 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Iterative Adversarial Attacks with Limited Computation Budget
Oct 30, 2025This work tackles a critical challenge in AI safety research under limited compute: given a fixed computation budget, how can one maximize the strength of iterative adversarial attacks? Coarsely reducing the number of attack iterations lowers cost but substantially weakens effectiveness. To fulfill the attainable attack efficacy within a constrained budget, we propose a fine-grained control mechanism that selectively recomputes layer activations across both iteration-wise and layer-wise levels. Extensive experiments show that our method consistently outperforms existing baselines at equal cost. Moreover, when integrated into adversarial training, it attains comparable performance with only 30% of the original budget.
Boosting Adversarial Robustness and Generalization with Structural Prior
Feb 02, 2025



This work investigates a novel approach to boost adversarial robustness and generalization by incorporating structural prior into the design of deep learning models. Specifically, our study surprisingly reveals that existing dictionary learning-inspired convolutional neural networks (CNNs) provide a false sense of security against adversarial attacks. To address this, we propose Elastic Dictionary Learning Networks (EDLNets), a novel ResNet architecture that significantly enhances adversarial robustness and generalization. This novel and effective approach is supported by a theoretical robustness analysis using influence functions. Moreover, extensive and reliable experiments demonstrate consistent and significant performance improvement on open robustness leaderboards such as RobustBench, surpassing state-of-the-art baselines. To the best of our knowledge, this is the first work to discover and validate that structural prior can reliably enhance deep learning robustness under strong adaptive attacks, unveiling a promising direction for future research.
Post-hoc Interpretability Illumination for Scientific Interaction Discovery
Dec 20, 2024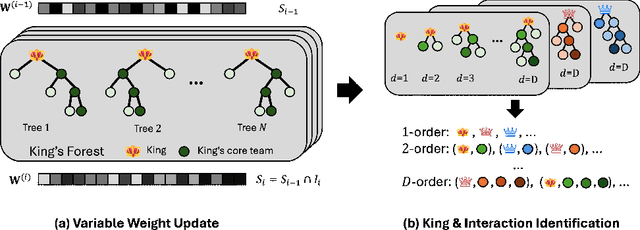

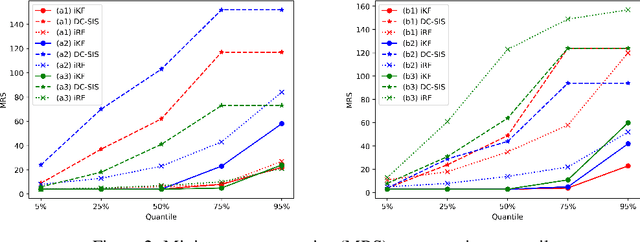
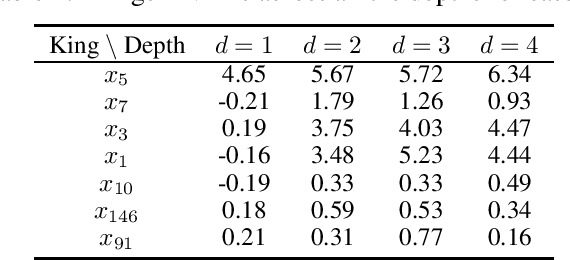
Model interpretability and explainability have garnered substantial attention in recent years, particularly in decision-making applications. However, existing interpretability tools often fall short in delivering satisfactory performance due to limited capabilities or efficiency issues. To address these challenges, we propose a novel post-hoc method: Iterative Kings' Forests (iKF), designed to uncover complex multi-order interactions among variables. iKF iteratively selects the next most important variable, the "King", and constructs King's Forests by placing it at the root node of each tree to identify variables that interact with the "King". It then generates ranked short lists of important variables and interactions of varying orders. Additionally, iKF provides inference metrics to analyze the patterns of the selected interactions and classify them into one of three interaction types: Accompanied Interaction, Synergistic Interaction, and Hierarchical Interaction. Extensive experiments demonstrate the strong interpretive power of our proposed iKF, highlighting its great potential for explainable modeling and scientific discovery across diverse scientific fields.
Certified Robustness for Deep Equilibrium Models via Serialized Random Smoothing
Nov 01, 2024



Implicit models such as Deep Equilibrium Models (DEQs) have emerged as promising alternative approaches for building deep neural networks. Their certified robustness has gained increasing research attention due to security concerns. Existing certified defenses for DEQs employing deterministic certification methods such as interval bound propagation and Lipschitz-bounds can not certify on large-scale datasets. Besides, they are also restricted to specific forms of DEQs. In this paper, we provide the first randomized smoothing certified defense for DEQs to solve these limitations. Our study reveals that simply applying randomized smoothing to certify DEQs provides certified robustness generalized to large-scale datasets but incurs extremely expensive computation costs. To reduce computational redundancy, we propose a novel Serialized Randomized Smoothing (SRS) approach that leverages historical information. Additionally, we derive a new certified radius estimation for SRS to theoretically ensure the correctness of our algorithm. Extensive experiments and ablation studies on image recognition demonstrate that our algorithm can significantly accelerate the certification of DEQs by up to 7x almost without sacrificing the certified accuracy. Our code is available at https://github.com/WeizhiGao/Serialized-Randomized-Smoothing.
ProTransformer: Robustify Transformers via Plug-and-Play Paradigm
Oct 30, 2024



Transformer-based architectures have dominated various areas of machine learning in recent years. In this paper, we introduce a novel robust attention mechanism designed to enhance the resilience of transformer-based architectures. Crucially, this technique can be integrated into existing transformers as a plug-and-play layer, improving their robustness without the need for additional training or fine-tuning. Through comprehensive experiments and ablation studies, we demonstrate that our ProTransformer significantly enhances the robustness of transformer models across a variety of prediction tasks, attack mechanisms, backbone architectures, and data domains. Notably, without further fine-tuning, the ProTransformer consistently improves the performance of vanilla transformers by 19.5%, 28.3%, 16.1%, and 11.4% for BERT, ALBERT, DistilBERT, and RoBERTa, respectively, under the classical TextFooler attack. Furthermore, ProTransformer shows promising resilience in large language models (LLMs) against prompting-based attacks, improving the performance of T5 and LLaMA by 24.8% and 17.8%, respectively, and enhancing Vicuna by an average of 10.4% against the Jailbreaking attack. Beyond the language domain, ProTransformer also demonstrates outstanding robustness in both vision and graph domains.
Robustness Reprogramming for Representation Learning
Oct 06, 2024
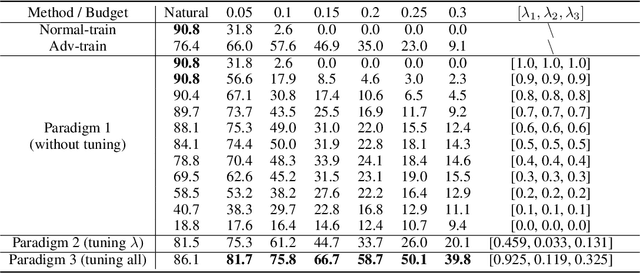
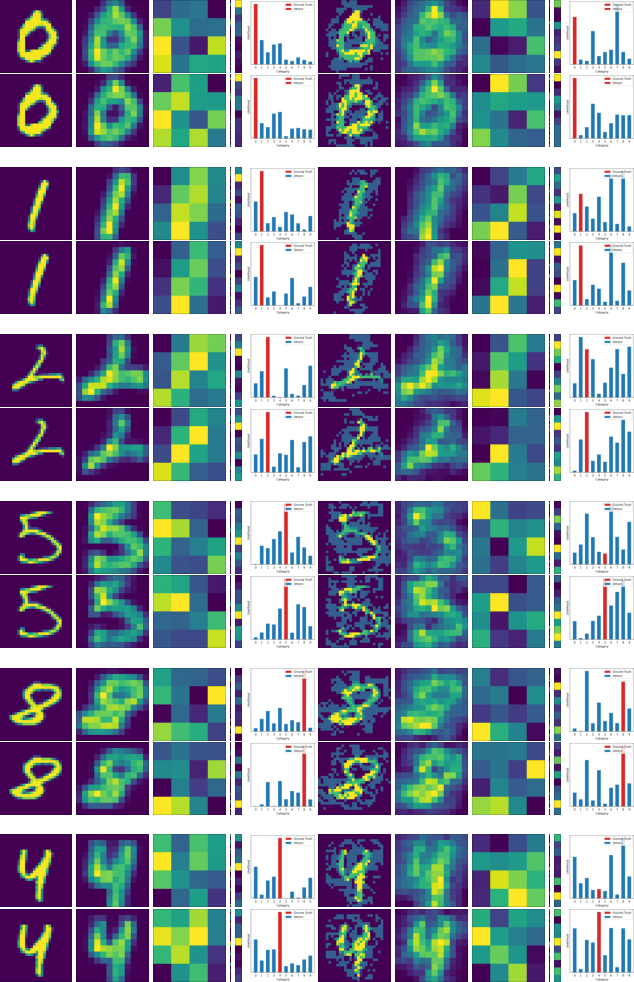
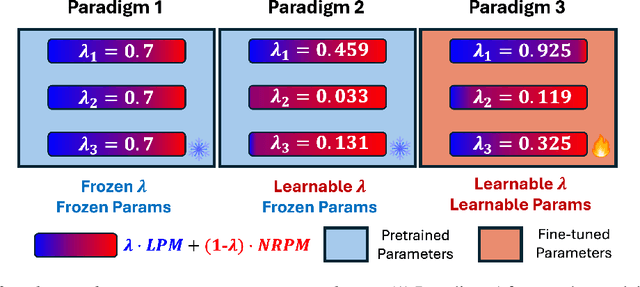
This work tackles an intriguing and fundamental open challenge in representation learning: Given a well-trained deep learning model, can it be reprogrammed to enhance its robustness against adversarial or noisy input perturbations without altering its parameters? To explore this, we revisit the core feature transformation mechanism in representation learning and propose a novel non-linear robust pattern matching technique as a robust alternative. Furthermore, we introduce three model reprogramming paradigms to offer flexible control of robustness under different efficiency requirements. Comprehensive experiments and ablation studies across diverse learning models ranging from basic linear model and MLPs to shallow and modern deep ConvNets demonstrate the effectiveness of our approaches. This work not only opens a promising and orthogonal direction for improving adversarial defenses in deep learning beyond existing methods but also provides new insights into designing more resilient AI systems with robust statistics.
HLogformer: A Hierarchical Transformer for Representing Log Data
Aug 29, 2024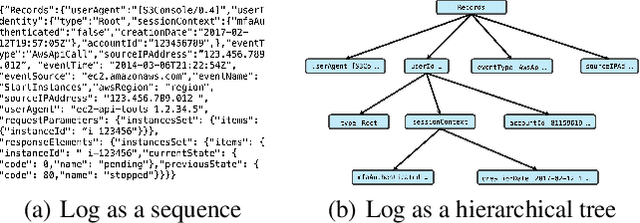
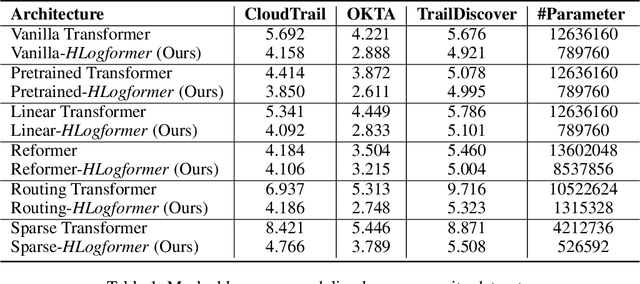
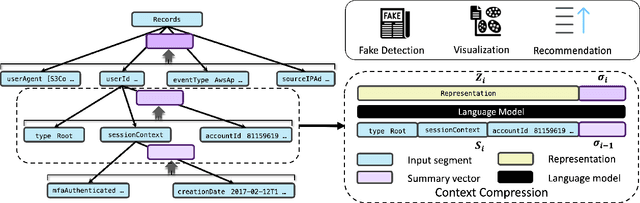
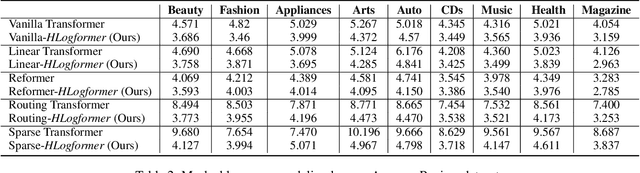
Transformers have gained widespread acclaim for their versatility in handling diverse data structures, yet their application to log data remains underexplored. Log data, characterized by its hierarchical, dictionary-like structure, poses unique challenges when processed using conventional transformer models. Traditional methods often rely on manually crafted templates for parsing logs, a process that is labor-intensive and lacks generalizability. Additionally, the linear treatment of log sequences by standard transformers neglects the rich, nested relationships within log entries, leading to suboptimal representations and excessive memory usage. To address these issues, we introduce HLogformer, a novel hierarchical transformer framework specifically designed for log data. HLogformer leverages the hierarchical structure of log entries to significantly reduce memory costs and enhance representation learning. Unlike traditional models that treat log data as flat sequences, our framework processes log entries in a manner that respects their inherent hierarchical organization. This approach ensures comprehensive encoding of both fine-grained details and broader contextual relationships. Our contributions are threefold: First, HLogformer is the first framework to design a dynamic hierarchical transformer tailored for dictionary-like log data. Second, it dramatically reduces memory costs associated with processing extensive log sequences. Third, comprehensive experiments demonstrate that HLogformer more effectively encodes hierarchical contextual information, proving to be highly effective for downstream tasks such as synthetic anomaly detection and product recommendation.
Equivariant Spatio-Temporal Attentive Graph Networks to Simulate Physical Dynamics
May 21, 2024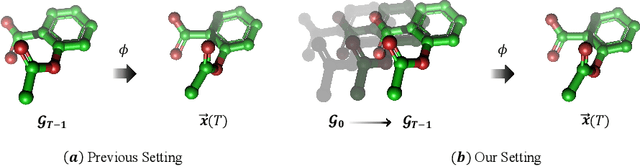
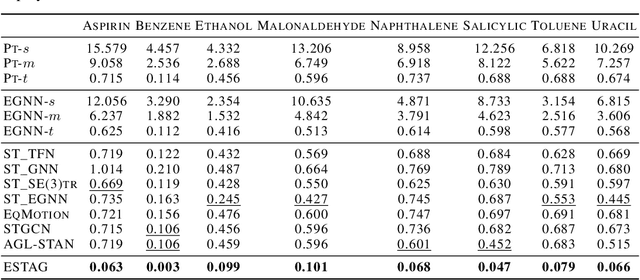
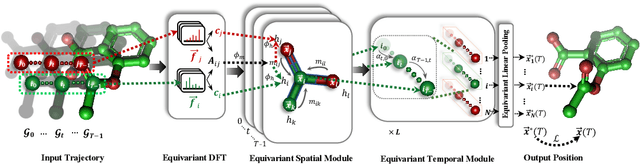
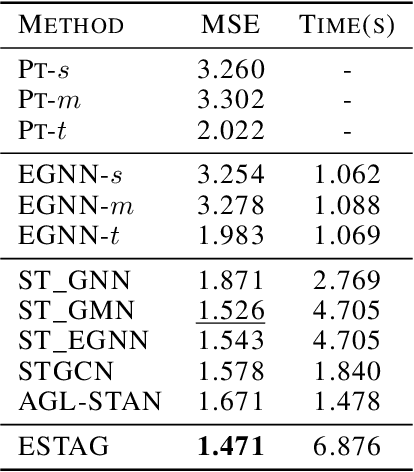
Learning to represent and simulate the dynamics of physical systems is a crucial yet challenging task. Existing equivariant Graph Neural Network (GNN) based methods have encapsulated the symmetry of physics, \emph{e.g.}, translations, rotations, etc, leading to better generalization ability. Nevertheless, their frame-to-frame formulation of the task overlooks the non-Markov property mainly incurred by unobserved dynamics in the environment. In this paper, we reformulate dynamics simulation as a spatio-temporal prediction task, by employing the trajectory in the past period to recover the Non-Markovian interactions. We propose Equivariant Spatio-Temporal Attentive Graph Networks (ESTAG), an equivariant version of spatio-temporal GNNs, to fulfill our purpose. At its core, we design a novel Equivariant Discrete Fourier Transform (EDFT) to extract periodic patterns from the history frames, and then construct an Equivariant Spatial Module (ESM) to accomplish spatial message passing, and an Equivariant Temporal Module (ETM) with the forward attention and equivariant pooling mechanisms to aggregate temporal message. We evaluate our model on three real datasets corresponding to the molecular-, protein- and macro-level. Experimental results verify the effectiveness of ESTAG compared to typical spatio-temporal GNNs and equivariant GNNs.
Robust Graph Neural Networks via Unbiased Aggregation
Nov 25, 2023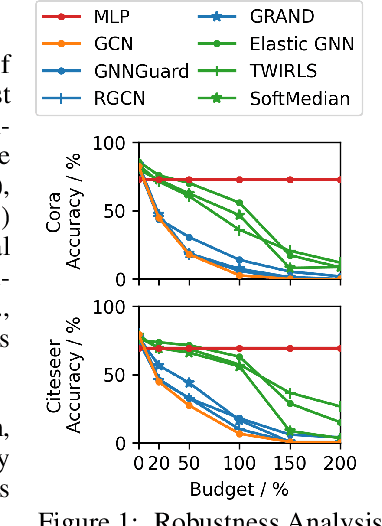
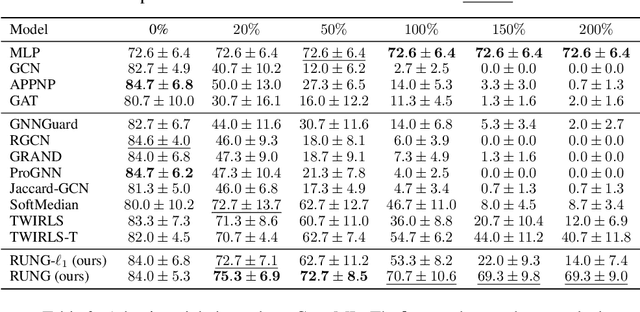
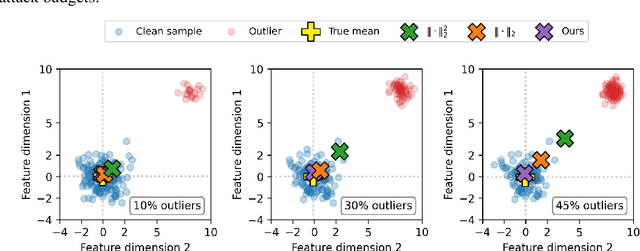
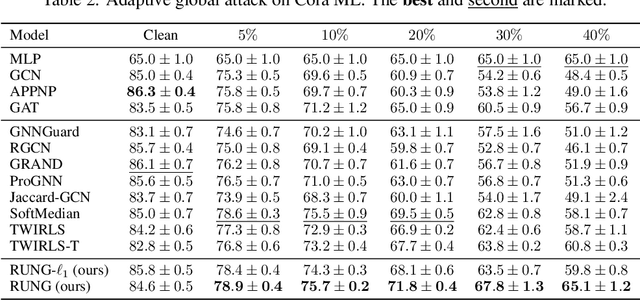
The adversarial robustness of Graph Neural Networks (GNNs) has been questioned due to the false sense of security uncovered by strong adaptive attacks despite the existence of numerous defenses. In this work, we delve into the robustness analysis of representative robust GNNs and provide a unified robust estimation point of view to understand their robustness and limitations. Our novel analysis of estimation bias motivates the design of a robust and unbiased graph signal estimator. We then develop an efficient Quasi-Newton iterative reweighted least squares algorithm to solve the estimation problem, which unfolds as robust unbiased aggregation layers in GNNs with a theoretical convergence guarantee. Our comprehensive experiments confirm the strong robustness of our proposed model, and the ablation study provides a deep understanding of its advantages.
Automated Polynomial Filter Learning for Graph Neural Networks
Jul 16, 2023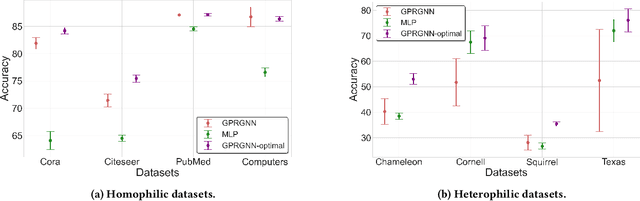



Polynomial graph filters have been widely used as guiding principles in the design of Graph Neural Networks (GNNs). Recently, the adaptive learning of the polynomial graph filters has demonstrated promising performance for modeling graph signals on both homophilic and heterophilic graphs, owning to their flexibility and expressiveness. In this work, we conduct a novel preliminary study to explore the potential and limitations of polynomial graph filter learning approaches, revealing a severe overfitting issue. To improve the effectiveness of polynomial graph filters, we propose Auto-Polynomial, a novel and general automated polynomial graph filter learning framework that efficiently learns better filters capable of adapting to various complex graph signals. Comprehensive experiments and ablation studies demonstrate significant and consistent performance improvements on both homophilic and heterophilic graphs across multiple learning settings considering various labeling ratios, which unleashes the potential of polynomial filter learning.