granularity (as that found within the Diagnostic and Statistical Manual of Mental Disorders classification or DSM-5) as supplemental unstructured text in clinical notes. Traditional natural language processing (NLP) methods face limitations in accurately parsing such diverse clinical language. Large Language Models (LLMs) offer promise in overcoming these challenges by adapting to diverse language patterns. This study investigates the application of LLMs for extracting severity-related information for various SUD diagnoses from clinical notes. We propose a workflow employing zero-shot learning of LLMs with carefully crafted prompts and post-processing techniques. Through experimentation with Flan-T5, an open-source LLM, we demonstrate its superior recall compared to the rule-based approach. Focusing on 11 categories of SUD diagnoses, we show the effectiveness of LLMs in extracting severity information, contributing to improved risk assessment and treatment planning for SUD patients.
Dynamic Q&A of Clinical Documents with Large Language Models
Jan 19, 2024



Electronic health records (EHRs) house crucial patient data in clinical notes. As these notes grow in volume and complexity, manual extraction becomes challenging. This work introduces a natural language interface using large language models (LLMs) for dynamic question-answering on clinical notes. Our chatbot, powered by Langchain and transformer-based LLMs, allows users to query in natural language, receiving relevant answers from clinical notes. Experiments, utilizing various embedding models and advanced LLMs, show Wizard Vicuna's superior accuracy, albeit with high compute demands. Model optimization, including weight quantization, improves latency by approximately 48 times. Promising results indicate potential, yet challenges such as model hallucinations and limited diverse medical case evaluations remain. Addressing these gaps is crucial for unlocking the value in clinical notes and advancing AI-driven clinical decision-making.