 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Cross-Channel Hierarchical Aggregation for Foundation Models
Jun 26, 2025Vision-based scientific foundation models hold significant promise for advancing scientific discovery and innovation. This potential stems from their ability to aggregate images from diverse sources such as varying physical groundings or data acquisition systems and to learn spatio-temporal correlations using transformer architectures. However, tokenizing and aggregating images can be compute-intensive, a challenge not fully addressed by current distributed methods. In this work, we introduce the Distributed Cross-Channel Hierarchical Aggregation (D-CHAG) approach designed for datasets with a large number of channels across image modalities. Our method is compatible with any model-parallel strategy and any type of vision transformer architecture, significantly improving computational efficiency. We evaluated D-CHAG on hyperspectral imaging and weather forecasting tasks. When integrated with tensor parallelism and model sharding, our approach achieved up to a 75% reduction in memory usage and more than doubled sustained throughput on up to 1,024 AMD GPUs on the Frontier Supercomputer.
ORBIT-2: Scaling Exascale Vision Foundation Models for Weather and Climate Downscaling
May 07, 2025



Sparse observations and coarse-resolution climate models limit effective regional decision-making, underscoring the need for robust downscaling. However, existing AI methods struggle with generalization across variables and geographies and are constrained by the quadratic complexity of Vision Transformer (ViT) self-attention. We introduce ORBIT-2, a scalable foundation model for global, hyper-resolution climate downscaling. ORBIT-2 incorporates two key innovations: (1) Residual Slim ViT (Reslim), a lightweight architecture with residual learning and Bayesian regularization for efficient, robust prediction; and (2) TILES, a tile-wise sequence scaling algorithm that reduces self-attention complexity from quadratic to linear, enabling long-sequence processing and massive parallelism. ORBIT-2 scales to 10 billion parameters across 32,768 GPUs, achieving up to 1.8 ExaFLOPS sustained throughput and 92-98% strong scaling efficiency. It supports downscaling to 0.9 km global resolution and processes sequences up to 4.2 billion tokens. On 7 km resolution benchmarks, ORBIT-2 achieves high accuracy with R^2 scores in the range of 0.98 to 0.99 against observation data.
OReole-FM: successes and challenges toward billion-parameter foundation models for high-resolution satellite imagery
Oct 25, 2024While the pretraining of Foundation Models (FMs) for remote sensing (RS) imagery is on the rise, models remain restricted to a few hundred million parameters. Scaling models to billions of parameters has been shown to yield unprecedented benefits including emergent abilities, but requires data scaling and computing resources typically not available outside industry R&D labs. In this work, we pair high-performance computing resources including Frontier supercomputer, America's first exascale system, and high-resolution optical RS data to pretrain billion-scale FMs. Our study assesses performance of different pretrained variants of vision Transformers across image classification, semantic segmentation and object detection benchmarks, which highlight the importance of data scaling for effective model scaling. Moreover, we discuss construction of a novel TIU pretraining dataset, model initialization, with data and pretrained models intended for public release. By discussing technical challenges and details often lacking in the related literature, this work is intended to offer best practices to the geospatial community toward efficient training and benchmarking of larger FMs.
Scalable Artificial Intelligence for Science: Perspectives, Methods and Exemplars
Jun 24, 2024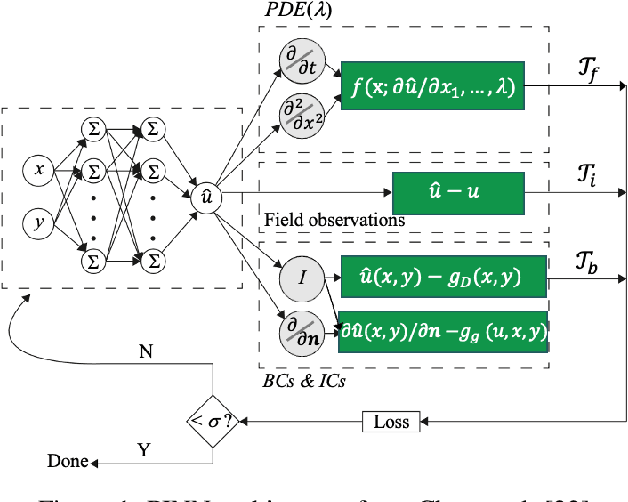
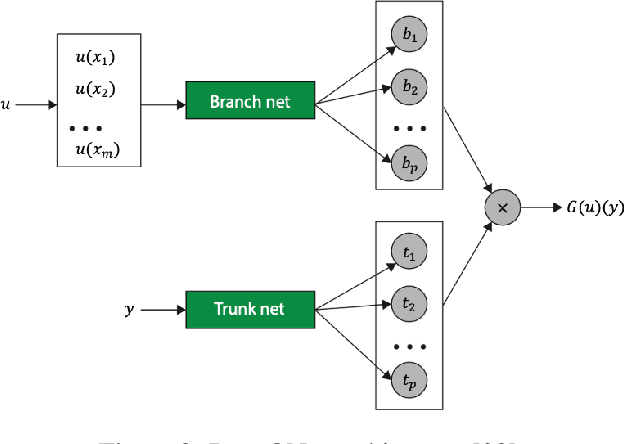
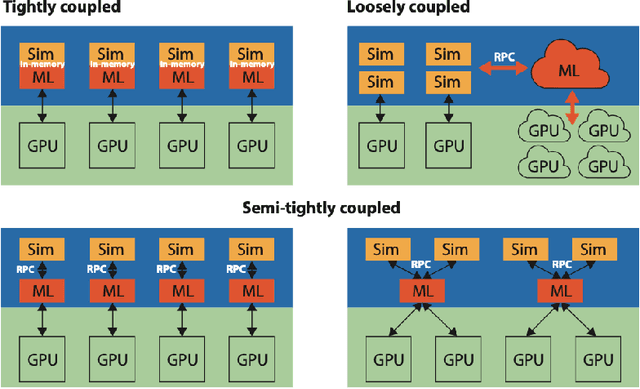
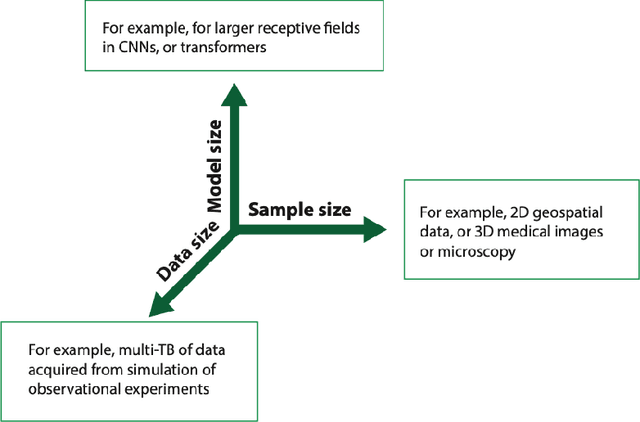
In a post-ChatGPT world, this paper explores the potential of leveraging scalable artificial intelligence for scientific discovery. We propose that scaling up artificial intelligence on high-performance computing platforms is essential to address such complex problems. This perspective focuses on scientific use cases like cognitive simulations, large language models for scientific inquiry, medical image analysis, and physics-informed approaches. The study outlines the methodologies needed to address such challenges at scale on supercomputers or the cloud and provides exemplars of such approaches applied to solve a variety of scientific problems.
ORBIT: Oak Ridge Base Foundation Model for Earth System Predictability
Apr 23, 2024Earth system predictability is challenged by the complexity of environmental dynamics and the multitude of variables involved. Current AI foundation models, although advanced by leveraging large and heterogeneous data, are often constrained by their size and data integration, limiting their effectiveness in addressing the full range of Earth system prediction challenges. To overcome these limitations, we introduce the Oak Ridge Base Foundation Model for Earth System Predictability (ORBIT), an advanced vision-transformer model that scales up to 113 billion parameters using a novel hybrid tensor-data orthogonal parallelism technique. As the largest model of its kind, ORBIT surpasses the current climate AI foundation model size by a thousandfold. Performance scaling tests conducted on the Frontier supercomputer have demonstrated that ORBIT achieves 230 to 707 PFLOPS, with scaling efficiency maintained at 78% to 96% across 24,576 AMD GPUs. These breakthroughs establish new advances in AI-driven climate modeling and demonstrate promise to significantly improve the Earth system predictability.
Pretraining Billion-scale Geospatial Foundational Models on Frontier
Apr 17, 2024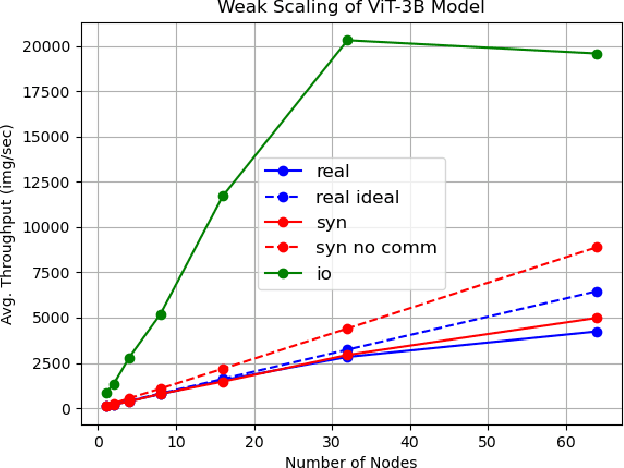
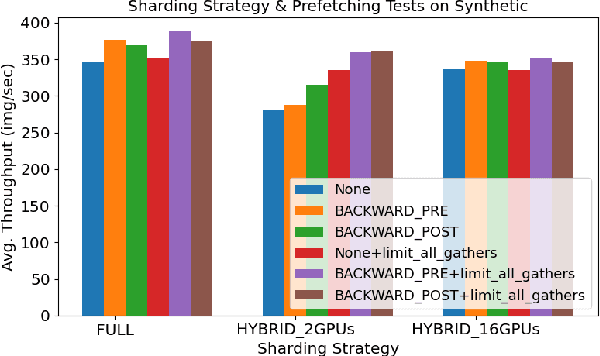
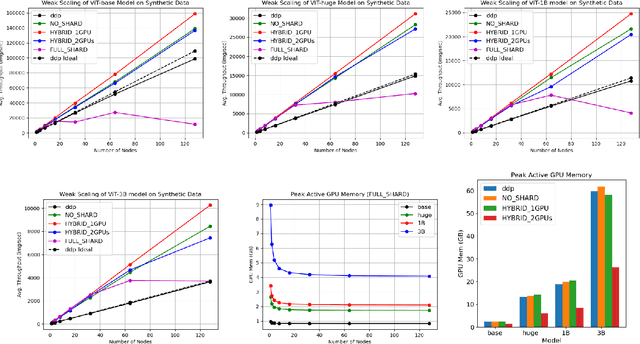
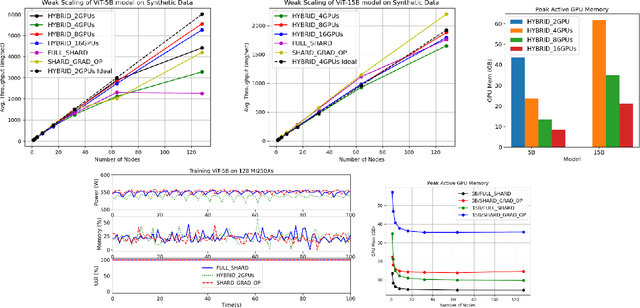
As AI workloads increase in scope, generalization capability becomes challenging for small task-specific models and their demand for large amounts of labeled training samples increases. On the contrary, Foundation Models (FMs) are trained with internet-scale unlabeled data via self-supervised learning and have been shown to adapt to various tasks with minimal fine-tuning. Although large FMs have demonstrated significant impact in natural language processing and computer vision, efforts toward FMs for geospatial applications have been restricted to smaller size models, as pretraining larger models requires very large computing resources equipped with state-of-the-art hardware accelerators. Current satellite constellations collect 100+TBs of data a day, resulting in images that are billions of pixels and multimodal in nature. Such geospatial data poses unique challenges opening up new opportunities to develop FMs. We investigate billion scale FMs and HPC training profiles for geospatial applications by pretraining on publicly available data. We studied from end-to-end the performance and impact in the solution by scaling the model size. Our larger 3B parameter size model achieves up to 30% improvement in top1 scene classification accuracy when comparing a 100M parameter model. Moreover, we detail performance experiments on the Frontier supercomputer, America's first exascale system, where we study different model and data parallel approaches using PyTorch's Fully Sharded Data Parallel library. Specifically, we study variants of the Vision Transformer architecture (ViT), conducting performance analysis for ViT models with size up to 15B parameters. By discussing throughput and performance bottlenecks under different parallelism configurations, we offer insights on how to leverage such leadership-class HPC resources when developing large models for geospatial imagery applications.
Ultra-Long Sequence Distributed Transformer
Nov 08, 2023



Transformer models trained on long sequences often achieve higher accuracy than short sequences. Unfortunately, conventional transformers struggle with long sequence training due to the overwhelming computation and memory requirements. Existing methods for long sequence training offer limited speedup and memory reduction, and may compromise accuracy. This paper presents a novel and efficient distributed training method, the Long Short-Sequence Transformer (LSS Transformer), for training transformer with long sequences. It distributes a long sequence into segments among GPUs, with each GPU computing a partial self-attention for its segment. Then, it uses a fused communication and a novel double gradient averaging technique to avoid the need to aggregate partial self-attention and minimize communication overhead. We evaluated the performance between LSS Transformer and the state-of-the-art Nvidia sequence parallelism on a Wikipedia enwik8 dataset. Results show that our proposed method lead to 5.6x faster and 10.2x more memory-efficient implementation compared to state-of-the-art sequence parallelism on 144 Nvidia V100 GPUs. Moreover, our algorithm scales to an extreme sequence length of 50,112 at 3,456 GPUs, achieving 161% super-linear parallel efficiency and a throughput of 32 petaflops.
Image Gradient Decomposition for Parallel and Memory-Efficient Ptychographic Reconstruction
May 12, 2022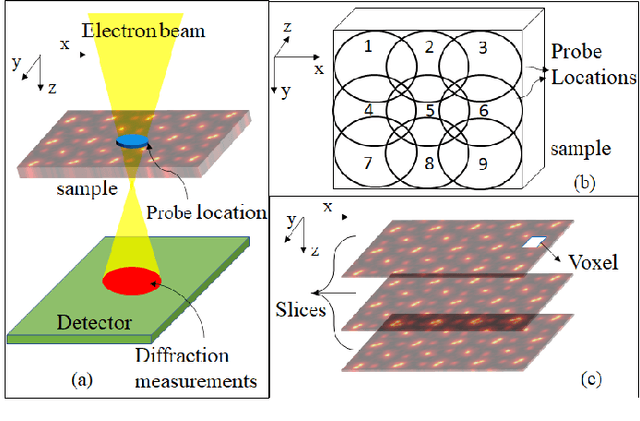
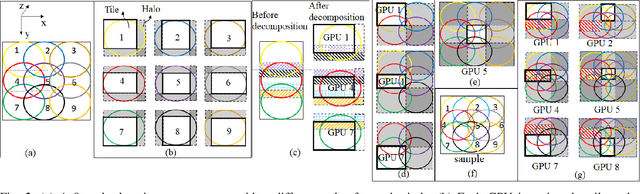
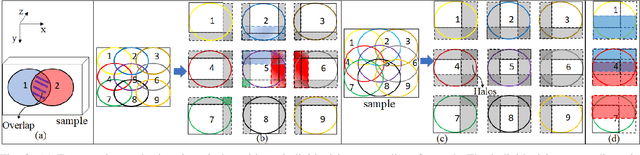
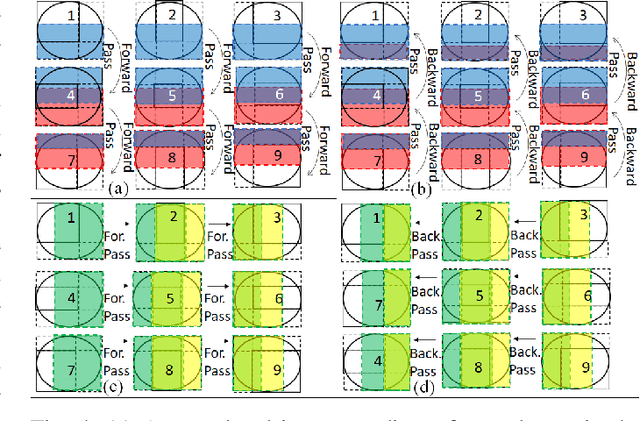
Ptychography is a popular microscopic imaging modality for many scientific discoveries and sets the record for highest image resolution. Unfortunately, the high image resolution for ptychographic reconstruction requires significant amount of memory and computations, forcing many applications to compromise their image resolution in exchange for a smaller memory footprint and a shorter reconstruction time. In this paper, we propose a novel image gradient decomposition method that significantly reduces the memory footprint for ptychographic reconstruction by tessellating image gradients and diffraction measurements into tiles. In addition, we propose a parallel image gradient decomposition method that enables asynchronous point-to-point communications and parallel pipelining with minimal overhead on a large number of GPUs. Our experiments on a Titanate material dataset (PbTiO3) with 16632 probe locations show that our Gradient Decomposition algorithm reduces memory footprint by 51 times. In addition, it achieves time-to-solution within 2.2 minutes by scaling to 4158 GPUs with a super-linear speedup at 364% efficiency. This performance is 2.7 times more memory efficient, 9 times more scalable and 86 times faster than the state-of-the-art algorithm.
MLPerf HPC: A Holistic Benchmark Suite for Scientific Machine Learning on HPC Systems
Oct 26, 2021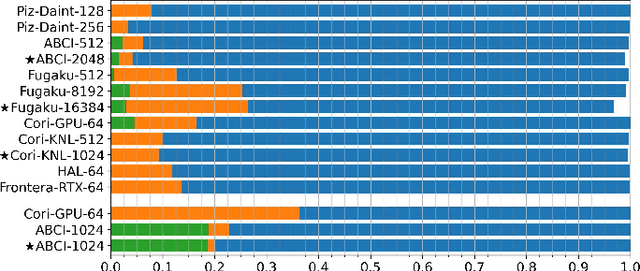
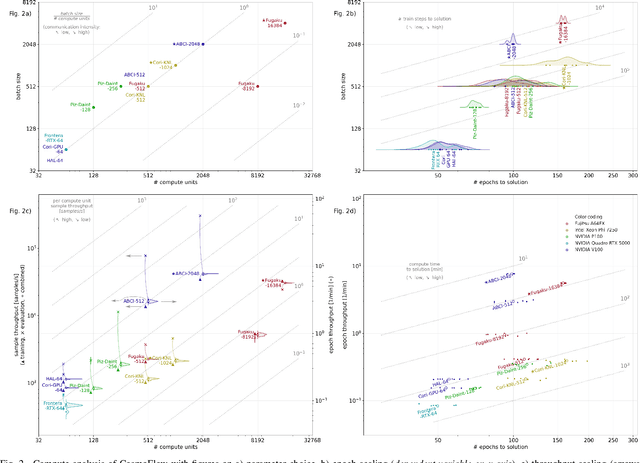
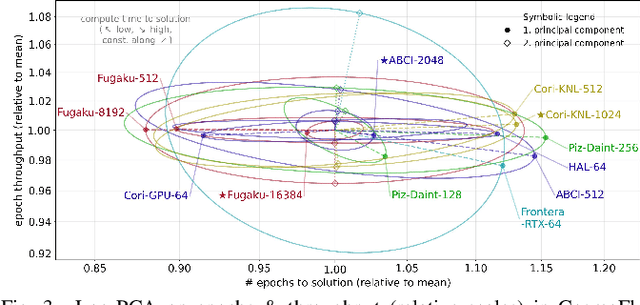
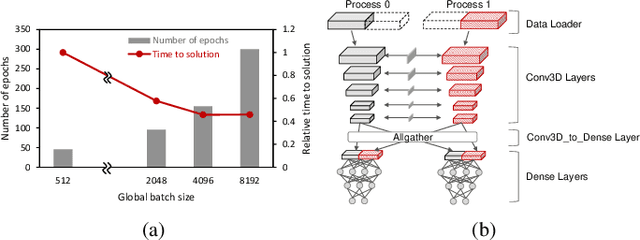
Scientific communities are increasingly adopting machine learning and deep learning models in their applications to accelerate scientific insights. High performance computing systems are pushing the frontiers of performance with a rich diversity of hardware resources and massive scale-out capabilities. There is a critical need to understand fair and effective benchmarking of machine learning applications that are representative of real-world scientific use cases. MLPerf is a community-driven standard to benchmark machine learning workloads, focusing on end-to-end performance metrics. In this paper, we introduce MLPerf HPC, a benchmark suite of large-scale scientific machine learning training applications driven by the MLCommons Association. We present the results from the first submission round, including a diverse set of some of the world's largest HPC systems. We develop a systematic framework for their joint analysis and compare them in terms of data staging, algorithmic convergence, and compute performance. As a result, we gain a quantitative understanding of optimizations on different subsystems such as staging and on-node loading of data, compute-unit utilization, and communication scheduling, enabling overall $>10 \times$ (end-to-end) performance improvements through system scaling. Notably, our analysis shows a scale-dependent interplay between the dataset size, a system's memory hierarchy, and training convergence that underlines the importance of near-compute storage. To overcome the data-parallel scalability challenge at large batch sizes, we discuss specific learning techniques and hybrid data-and-model parallelism that are effective on large systems. We conclude by characterizing each benchmark with respect to low-level memory, I/O, and network behavior to parameterize extended roofline performance models in future rounds.
Track Seeding and Labelling with Embedded-space Graph Neural Networks
Jun 30, 2020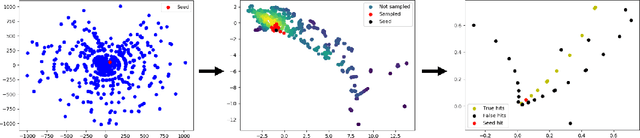
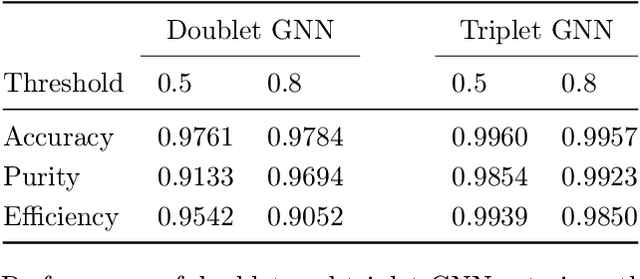

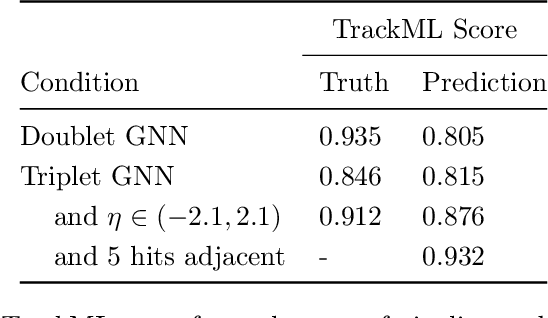
To address the unprecedented scale of HL-LHC data, the Exa.TrkX project is investigating a variety of machine learning approaches to particle track reconstruction. The most promising of these solutions, graph neural networks (GNN), process the event as a graph that connects track measurements (detector hits corresponding to nodes) with candidate line segments between the hits (corresponding to edges). Detector information can be associated with nodes and edges, enabling a GNN to propagate the embedded parameters around the graph and predict node-, edge- and graph-level observables. Previously, message-passing GNNs have shown success in predicting doublet likelihood, and we here report updates on the state-of-the-art architectures for this task. In addition, the Exa.TrkX project has investigated innovations in both graph construction, and embedded representations, in an effort to achieve fully learned end-to-end track finding. Hence, we present a suite of extensions to the original model, with encouraging results for hitgraph classification. In addition, we explore increased performance by constructing graphs from learned representations which contain non-linear metric structure, allowing for efficient clustering and neighborhood queries of data points. We demonstrate how this framework fits in with both traditional clustering pipelines, and GNN approaches. The embedded graphs feed into high-accuracy doublet and triplet classifiers, or can be used as an end-to-end track classifier by clustering in an embedded space. A set of post-processing methods improve performance with knowledge of the detector physics. Finally, we present numerical results on the TrackML particle tracking challenge dataset, where our framework shows favorable results in both seeding and track finding.