 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimLBR: Learning to Detect Fake Images by Learning to Detect Real Images
Feb 23, 2026The rapid advancement of generative models has made the detection of AI-generated images a critical challenge for both research and society. Recent works have shown that most state-of-the-art fake image detection methods overfit to their training data and catastrophically fail when evaluated on curated hard test sets with strong distribution shifts. In this work, we argue that it is more principled to learn a tight decision boundary around the real image distribution and treat the fake category as a sink class. To this end, we propose SimLBR, a simple and efficient framework for fake image detection using Latent Blending Regularization (LBR). Our method significantly improves cross-generator generalization, achieving up to +24.85\% accuracy and +69.62\% recall on the challenging Chameleon benchmark. SimLBR is also highly efficient, training orders of magnitude faster than existing approaches. Furthermore, we emphasize the need for reliability-oriented evaluation in fake image detection, introducing risk-adjusted metrics and worst-case estimates to better assess model robustness. All code and models will be released on HuggingFace and GitHub.
Pretraining Billion-scale Geospatial Foundational Models on Frontier
Apr 17, 2024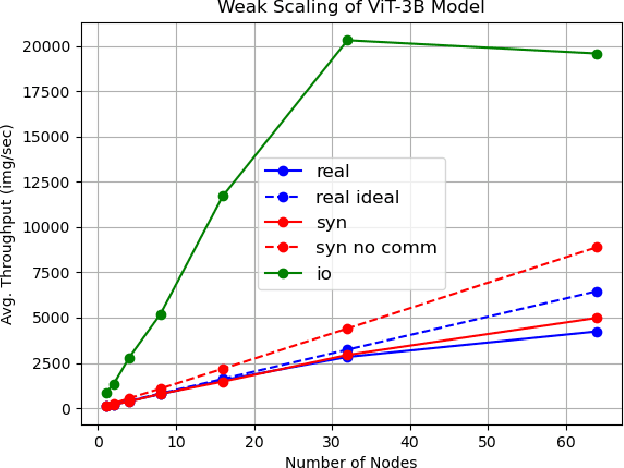
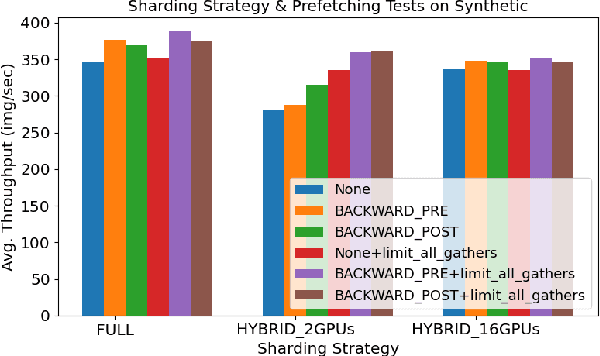
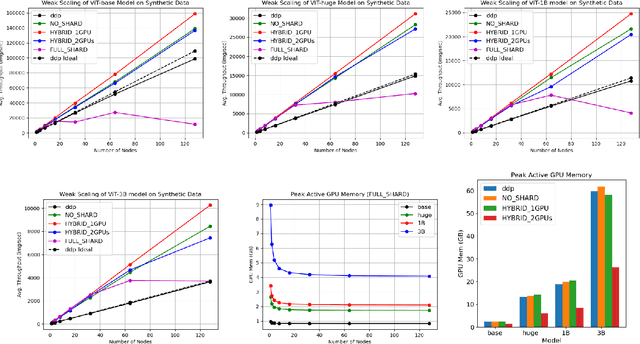
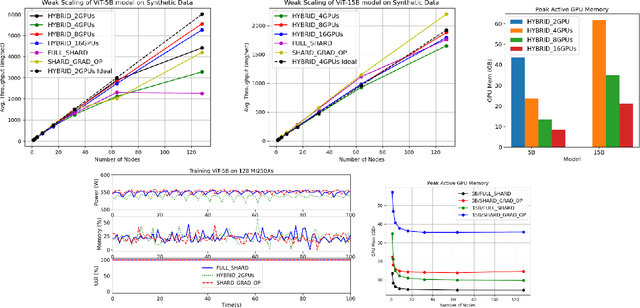
As AI workloads increase in scope, generalization capability becomes challenging for small task-specific models and their demand for large amounts of labeled training samples increases. On the contrary, Foundation Models (FMs) are trained with internet-scale unlabeled data via self-supervised learning and have been shown to adapt to various tasks with minimal fine-tuning. Although large FMs have demonstrated significant impact in natural language processing and computer vision, efforts toward FMs for geospatial applications have been restricted to smaller size models, as pretraining larger models requires very large computing resources equipped with state-of-the-art hardware accelerators. Current satellite constellations collect 100+TBs of data a day, resulting in images that are billions of pixels and multimodal in nature. Such geospatial data poses unique challenges opening up new opportunities to develop FMs. We investigate billion scale FMs and HPC training profiles for geospatial applications by pretraining on publicly available data. We studied from end-to-end the performance and impact in the solution by scaling the model size. Our larger 3B parameter size model achieves up to 30% improvement in top1 scene classification accuracy when comparing a 100M parameter model. Moreover, we detail performance experiments on the Frontier supercomputer, America's first exascale system, where we study different model and data parallel approaches using PyTorch's Fully Sharded Data Parallel library. Specifically, we study variants of the Vision Transformer architecture (ViT), conducting performance analysis for ViT models with size up to 15B parameters. By discussing throughput and performance bottlenecks under different parallelism configurations, we offer insights on how to leverage such leadership-class HPC resources when developing large models for geospatial imagery applications.