 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Word Sense Disambiguation with CLIP through Dual-Channel Text Prompting and Image Augmentations
Feb 06, 2026Ambiguity poses persistent challenges in natural language understanding for large language models (LLMs). To better understand how lexical ambiguity can be resolved through the visual domain, we develop an interpretable Visual Word Sense Disambiguation (VWSD) framework. The model leverages CLIP to project ambiguous language and candidate images into a shared multimodal space. We enrich textual embeddings using a dual-channel ensemble of semantic and photo-based prompts with WordNet synonyms, while image embeddings are refined through robust test-time augmentations. We then use cosine similarity to determine the image that best aligns with the ambiguous text. When evaluated on the SemEval-2023 VWSD dataset, enriching the embeddings raises the MRR from 0.7227 to 0.7590 and the Hit Rate from 0.5810 to 0.6220. Ablation studies reveal that dual-channel prompting provides strong, low-latency performance, whereas aggressive image augmentation yields only marginal gains. Additional experiments with WordNet definitions and multilingual prompt ensembles further suggest that noisy external signals tend to dilute semantic specificity, reinforcing the effectiveness of precise, CLIP-aligned prompts for visual word sense disambiguation.
Question-Answering System Extracts Information on Injection Drug Use from Clinical Progress Notes
May 15, 2023Injection drug use (IDU) is a dangerous health behavior that increases mortality and morbidity. Identifying IDU early and initiating harm reduction interventions can benefit individuals at risk. However, extracting IDU behaviors from patients' electronic health records (EHR) is difficult because there is no International Classification of Disease (ICD) code and the only place IDU information can be indicated are unstructured free-text clinical progress notes. Although natural language processing (NLP) can efficiently extract this information from unstructured data, there are no validated tools. To address this gap in clinical information, we design and demonstrate a question-answering (QA) framework to extract information on IDU from clinical progress notes. Unlike other methods discussed in the literature, the QA model is able to extract various types of information without being constrained by predefined entities, relations, or concepts. Our framework involves two main steps: (1) generating a gold-standard QA dataset and (2) developing and testing the QA model. This paper also demonstrates the QA model's ability to extract IDU-related information on temporally out-of-distribution data. The results indicate that the majority (51%) of the extracted information by the QA model exactly matches the gold-standard answer and 73% of them contain the gold-standard answer with some additional surrounding words.
Effects of Real-Life Traffic Sign Alteration on YOLOv7- an Object Recognition Model
May 09, 2023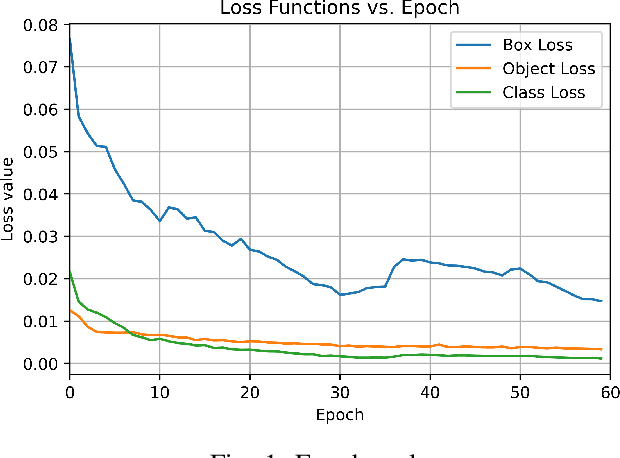
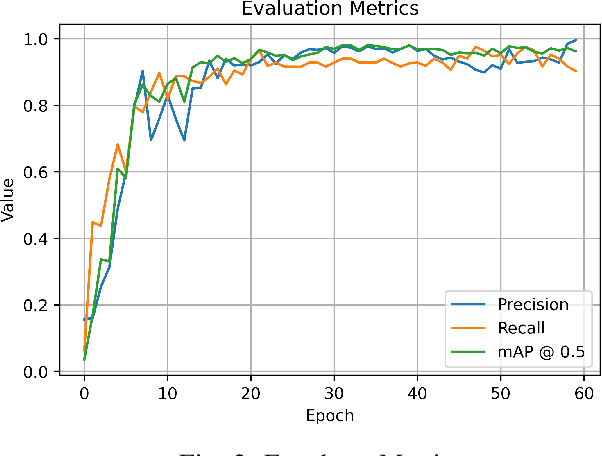
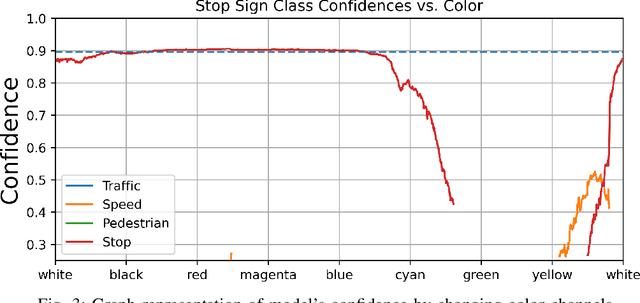

The advancement of Image Processing has led to the widespread use of Object Recognition (OR) models in various applications, such as airport security and mail sorting. These models have become essential in signifying the capabilities of AI and supporting vital services like national postal operations. However, the performance of OR models can be impeded by real-life scenarios, such as traffic sign alteration. Therefore, this research investigates the effects of altered traffic signs on the accuracy and performance of object recognition models. To this end, a publicly available dataset was used to create different types of traffic sign alterations, including changes to size, shape, color, visibility, and angles. The impact of these alterations on the YOLOv7 (You Only Look Once) model's detection and classification abilities were analyzed. It reveals that the accuracy of object detection models decreases significantly when exposed to modified traffic signs under unlikely conditions. This study highlights the significance of enhancing the robustness of object detection models in real-life scenarios and the need for further investigation in this area to improve their accuracy and reliability.
BioADAPT-MRC: Adversarial Learning-based Domain Adaptation Improves Biomedical Machine Reading Comprehension Task
Feb 26, 2022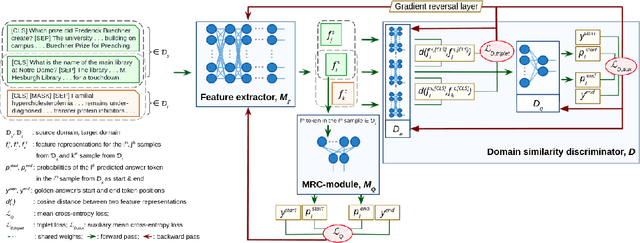

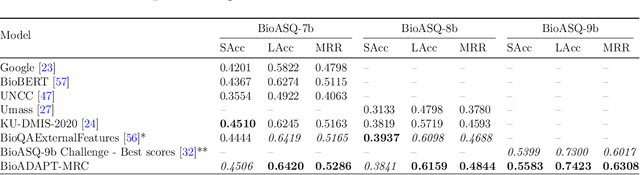
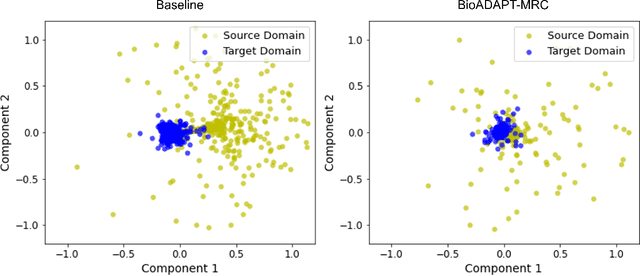
Motivation: Biomedical machine reading comprehension (biomedical-MRC) aims to comprehend complex biomedical narratives and assist healthcare professionals in retrieving information from them. The high performance of modern neural network-based MRC systems depends on high-quality, large-scale, human-annotated training datasets. In the biomedical domain, a crucial challenge in creating such datasets is the requirement for domain knowledge, inducing the scarcity of labeled data and the need for transfer learning from the labeled general-purpose (source) domain to the biomedical (target) domain. However, there is a discrepancy in marginal distributions between the general-purpose and biomedical domains due to the variances in topics. Therefore, direct-transferring of learned representations from a model trained on a general-purpose domain to the biomedical domain can hurt the model's performance. Results: We present an adversarial learning-based domain adaptation framework for the biomedical machine reading comprehension task (BioADAPT-MRC), a neural network-based method to address the discrepancies in the marginal distributions between the general and biomedical domain datasets. BioADAPT-MRC relaxes the need for generating pseudo labels for training a well-performing biomedical-MRC model. We extensively evaluate the performance of BioADAPT-MRC by comparing it with the best existing methods on three widely used benchmark biomedical-MRC datasets -- BioASQ-7b, BioASQ-8b, and BioASQ-9b. Our results suggest that without using any synthetic or human-annotated data from the biomedical domain, BioADAPT-MRC can achieve state-of-the-art performance on these datasets. Availability: BioADAPT-MRC is freely available as an open-source project at\\https://github.com/mmahbub/BioADAPT-MRC
The Sensitivity of Word Embeddings-based Author Detection Models to Semantic-preserving Adversarial Perturbations
Feb 23, 2021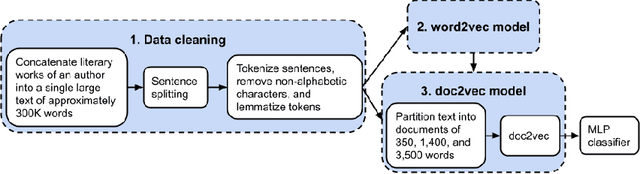

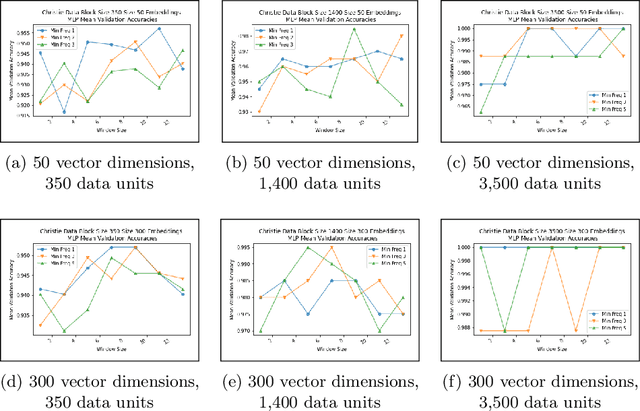

Authorship analysis is an important subject in the field of natural language processing. It allows the detection of the most likely writer of articles, news, books, or messages. This technique has multiple uses in tasks related to authorship attribution, detection of plagiarism, style analysis, sources of misinformation, etc. The focus of this paper is to explore the limitations and sensitiveness of established approaches to adversarial manipulations of inputs. To this end, and using those established techniques, we first developed an experimental frame-work for author detection and input perturbations. Next, we experimentally evaluated the performance of the authorship detection model to a collection of semantic-preserving adversarial perturbations of input narratives. Finally, we compare and analyze the effects of different perturbation strategies, input and model configurations, and the effects of these on the author detection model.
Precision Medicine as an Accelerator for Next Generation Cognitive Supercomputing
Apr 29, 2018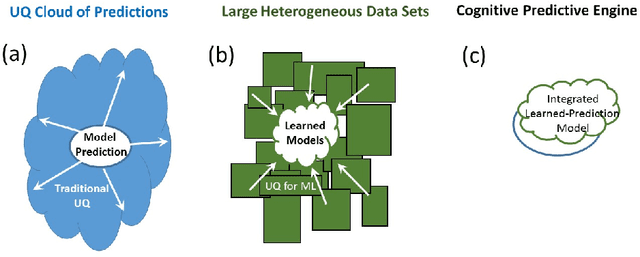
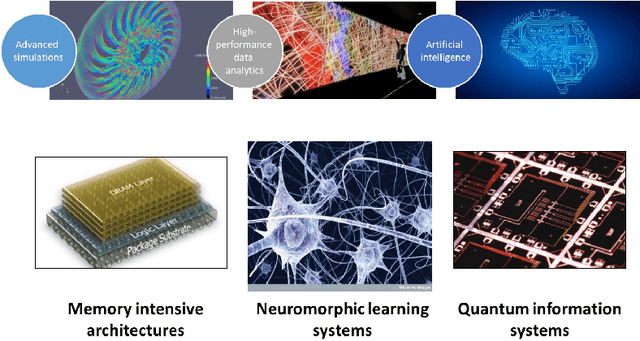
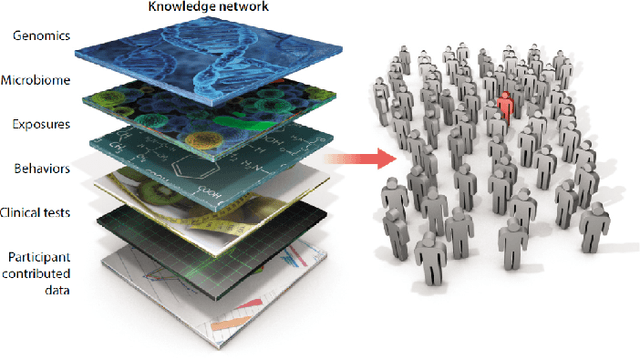
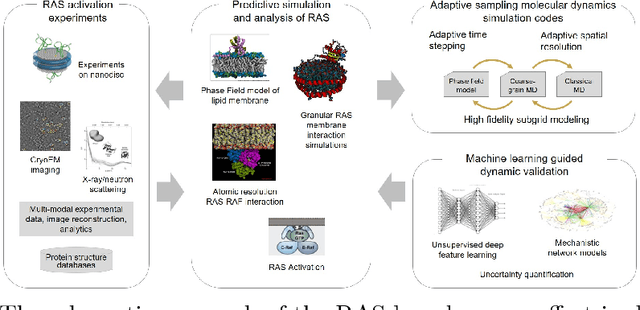
In the past several years, we have taken advantage of a number of opportunities to advance the intersection of next generation high-performance computing AI and big data technologies through partnerships in precision medicine. Today we are in the throes of piecing together what is likely the most unique convergence of medical data and computer technologies. But more deeply, we observe that the traditional paradigm of computer simulation and prediction needs fundamental revision. This is the time for a number of reasons. We will review what the drivers are, why now, how this has been approached over the past several years, and where we are heading.