 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Shift Analysis in Chest Radiographs Classification in a Veterans Healthcare Administration Population
Jul 30, 2024



Objectives: This study aims to assess the impact of domain shift on chest X-ray classification accuracy and to analyze the influence of ground truth label quality and demographic factors such as age group, sex, and study year. Materials and Methods: We used a DenseNet121 model pretrained MIMIC-CXR dataset for deep learning-based multilabel classification using ground truth labels from radiology reports extracted using the CheXpert and CheXbert Labeler. We compared the performance of the 14 chest X-ray labels on the MIMIC-CXR and Veterans Healthcare Administration chest X-ray dataset (VA-CXR). The VA-CXR dataset comprises over 259k chest X-ray images spanning between the years 2010 and 2022. Results: The validation of ground truth and the assessment of multi-label classification performance across various NLP extraction tools revealed that the VA-CXR dataset exhibited lower disagreement rates than the MIMIC-CXR datasets. Additionally, there were notable differences in AUC scores between models utilizing CheXpert and CheXbert. When evaluating multi-label classification performance across different datasets, minimal domain shift was observed in unseen datasets, except for the label "Enlarged Cardiomediastinum." The study year's subgroup analyses exhibited the most significant variations in multi-label classification model performance. These findings underscore the importance of considering domain shifts in chest X-ray classification tasks, particularly concerning study years. Conclusion: Our study reveals the significant impact of domain shift and demographic factors on chest X-ray classification, emphasizing the need for improved transfer learning and equitable model development. Addressing these challenges is crucial for advancing medical imaging and enhancing patient care.
VISION: Toward a Standardized Process for Radiology Image Management at the National Level
Apr 29, 2024The compilation and analysis of radiological images poses numerous challenges for researchers. The sheer volume of data as well as the computational needs of algorithms capable of operating on images are extensive. Additionally, the assembly of these images alone is difficult, as these exams may differ widely in terms of clinical context, structured annotation available for model training, modality, and patient identifiers. In this paper, we describe our experiences and challenges in establishing a trusted collection of radiology images linked to the United States Department of Veterans Affairs (VA) electronic health record database. We also discuss implications in making this repository research-ready for medical investigators. Key insights include uncovering the specific procedures required for transferring images from a clinical to a research-ready environment, as well as roadblocks and bottlenecks in this process that may hinder future efforts at automation.
Leveraging Large Language Models to Extract Information on Substance Use Disorder Severity from Clinical Notes: A Zero-shot Learning Approach
Mar 18, 2024
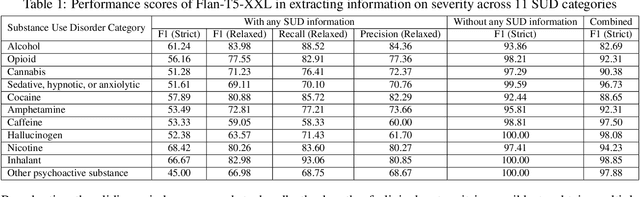


Substance use disorder (SUD) poses a major concern due to its detrimental effects on health and society. SUD identification and treatment depend on a variety of factors such as severity, co-determinants (e.g., withdrawal symptoms), and social determinants of health. Existing diagnostic coding systems used by American insurance providers, like the International Classification of Diseases (ICD-10), lack granularity for certain diagnoses, but clinicians will add this granularity (as that found within the Diagnostic and Statistical Manual of Mental Disorders classification or DSM-5) as supplemental unstructured text in clinical notes. Traditional natural language processing (NLP) methods face limitations in accurately parsing such diverse clinical language. Large Language Models (LLMs) offer promise in overcoming these challenges by adapting to diverse language patterns. This study investigates the application of LLMs for extracting severity-related information for various SUD diagnoses from clinical notes. We propose a workflow employing zero-shot learning of LLMs with carefully crafted prompts and post-processing techniques. Through experimentation with Flan-T5, an open-source LLM, we demonstrate its superior recall compared to the rule-based approach. Focusing on 11 categories of SUD diagnoses, we show the effectiveness of LLMs in extracting severity information, contributing to improved risk assessment and treatment planning for SUD patients.
Dynamic Q&A of Clinical Documents with Large Language Models
Jan 19, 2024



Electronic health records (EHRs) house crucial patient data in clinical notes. As these notes grow in volume and complexity, manual extraction becomes challenging. This work introduces a natural language interface using large language models (LLMs) for dynamic question-answering on clinical notes. Our chatbot, powered by Langchain and transformer-based LLMs, allows users to query in natural language, receiving relevant answers from clinical notes. Experiments, utilizing various embedding models and advanced LLMs, show Wizard Vicuna's superior accuracy, albeit with high compute demands. Model optimization, including weight quantization, improves latency by approximately 48 times. Promising results indicate potential, yet challenges such as model hallucinations and limited diverse medical case evaluations remain. Addressing these gaps is crucial for unlocking the value in clinical notes and advancing AI-driven clinical decision-making.
Question-Answering System Extracts Information on Injection Drug Use from Clinical Progress Notes
May 15, 2023Injection drug use (IDU) is a dangerous health behavior that increases mortality and morbidity. Identifying IDU early and initiating harm reduction interventions can benefit individuals at risk. However, extracting IDU behaviors from patients' electronic health records (EHR) is difficult because there is no International Classification of Disease (ICD) code and the only place IDU information can be indicated are unstructured free-text clinical progress notes. Although natural language processing (NLP) can efficiently extract this information from unstructured data, there are no validated tools. To address this gap in clinical information, we design and demonstrate a question-answering (QA) framework to extract information on IDU from clinical progress notes. Unlike other methods discussed in the literature, the QA model is able to extract various types of information without being constrained by predefined entities, relations, or concepts. Our framework involves two main steps: (1) generating a gold-standard QA dataset and (2) developing and testing the QA model. This paper also demonstrates the QA model's ability to extract IDU-related information on temporally out-of-distribution data. The results indicate that the majority (51%) of the extracted information by the QA model exactly matches the gold-standard answer and 73% of them contain the gold-standard answer with some additional surrounding words.