 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciTrust 2.0: A Comprehensive Framework for Evaluating Trustworthiness of Large Language Models in Scientific Applications
Oct 29, 2025Large language models (LLMs) have demonstrated transformative potential in scientific research, yet their deployment in high-stakes contexts raises significant trustworthiness concerns. Here, we introduce SciTrust 2.0, a comprehensive framework for evaluating LLM trustworthiness in scientific applications across four dimensions: truthfulness, adversarial robustness, scientific safety, and scientific ethics. Our framework incorporates novel, open-ended truthfulness benchmarks developed through a verified reflection-tuning pipeline and expert validation, alongside a novel ethics benchmark for scientific research contexts covering eight subcategories including dual-use research and bias. We evaluated seven prominent LLMs, including four science-specialized models and three general-purpose industry models, using multiple evaluation metrics including accuracy, semantic similarity measures, and LLM-based scoring. General-purpose industry models overall outperformed science-specialized models across each trustworthiness dimension, with GPT-o4-mini demonstrating superior performance in truthfulness assessments and adversarial robustness. Science-specialized models showed significant deficiencies in logical and ethical reasoning capabilities, along with concerning vulnerabilities in safety evaluations, particularly in high-risk domains such as biosecurity and chemical weapons. By open-sourcing our framework, we provide a foundation for developing more trustworthy AI systems and advancing research on model safety and ethics in scientific contexts.
HPC Digital Twins for Evaluating Scheduling Policies, Incentive Structures and their Impact on Power and Cooling
Aug 28, 2025Schedulers are critical for optimal resource utilization in high-performance computing. Traditional methods to evaluate schedulers are limited to post-deployment analysis, or simulators, which do not model associated infrastructure. In this work, we present the first-of-its-kind integration of scheduling and digital twins in HPC. This enables what-if studies to understand the impact of parameter configurations and scheduling decisions on the physical assets, even before deployment, or regarching changes not easily realizable in production. We (1) provide the first digital twin framework extended with scheduling capabilities, (2) integrate various top-tier HPC systems given their publicly available datasets, (3) implement extensions to integrate external scheduling simulators. Finally, we show how to (4) implement and evaluate incentive structures, as-well-as (5) evaluate machine learning based scheduling, in such novel digital-twin based meta-framework to prototype scheduling. Our work enables what-if scenarios of HPC systems to evaluate sustainability, and the impact on the simulated system.
Decoding Memories: An Efficient Pipeline for Self-Consistency Hallucination Detection
Aug 28, 2025Large language models (LLMs) have demonstrated impressive performance in both research and real-world applications, but they still struggle with hallucination. Existing hallucination detection methods often perform poorly on sentence-level generation or rely heavily on domain-specific knowledge. While self-consistency approaches help address these limitations, they incur high computational costs due to repeated generation. In this paper, we conduct the first study on identifying redundancy in self-consistency methods, manifested as shared prefix tokens across generations, and observe that non-exact-answer tokens contribute minimally to the semantic content. Based on these insights, we propose a novel Decoding Memory Pipeline (DMP) that accelerates generation through selective inference and annealed decoding. Being orthogonal to the model, dataset, decoding strategy, and self-consistency baseline, our DMP consistently improves the efficiency of multi-response generation and holds promise for extension to alignment and reasoning tasks. Extensive experiments show that our method achieves up to a 3x speedup without sacrificing AUROC performance.
Intelligent Sampling of Extreme-Scale Turbulence Datasets for Accurate and Efficient Spatiotemporal Model Training
Aug 05, 2025With the end of Moore's law and Dennard scaling, efficient training increasingly requires rethinking data volume. Can we train better models with significantly less data via intelligent subsampling? To explore this, we develop SICKLE, a sparse intelligent curation framework for efficient learning, featuring a novel maximum entropy (MaxEnt) sampling approach, scalable training, and energy benchmarking. We compare MaxEnt with random and phase-space sampling on large direct numerical simulation (DNS) datasets of turbulence. Evaluating SICKLE at scale on Frontier, we show that subsampling as a preprocessing step can improve model accuracy and substantially lower energy consumption, with reductions of up to 38x observed in certain cases.
Pixel-Resolved Long-Context Learning for Turbulence at Exascale: Resolving Small-scale Eddies Toward the Viscous Limit
Jul 22, 2025Turbulence plays a crucial role in multiphysics applications, including aerodynamics, fusion, and combustion. Accurately capturing turbulence's multiscale characteristics is essential for reliable predictions of multiphysics interactions, but remains a grand challenge even for exascale supercomputers and advanced deep learning models. The extreme-resolution data required to represent turbulence, ranging from billions to trillions of grid points, pose prohibitive computational costs for models based on architectures like vision transformers. To address this challenge, we introduce a multiscale hierarchical Turbulence Transformer that reduces sequence length from billions to a few millions and a novel RingX sequence parallelism approach that enables scalable long-context learning. We perform scaling and science runs on the Frontier supercomputer. Our approach demonstrates excellent performance up to 1.1 EFLOPS on 32,768 AMD GPUs, with a scaling efficiency of 94%. To our knowledge, this is the first AI model for turbulence that can capture small-scale eddies down to the dissipative range.
Distributed Cross-Channel Hierarchical Aggregation for Foundation Models
Jun 26, 2025Vision-based scientific foundation models hold significant promise for advancing scientific discovery and innovation. This potential stems from their ability to aggregate images from diverse sources such as varying physical groundings or data acquisition systems and to learn spatio-temporal correlations using transformer architectures. However, tokenizing and aggregating images can be compute-intensive, a challenge not fully addressed by current distributed methods. In this work, we introduce the Distributed Cross-Channel Hierarchical Aggregation (D-CHAG) approach designed for datasets with a large number of channels across image modalities. Our method is compatible with any model-parallel strategy and any type of vision transformer architecture, significantly improving computational efficiency. We evaluated D-CHAG on hyperspectral imaging and weather forecasting tasks. When integrated with tensor parallelism and model sharding, our approach achieved up to a 75% reduction in memory usage and more than doubled sustained throughput on up to 1,024 AMD GPUs on the Frontier Supercomputer.
Analyzing 16,193 LLM Papers for Fun and Profits
Apr 15, 2025Large Language Models (LLMs) are reshaping the landscape of computer science research, driving significant shifts in research priorities across diverse conferences and fields. This study provides a comprehensive analysis of the publication trend of LLM-related papers in 77 top-tier computer science conferences over the past six years (2019-2024). We approach this analysis from four distinct perspectives: (1) We investigate how LLM research is driving topic shifts within major conferences. (2) We adopt a topic modeling approach to identify various areas of LLM-related topic growth and reveal the topics of concern at different conferences. (3) We explore distinct contribution patterns of academic and industrial institutions. (4) We study the influence of national origins on LLM development trajectories. Synthesizing the findings from these diverse analytical angles, we derive ten key insights that illuminate the dynamics and evolution of the LLM research ecosystem.
ProTransformer: Robustify Transformers via Plug-and-Play Paradigm
Oct 30, 2024



Transformer-based architectures have dominated various areas of machine learning in recent years. In this paper, we introduce a novel robust attention mechanism designed to enhance the resilience of transformer-based architectures. Crucially, this technique can be integrated into existing transformers as a plug-and-play layer, improving their robustness without the need for additional training or fine-tuning. Through comprehensive experiments and ablation studies, we demonstrate that our ProTransformer significantly enhances the robustness of transformer models across a variety of prediction tasks, attack mechanisms, backbone architectures, and data domains. Notably, without further fine-tuning, the ProTransformer consistently improves the performance of vanilla transformers by 19.5%, 28.3%, 16.1%, and 11.4% for BERT, ALBERT, DistilBERT, and RoBERTa, respectively, under the classical TextFooler attack. Furthermore, ProTransformer shows promising resilience in large language models (LLMs) against prompting-based attacks, improving the performance of T5 and LLaMA by 24.8% and 17.8%, respectively, and enhancing Vicuna by an average of 10.4% against the Jailbreaking attack. Beyond the language domain, ProTransformer also demonstrates outstanding robustness in both vision and graph domains.
A Digital Twin Framework for Liquid-cooled Supercomputers as Demonstrated at Exascale
Oct 07, 2024We present ExaDigiT, an open-source framework for developing comprehensive digital twins of liquid-cooled supercomputers. It integrates three main modules: (1) a resource allocator and power simulator, (2) a transient thermo-fluidic cooling model, and (3) an augmented reality model of the supercomputer and central energy plant. The framework enables the study of "what-if" scenarios, system optimizations, and virtual prototyping of future systems. Using Frontier as a case study, we demonstrate the framework's capabilities by replaying six months of system telemetry for systematic verification and validation. Such a comprehensive analysis of a liquid-cooled exascale supercomputer is the first of its kind. ExaDigiT elucidates complex transient cooling system dynamics, runs synthetic or real workloads, and predicts energy losses due to rectification and voltage conversion. Throughout our paper, we present lessons learned to benefit HPC practitioners developing similar digital twins. We envision the digital twin will be a key enabler for sustainable, energy-efficient supercomputing.
Scalable Artificial Intelligence for Science: Perspectives, Methods and Exemplars
Jun 24, 2024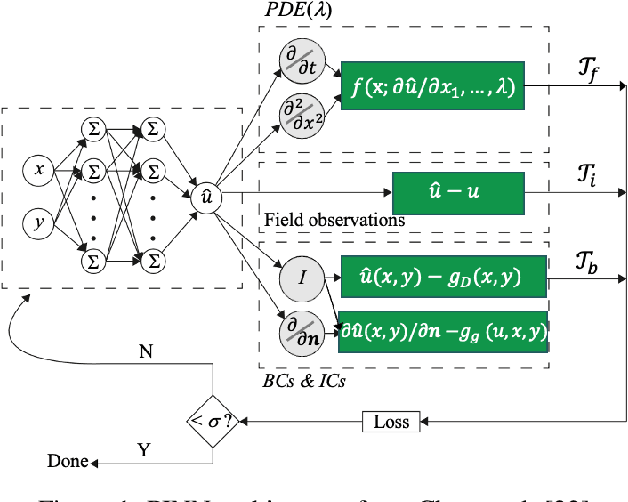
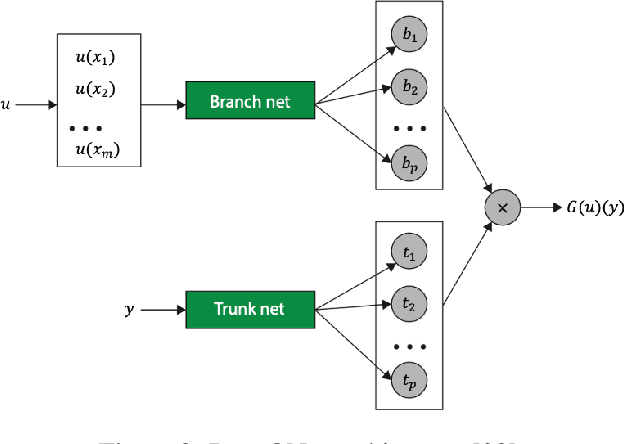
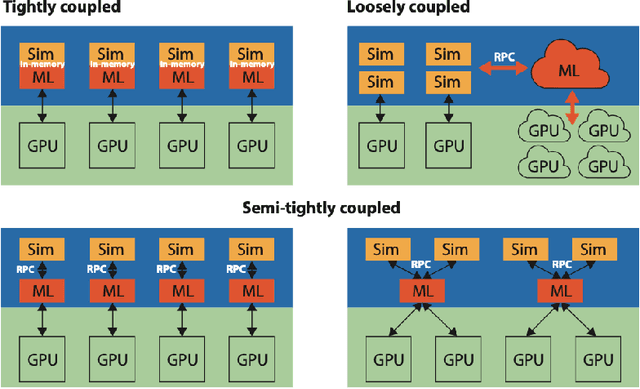
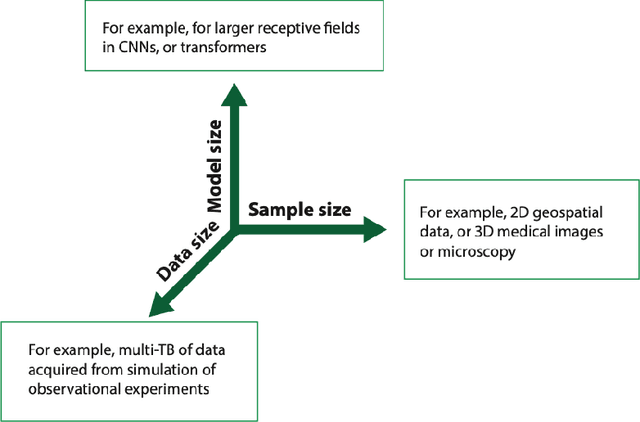
In a post-ChatGPT world, this paper explores the potential of leveraging scalable artificial intelligence for scientific discovery. We propose that scaling up artificial intelligence on high-performance computing platforms is essential to address such complex problems. This perspective focuses on scientific use cases like cognitive simulations, large language models for scientific inquiry, medical image analysis, and physics-informed approaches. The study outlines the methodologies needed to address such challenges at scale on supercomputers or the cloud and provides exemplars of such approaches applied to solve a variety of scientific problems.