 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Shift Analysis in Chest Radiographs Classification in a Veterans Healthcare Administration Population
Jul 30, 2024



Objectives: This study aims to assess the impact of domain shift on chest X-ray classification accuracy and to analyze the influence of ground truth label quality and demographic factors such as age group, sex, and study year. Materials and Methods: We used a DenseNet121 model pretrained MIMIC-CXR dataset for deep learning-based multilabel classification using ground truth labels from radiology reports extracted using the CheXpert and CheXbert Labeler. We compared the performance of the 14 chest X-ray labels on the MIMIC-CXR and Veterans Healthcare Administration chest X-ray dataset (VA-CXR). The VA-CXR dataset comprises over 259k chest X-ray images spanning between the years 2010 and 2022. Results: The validation of ground truth and the assessment of multi-label classification performance across various NLP extraction tools revealed that the VA-CXR dataset exhibited lower disagreement rates than the MIMIC-CXR datasets. Additionally, there were notable differences in AUC scores between models utilizing CheXpert and CheXbert. When evaluating multi-label classification performance across different datasets, minimal domain shift was observed in unseen datasets, except for the label "Enlarged Cardiomediastinum." The study year's subgroup analyses exhibited the most significant variations in multi-label classification model performance. These findings underscore the importance of considering domain shifts in chest X-ray classification tasks, particularly concerning study years. Conclusion: Our study reveals the significant impact of domain shift and demographic factors on chest X-ray classification, emphasizing the need for improved transfer learning and equitable model development. Addressing these challenges is crucial for advancing medical imaging and enhancing patient care.
VISION: Toward a Standardized Process for Radiology Image Management at the National Level
Apr 29, 2024The compilation and analysis of radiological images poses numerous challenges for researchers. The sheer volume of data as well as the computational needs of algorithms capable of operating on images are extensive. Additionally, the assembly of these images alone is difficult, as these exams may differ widely in terms of clinical context, structured annotation available for model training, modality, and patient identifiers. In this paper, we describe our experiences and challenges in establishing a trusted collection of radiology images linked to the United States Department of Veterans Affairs (VA) electronic health record database. We also discuss implications in making this repository research-ready for medical investigators. Key insights include uncovering the specific procedures required for transferring images from a clinical to a research-ready environment, as well as roadblocks and bottlenecks in this process that may hinder future efforts at automation.
Image Gradient Decomposition for Parallel and Memory-Efficient Ptychographic Reconstruction
May 12, 2022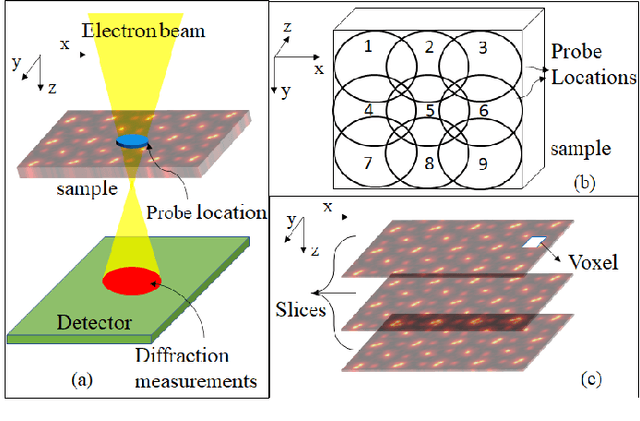
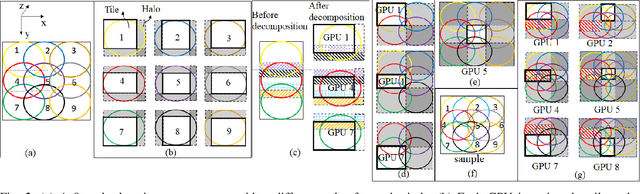
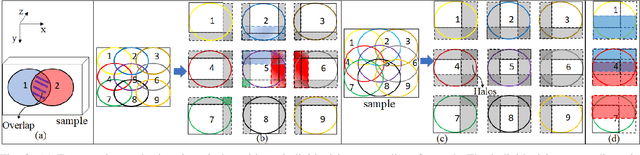
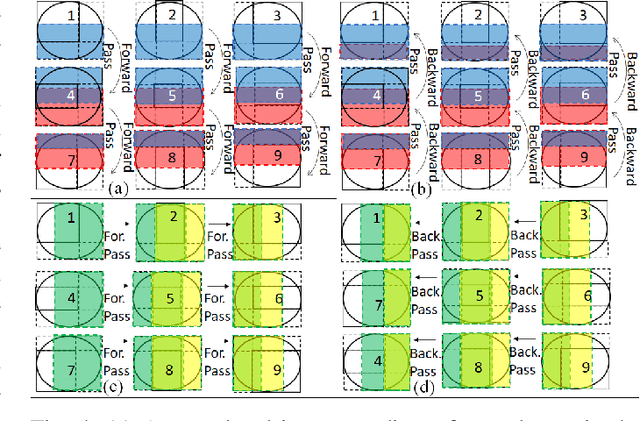
Ptychography is a popular microscopic imaging modality for many scientific discoveries and sets the record for highest image resolution. Unfortunately, the high image resolution for ptychographic reconstruction requires significant amount of memory and computations, forcing many applications to compromise their image resolution in exchange for a smaller memory footprint and a shorter reconstruction time. In this paper, we propose a novel image gradient decomposition method that significantly reduces the memory footprint for ptychographic reconstruction by tessellating image gradients and diffraction measurements into tiles. In addition, we propose a parallel image gradient decomposition method that enables asynchronous point-to-point communications and parallel pipelining with minimal overhead on a large number of GPUs. Our experiments on a Titanate material dataset (PbTiO3) with 16632 probe locations show that our Gradient Decomposition algorithm reduces memory footprint by 51 times. In addition, it achieves time-to-solution within 2.2 minutes by scaling to 4158 GPUs with a super-linear speedup at 364% efficiency. This performance is 2.7 times more memory efficient, 9 times more scalable and 86 times faster than the state-of-the-art algorithm.
Automated and Autonomous Experiment in Electron and Scanning Probe Microscopy
Mar 22, 2021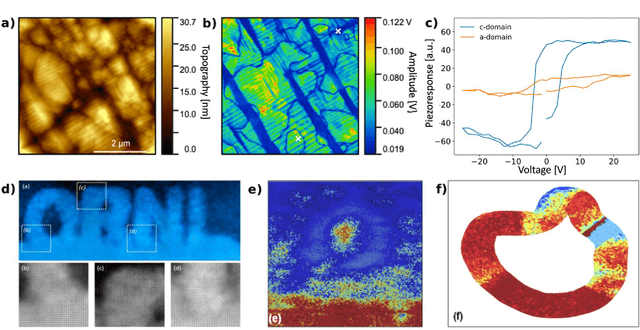
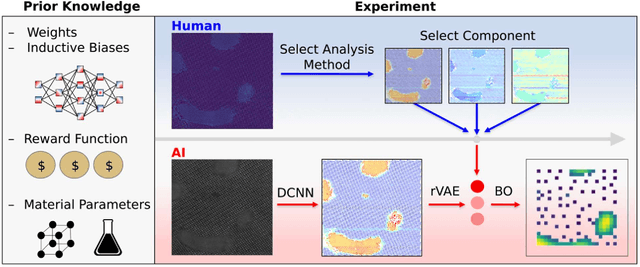
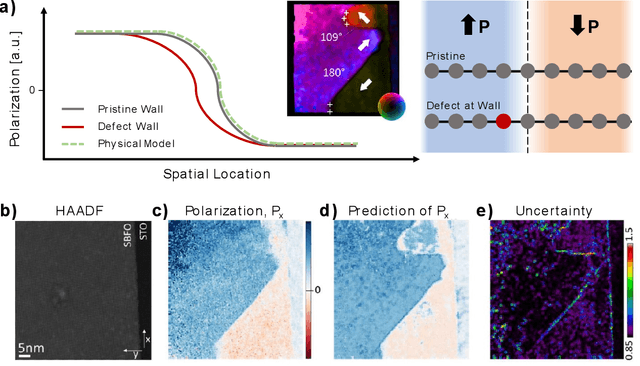
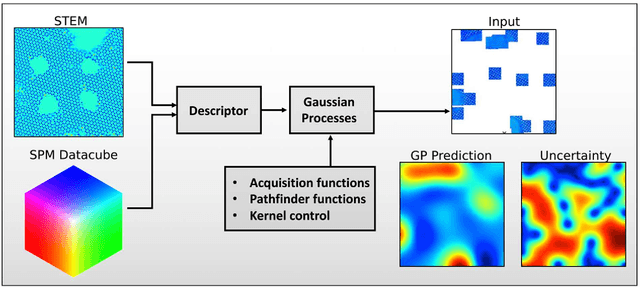
Machine learning and artificial intelligence (ML/AI) are rapidly becoming an indispensable part of physics research, with domain applications ranging from theory and materials prediction to high-throughput data analysis. In parallel, the recent successes in applying ML/AI methods for autonomous systems from robotics through self-driving cars to organic and inorganic synthesis are generating enthusiasm for the potential of these techniques to enable automated and autonomous experiment (AE) in imaging. Here, we aim to analyze the major pathways towards AE in imaging methods with sequential image formation mechanisms, focusing on scanning probe microscopy (SPM) and (scanning) transmission electron microscopy ((S)TEM). We argue that automated experiments should necessarily be discussed in a broader context of the general domain knowledge that both informs the experiment and is increased as the result of the experiment. As such, this analysis should explore the human and ML/AI roles prior to and during the experiment, and consider the latencies, biases, and knowledge priors of the decision-making process. Similarly, such discussion should include the limitations of the existing imaging systems, including intrinsic latencies, non-idealities and drifts comprising both correctable and stochastic components. We further pose that the role of the AE in microscopy is not the exclusion of human operators (as is the case for autonomous driving), but rather automation of routine operations such as microscope tuning, etc., prior to the experiment, and conversion of low latency decision making processes on the time scale spanning from image acquisition to human-level high-order experiment planning.
Computer-aided abnormality detection in chest radiographs in a clinical setting via domain-adaptation
Dec 19, 2020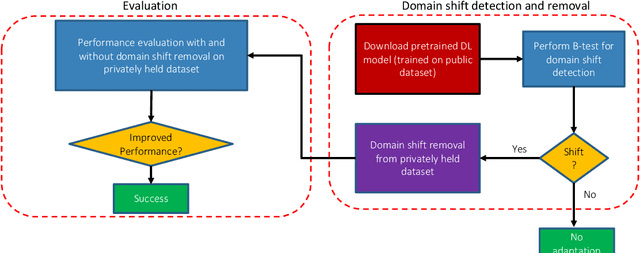
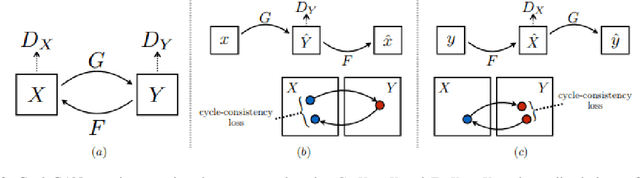
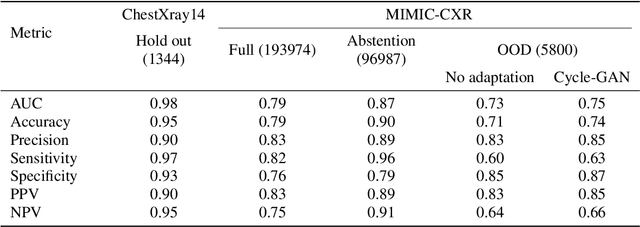
Deep learning (DL) models are being deployed at medical centers to aid radiologists for diagnosis of lung conditions from chest radiographs. Such models are often trained on a large volume of publicly available labeled radiographs. These pre-trained DL models' ability to generalize in clinical settings is poor because of the changes in data distributions between publicly available and privately held radiographs. In chest radiographs, the heterogeneity in distributions arises from the diverse conditions in X-ray equipment and their configurations used for generating the images. In the machine learning community, the challenges posed by the heterogeneity in the data generation source is known as domain shift, which is a mode shift in the generative model. In this work, we introduce a domain-shift detection and removal method to overcome this problem. Our experimental results show the proposed method's effectiveness in deploying a pre-trained DL model for abnormality detection in chest radiographs in a clinical setting.
Model Reduction of Shallow CNN Model for Reliable Deployment of Information Extraction from Medical Reports
Jul 31, 2020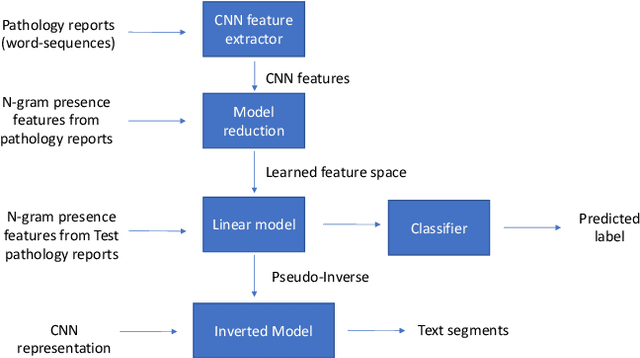

Shallow Convolution Neural Network (CNN) is a time-tested tool for the information extraction from cancer pathology reports. Shallow CNN performs competitively on this task to other deep learning models including BERT, which holds the state-of-the-art for many NLP tasks. The main insight behind this eccentric phenomenon is that the information extraction from cancer pathology reports require only a small number of domain-specific text segments to perform the task, thus making the most of the texts and contexts excessive for the task. Shallow CNN model is well-suited to identify these key short text segments from the labeled training set; however, the identified text segments remain obscure to humans. In this study, we fill this gap by developing a model reduction tool to make a reliable connection between CNN filters and relevant text segments by discarding the spurious connections. We reduce the complexity of shallow CNN representation by approximating it with a linear transformation of n-gram presence representation with a non-negativity and sparsity prior on the transformation weights to obtain an interpretable model. Our approach bridge the gap between the conventionally perceived trade-off boundary between accuracy on the one side and explainability on the other by model reduction.
Automated detection of pitting and stress corrosion cracks in used nuclear fuel dry storage canisters using residual neural networks
Mar 06, 2020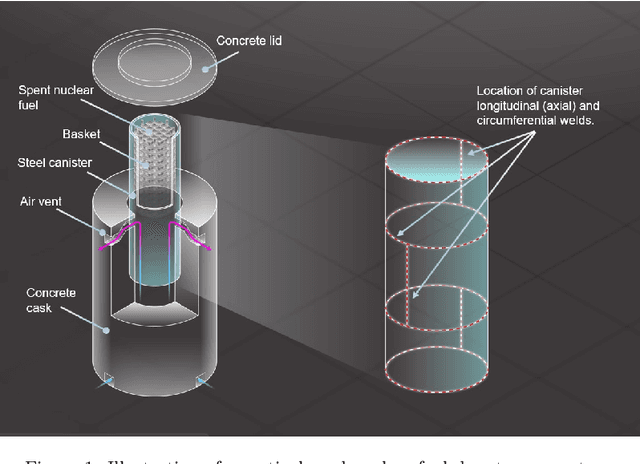
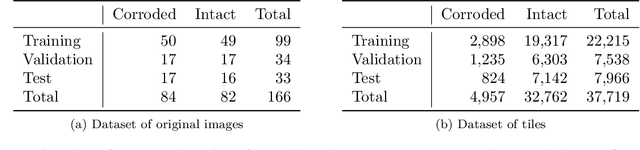

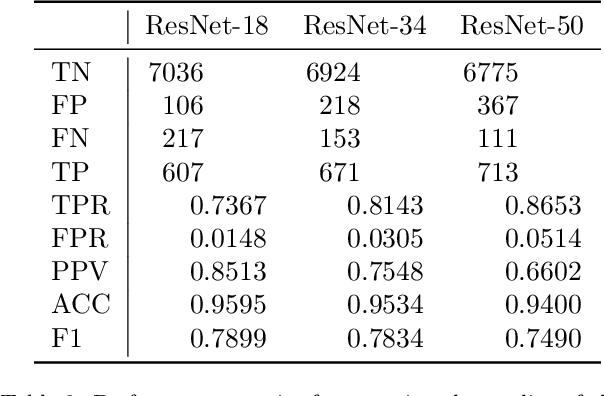
Nondestructive evaluation methods play an important role in ensuring component integrity and safety in many industries. Operator fatigue can play a critical role in the reliability of such methods. This is important for inspecting high value assets or assets with a high consequence of failure, such as aerospace and nuclear components. Recent advances in convolution neural networks can support and automate these inspection efforts. This paper proposes using residual neural networks (ResNets) for real-time detection of pitting and stress corrosion cracking, with a focus on dry storage canisters housing used nuclear fuel. The proposed approach crops nuclear canister images into smaller tiles, trains a ResNet on these tiles, and classifies images as corroded or intact using the per-image count of tiles predicted as corroded by the ResNet. The results demonstrate that such a deep learning approach allows to detect the locus of corrosion cracks via smaller tiles, and at the same time to infer with high accuracy whether an image comes from a corroded canister. Thereby, the proposed approach holds promise to automate and speed up nuclear fuel canister inspections, to minimize inspection costs, and to partially replace human-conducted onsite inspections, thus reducing radiation doses to personnel.
Wide Neural Networks with Bottlenecks are Deep Gaussian Processes
Jan 09, 2020
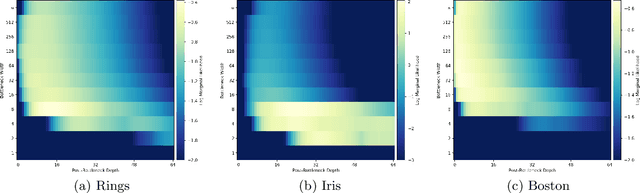
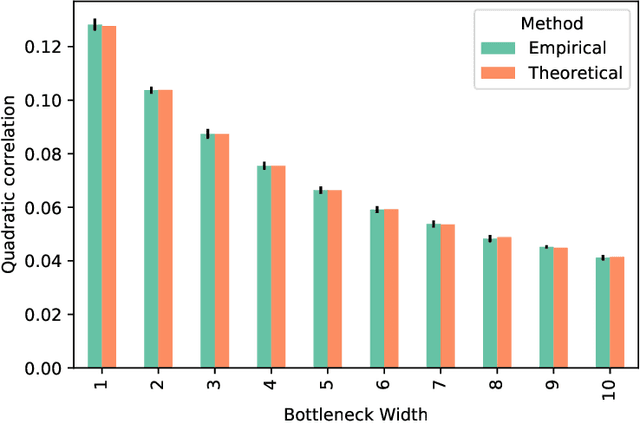
There has recently been much work on the "wide limit" of neural networks, where Bayesian neural networks (BNNs) are shown to converge to a Gaussian process (GP) as all hidden layers are sent to infinite width. However, these results do not apply to architectures that require one or more of the hidden layers to remain narrow. In this paper, we consider the wide limit of BNNs where some hidden layers, called "bottlenecks", are held at finite width. The result is a composition of GPs that we term a "bottleneck neural network Gaussian process" (bottleneck NNGP). Although intuitive, the subtlety of the proof is in showing that the wide limit of a composition of networks is in fact the composition of the limiting GPs. We also analyze theoretically a single-bottleneck NNGP, finding that the bottleneck induces dependence between the outputs of a multi-output network that persists through extreme post-bottleneck depths, and prevents the kernel of the network from losing discriminative power at extreme post-bottleneck depths.
Challenges in Bayesian inference via Markov chain Monte Carlo for neural networks
Nov 14, 2019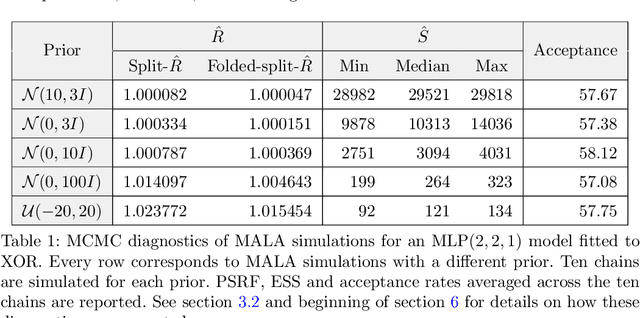

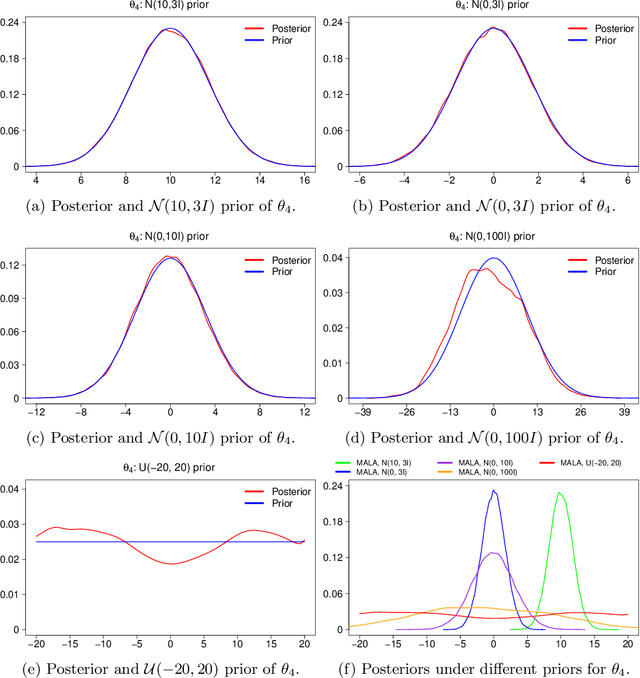
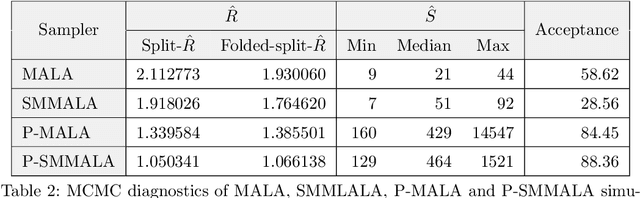
Markov chain Monte Carlo (MCMC) methods and neural networks are instrumental in tackling inferential and prediction problems. However, Bayesian inference based on joint use of MCMC methods and of neural networks is limited. This paper reviews the main challenges posed by neural networks to MCMC developments, including lack of parameter identifiability due to weight symmetries, prior specification effects, and consequently high computational cost and convergence failure. Population and manifold MCMC algorithms are combined to demonstrate these challenges via multilayer perceptron (MLP) examples and to develop case studies for assessing the capacity of approximate inference methods to uncover the posterior covariance of neural network parameters. Some of these challenges, such as high computational cost arising from the application of neural networks to big data and parameter identifiability arising from weight symmetries, stimulate research towards more scalable approximate MCMC methods or towards MCMC methods in reduced parameter spaces.
Polynomial Regression on Riemannian Manifolds
Mar 01, 2012In this paper we develop the theory of parametric polynomial regression in Riemannian manifolds and Lie groups. We show application of Riemannian polynomial regression to shape analysis in Kendall shape space. Results are presented, showing the power of polynomial regression on the classic rat skull growth data of Bookstein as well as the analysis of the shape changes associated with aging of the corpus callosum from the OASIS Alzheimer's study.