 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards the Development of Entropy-Based Anomaly Detection in an Astrophysics Simulation
Sep 05, 2020
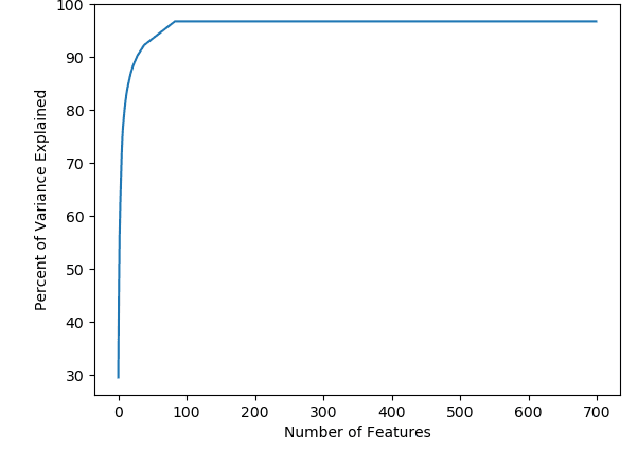
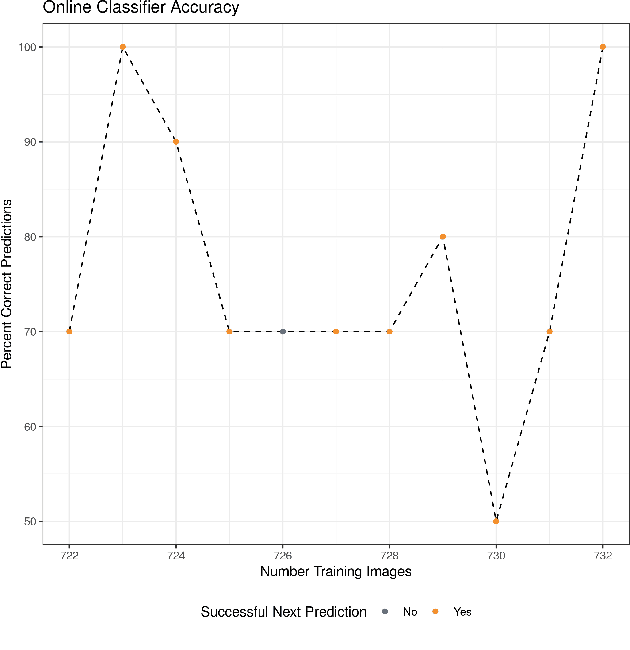

The use of AI and ML for scientific applications is currently a very exciting and dynamic field. Much of this excitement for HPC has focused on ML applications whose analysis and classification generate very large numbers of flops. Others seek to replace scientific simulations with data-driven surrogate models. But another important use case lies in the combination application of ML to improve simulation accuracy. To that end, we present an anomaly problem which arises from a core-collapse supernovae simulation. We discuss strategies and early successes in applying anomaly detection techniques from machine learning to this scientific simulation, as well as current challenges and future possibilities.
Challenges in Bayesian inference via Markov chain Monte Carlo for neural networks
Nov 14, 2019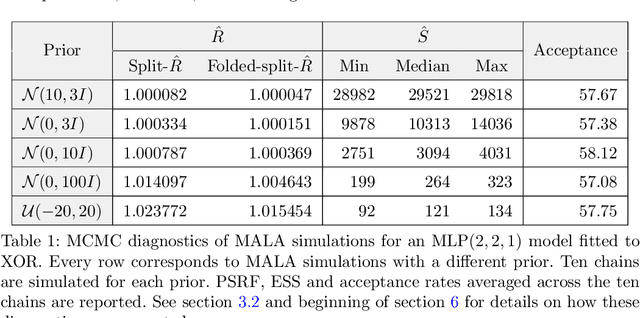

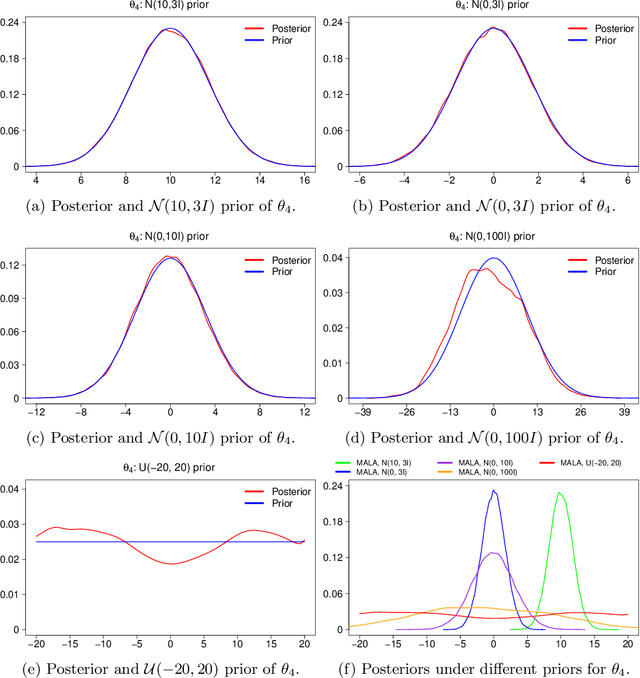
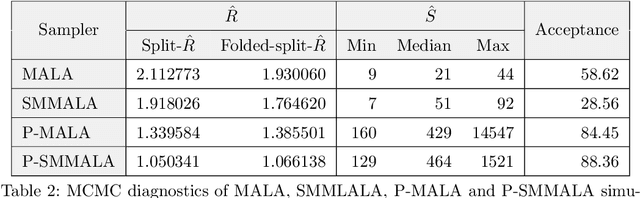
Markov chain Monte Carlo (MCMC) methods and neural networks are instrumental in tackling inferential and prediction problems. However, Bayesian inference based on joint use of MCMC methods and of neural networks is limited. This paper reviews the main challenges posed by neural networks to MCMC developments, including lack of parameter identifiability due to weight symmetries, prior specification effects, and consequently high computational cost and convergence failure. Population and manifold MCMC algorithms are combined to demonstrate these challenges via multilayer perceptron (MLP) examples and to develop case studies for assessing the capacity of approximate inference methods to uncover the posterior covariance of neural network parameters. Some of these challenges, such as high computational cost arising from the application of neural networks to big data and parameter identifiability arising from weight symmetries, stimulate research towards more scalable approximate MCMC methods or towards MCMC methods in reduced parameter spaces.
Exascale Deep Learning for Scientific Inverse Problems
Sep 24, 2019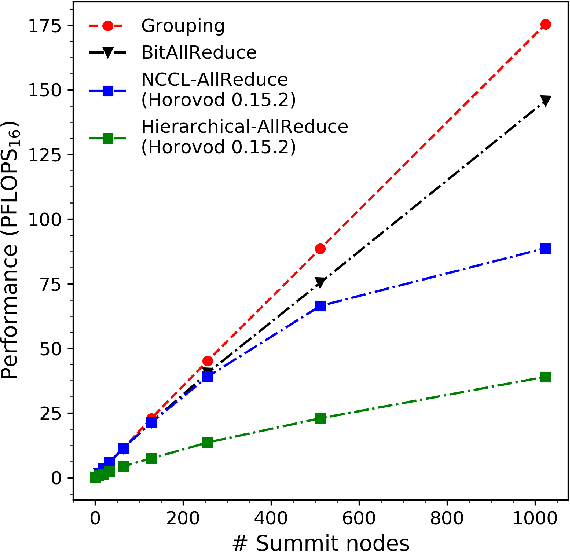


We introduce novel communication strategies in synchronous distributed Deep Learning consisting of decentralized gradient reduction orchestration and computational graph-aware grouping of gradient tensors. These new techniques produce an optimal overlap between computation and communication and result in near-linear scaling (0.93) of distributed training up to 27,600 NVIDIA V100 GPUs on the Summit Supercomputer. We demonstrate our gradient reduction techniques in the context of training a Fully Convolutional Neural Network to approximate the solution of a longstanding scientific inverse problem in materials imaging. The efficient distributed training on a dataset size of 0.5 PB, produces a model capable of an atomically-accurate reconstruction of materials, and in the process reaching a peak performance of 2.15(4) EFLOPS$_{16}$.