 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCEDL: Centre-Enhanced Discriminative Learning for Anomaly Detection
Nov 15, 2025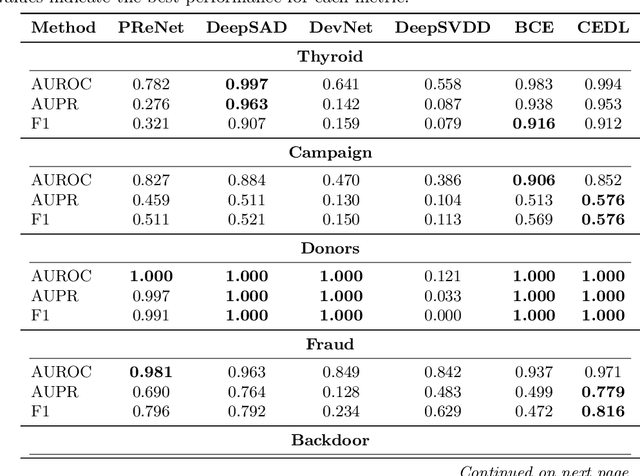
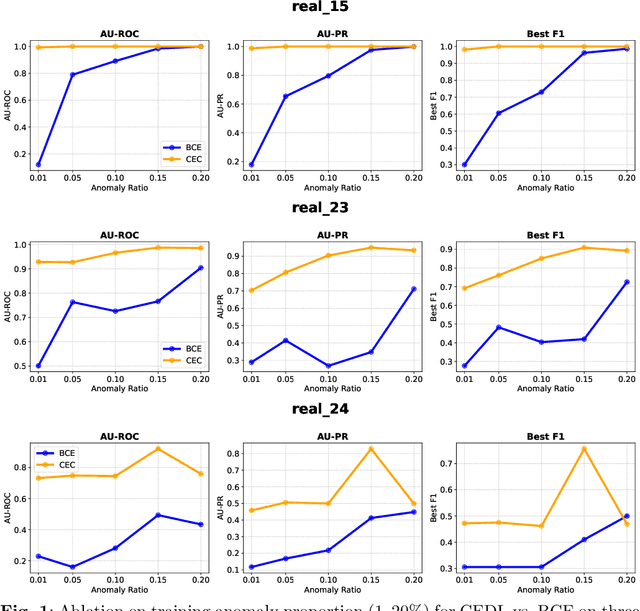
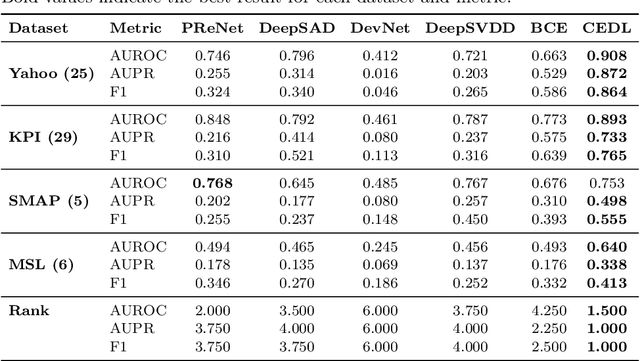
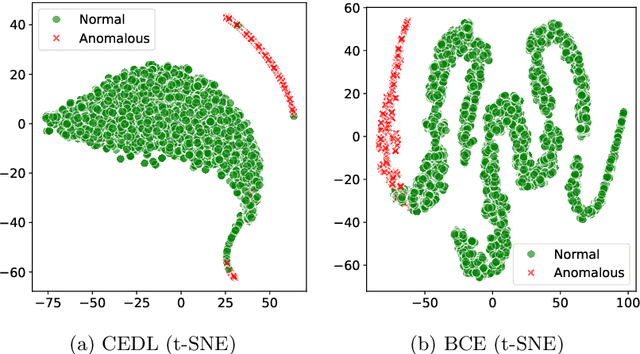
Supervised anomaly detection methods perform well in identifying known anomalies that are well represented in the training set. However, they often struggle to generalise beyond the training distribution due to decision boundaries that lack a clear definition of normality. Existing approaches typically address this by regularising the representation space during training, leading to separate optimisation in latent and label spaces. The learned normality is therefore not directly utilised at inference, and their anomaly scores often fall within arbitrary ranges that require explicit mapping or calibration for probabilistic interpretation. To achieve unified learning of geometric normality and label discrimination, we propose Centre-Enhanced Discriminative Learning (CEDL), a novel supervised anomaly detection framework that embeds geometric normality directly into the discriminative objective. CEDL reparameterises the conventional sigmoid-derived prediction logit through a centre-based radial distance function, unifying geometric and discriminative learning in a single end-to-end formulation. This design enables interpretable, geometry-aware anomaly scoring without post-hoc thresholding or reference calibration. Extensive experiments on tabular, time-series, and image data demonstrate that CEDL achieves competitive and balanced performance across diverse real-world anomaly detection tasks, validating its effectiveness and broad applicability.
SoK: Machine Unlearning for Large Language Models
Jun 10, 2025

Large language model (LLM) unlearning has become a critical topic in machine learning, aiming to eliminate the influence of specific training data or knowledge without retraining the model from scratch. A variety of techniques have been proposed, including Gradient Ascent, model editing, and re-steering hidden representations. While existing surveys often organize these methods by their technical characteristics, such classifications tend to overlook a more fundamental dimension: the underlying intention of unlearning--whether it seeks to truly remove internal knowledge or merely suppress its behavioral effects. In this SoK paper, we propose a new taxonomy based on this intention-oriented perspective. Building on this taxonomy, we make three key contributions. First, we revisit recent findings suggesting that many removal methods may functionally behave like suppression, and explore whether true removal is necessary or achievable. Second, we survey existing evaluation strategies, identify limitations in current metrics and benchmarks, and suggest directions for developing more reliable and intention-aligned evaluations. Third, we highlight practical challenges--such as scalability and support for sequential unlearning--that currently hinder the broader deployment of unlearning methods. In summary, this work offers a comprehensive framework for understanding and advancing unlearning in generative AI, aiming to support future research and guide policy decisions around data removal and privacy.
GenIAS: Generator for Instantiating Anomalies in time Series
Feb 12, 2025



A recent and promising approach for building time series anomaly detection (TSAD) models is to inject synthetic samples of anomalies within real data sets. The existing injection mechanisms have significant limitations - most of them rely on ad hoc, hand-crafted strategies which fail to capture the natural diversity of anomalous patterns, or are restricted to univariate time series settings. To address these challenges, we design a generative model for TSAD using a variational autoencoder, which is referred to as a Generator for Instantiating Anomalies in Time Series (GenIAS). GenIAS is designed to produce diverse and realistic synthetic anomalies for TSAD tasks. By employing a novel learned perturbation mechanism in the latent space and injecting the perturbed patterns in different segments of time series, GenIAS can generate anomalies with greater diversity and varying scales. Further, guided by a new triplet loss function, which uses a min-max margin and a new variance-scaling approach to further enforce the learning of compact normal patterns, GenIAS ensures that anomalies are distinct from normal samples while remaining realistic. The approach is effective for both univariate and multivariate time series. We demonstrate the diversity and realism of the generated anomalies. Our extensive experiments demonstrate that GenIAS - when integrated into a TSAD task - consistently outperforms seventeen traditional and deep anomaly detection models, thereby highlighting the potential of generative models for time series anomaly generation.
Replacing Paths with Connection-Biased Attention for Knowledge Graph Completion
Oct 01, 2024



Knowledge graph (KG) completion aims to identify additional facts that can be inferred from the existing facts in the KG. Recent developments in this field have explored this task in the inductive setting, where at test time one sees entities that were not present during training; the most performant models in the inductive setting have employed path encoding modules in addition to standard subgraph encoding modules. This work similarly focuses on KG completion in the inductive setting, without the explicit use of path encodings, which can be time-consuming and introduces several hyperparameters that require costly hyperparameter optimization. Our approach uses a Transformer-based subgraph encoding module only; we introduce connection-biased attention and entity role embeddings into the subgraph encoding module to eliminate the need for an expensive and time-consuming path encoding module. Evaluations on standard inductive KG completion benchmark datasets demonstrate that our Connection-Biased Link Prediction (CBLiP) model has superior performance to models that do not use path information. Compared to models that utilize path information, CBLiP shows competitive or superior performance while being faster. Additionally, to show that the effectiveness of connection-biased attention and entity role embeddings also holds in the transductive setting, we compare CBLiP's performance on the relation prediction task in the transductive setting.
Edge Classification on Graphs: New Directions in Topological Imbalance
Jun 18, 2024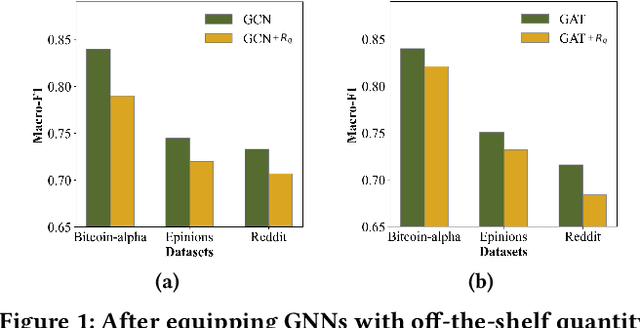
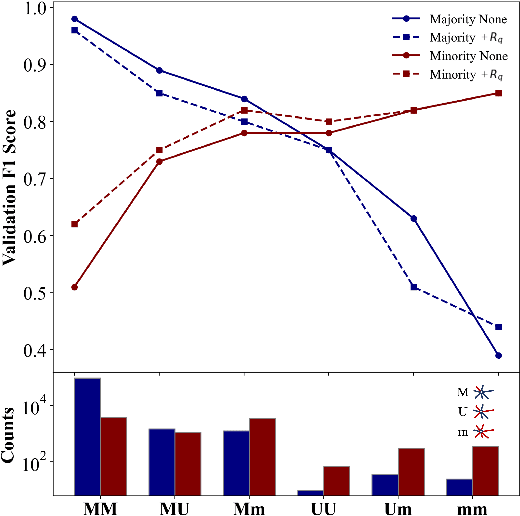
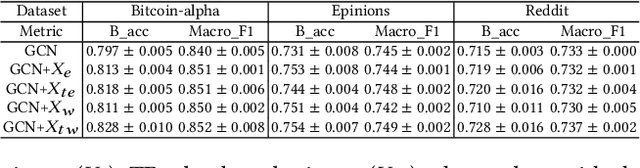
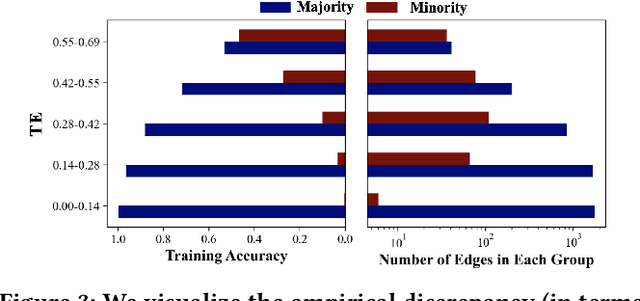
Recent years have witnessed the remarkable success of applying Graph machine learning (GML) to node/graph classification and link prediction. However, edge classification task that enjoys numerous real-world applications such as social network analysis and cybersecurity, has not seen significant advancement. To address this gap, our study pioneers a comprehensive approach to edge classification. We identify a novel `Topological Imbalance Issue', which arises from the skewed distribution of edges across different classes, affecting the local subgraph of each edge and harming the performance of edge classifications. Inspired by the recent studies in node classification that the performance discrepancy exists with varying local structural patterns, we aim to investigate if the performance discrepancy in topological imbalanced edge classification can also be mitigated by characterizing the local class distribution variance. To overcome this challenge, we introduce Topological Entropy (TE), a novel topological-based metric that measures the topological imbalance for each edge. Our empirical studies confirm that TE effectively measures local class distribution variance, and indicate that prioritizing edges with high TE values can help address the issue of topological imbalance. Based on this, we develop two strategies - Topological Reweighting and TE Wedge-based Mixup - to focus training on (synthetic) edges based on their TEs. While topological reweighting directly manipulates training edge weights according to TE, our wedge-based mixup interpolates synthetic edges between high TE wedges. Ultimately, we integrate these strategies into a novel topological imbalance strategy for edge classification: TopoEdge. Through extensive experiments, we demonstrate the efficacy of our proposed strategies on newly curated datasets and thus establish a new benchmark for (imbalanced) edge classification.
Unsupervised Generative Feature Transformation via Graph Contrastive Pre-training and Multi-objective Fine-tuning
May 27, 2024



Feature transformation is to derive a new feature set from original features to augment the AI power of data. In many science domains such as material performance screening, while feature transformation can model material formula interactions and compositions and discover performance drivers, supervised labels are collected from expensive and lengthy experiments. This issue motivates an Unsupervised Feature Transformation Learning (UFTL) problem. Prior literature, such as manual transformation, supervised feedback guided search, and PCA, either relies on domain knowledge or expensive supervised feedback, or suffers from large search space, or overlooks non-linear feature-feature interactions. UFTL imposes a major challenge on existing methods: how to design a new unsupervised paradigm that captures complex feature interactions and avoids large search space? To fill this gap, we connect graph, contrastive, and generative learning to develop a measurement-pretrain-finetune paradigm for UFTL. For unsupervised feature set utility measurement, we propose a feature value consistency preservation perspective and develop a mean discounted cumulative gain like unsupervised metric to evaluate feature set utility. For unsupervised feature set representation pretraining, we regard a feature set as a feature-feature interaction graph, and develop an unsupervised graph contrastive learning encoder to embed feature sets into vectors. For generative transformation finetuning, we regard a feature set as a feature cross sequence and feature transformation as sequential generation. We develop a deep generative feature transformation model that coordinates the pretrained feature set encoder and the gradient information extracted from a feature set utility evaluator to optimize a transformed feature generator.
A Comprehensive Survey on Data Augmentation
May 17, 2024



Data augmentation is a series of techniques that generate high-quality artificial data by manipulating existing data samples. By leveraging data augmentation techniques, AI models can achieve significantly improved applicability in tasks involving scarce or imbalanced datasets, thereby substantially enhancing AI models' generalization capabilities. Existing literature surveys only focus on a certain type of specific modality data, and categorize these methods from modality-specific and operation-centric perspectives, which lacks a consistent summary of data augmentation methods across multiple modalities and limits the comprehension of how existing data samples serve the data augmentation process. To bridge this gap, we propose a more enlightening taxonomy that encompasses data augmentation techniques for different common data modalities. Specifically, from a data-centric perspective, this survey proposes a modality-independent taxonomy by investigating how to take advantage of the intrinsic relationship between data samples, including single-wise, pair-wise, and population-wise sample data augmentation methods. Additionally, we categorize data augmentation methods across five data modalities through a unified inductive approach.
Causal Learning for Trustworthy Recommender Systems: A Survey
Feb 13, 2024



Recommender Systems (RS) have significantly advanced online content discovery and personalized decision-making. However, emerging vulnerabilities in RS have catalyzed a paradigm shift towards Trustworthy RS (TRS). Despite numerous progress on TRS, most of them focus on data correlations while overlooking the fundamental causal nature in recommendation. This drawback hinders TRS from identifying the cause in addressing trustworthiness issues, leading to limited fairness, robustness, and explainability. To bridge this gap, causal learning emerges as a class of promising methods to augment TRS. These methods, grounded in reliable causality, excel in mitigating various biases and noises while offering insightful explanations for TRS. However, there lacks a timely survey in this vibrant area. This paper creates an overview of TRS from the perspective of causal learning. We begin by presenting the advantages and common procedures of Causality-oriented TRS (CTRS). Then, we identify potential trustworthiness challenges at each stage and link them to viable causal solutions, followed by a classification of CTRS methods. Finally, we discuss several future directions for advancing this field.
Distance-Based Propagation for Efficient Knowledge Graph Reasoning
Nov 02, 2023



Knowledge graph completion (KGC) aims to predict unseen edges in knowledge graphs (KGs), resulting in the discovery of new facts. A new class of methods have been proposed to tackle this problem by aggregating path information. These methods have shown tremendous ability in the task of KGC. However they are plagued by efficiency issues. Though there are a few recent attempts to address this through learnable path pruning, they often sacrifice the performance to gain efficiency. In this work, we identify two intrinsic limitations of these methods that affect the efficiency and representation quality. To address the limitations, we introduce a new method, TAGNet, which is able to efficiently propagate information. This is achieved by only aggregating paths in a fixed window for each source-target pair. We demonstrate that the complexity of TAGNet is independent of the number of layers. Extensive experiments demonstrate that TAGNet can cut down on the number of propagated messages by as much as 90% while achieving competitive performance on multiple KG datasets. The code is available at https://github.com/HarryShomer/TAGNet.
Can Directed Graph Neural Networks be Adversarially Robust?
Jun 03, 2023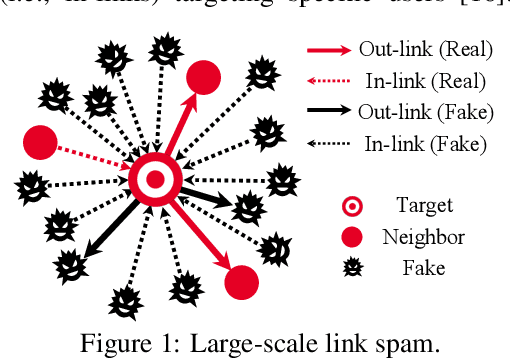
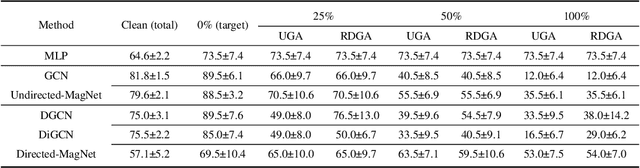
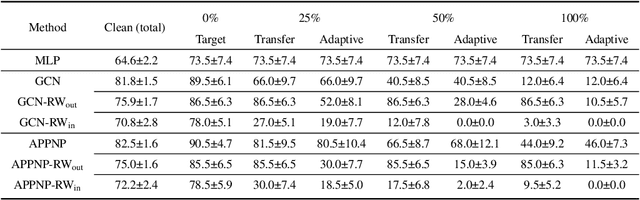
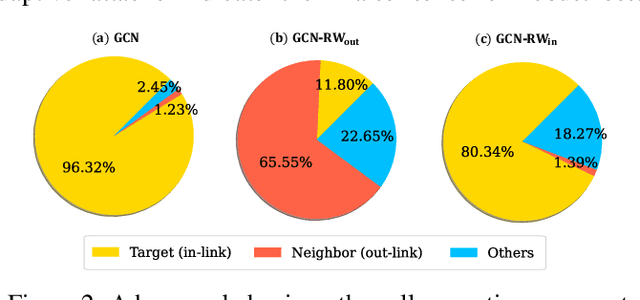
The existing research on robust Graph Neural Networks (GNNs) fails to acknowledge the significance of directed graphs in providing rich information about networks' inherent structure. This work presents the first investigation into the robustness of GNNs in the context of directed graphs, aiming to harness the profound trust implications offered by directed graphs to bolster the robustness and resilience of GNNs. Our study reveals that existing directed GNNs are not adversarially robust. In pursuit of our goal, we introduce a new and realistic directed graph attack setting and propose an innovative, universal, and efficient message-passing framework as a plug-in layer to significantly enhance the robustness of GNNs. Combined with existing defense strategies, this framework achieves outstanding clean accuracy and state-of-the-art robust performance, offering superior defense against both transfer and adaptive attacks. The findings in this study reveal a novel and promising direction for this crucial research area. The code will be made publicly available upon the acceptance of this work.