 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCEDL: Centre-Enhanced Discriminative Learning for Anomaly Detection
Nov 15, 2025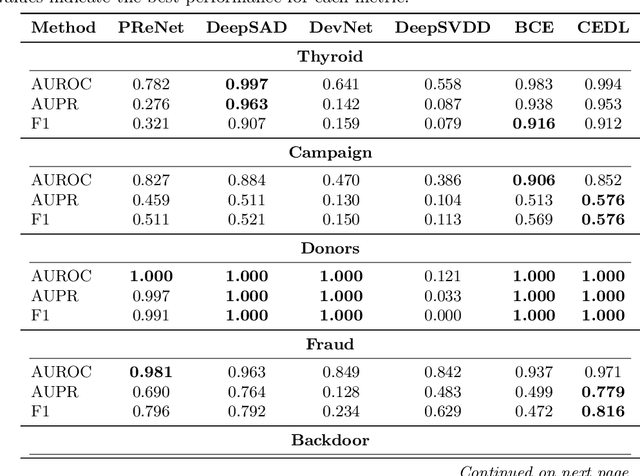
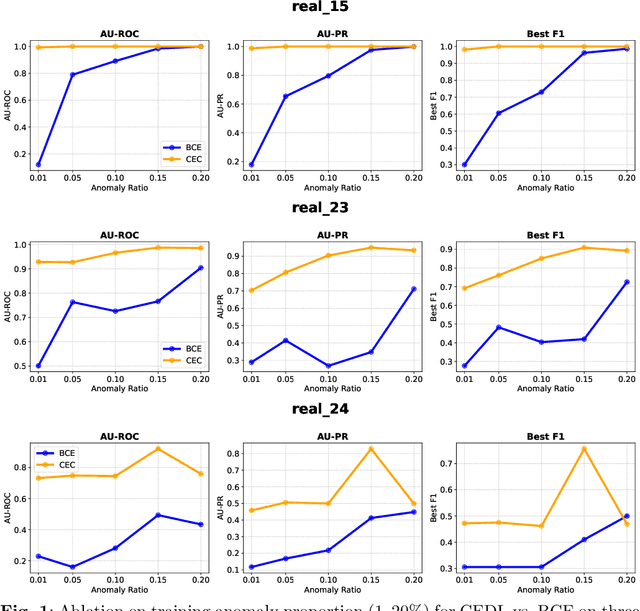
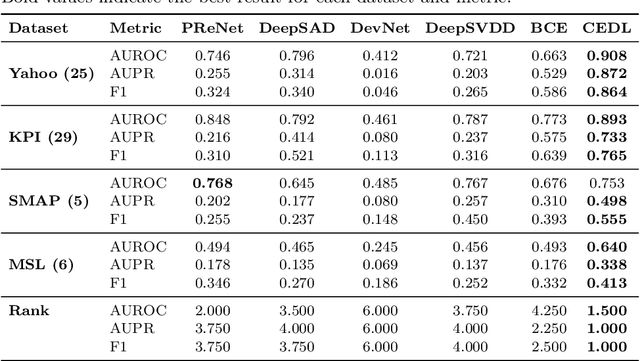
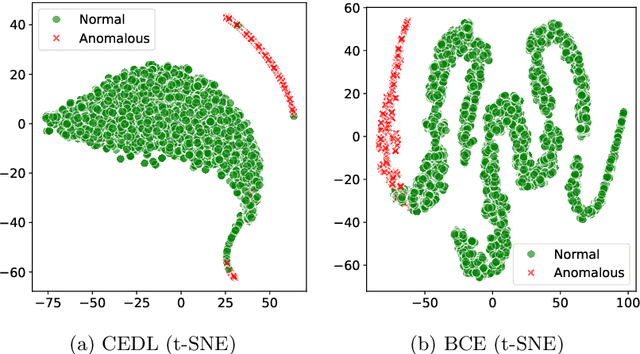
Supervised anomaly detection methods perform well in identifying known anomalies that are well represented in the training set. However, they often struggle to generalise beyond the training distribution due to decision boundaries that lack a clear definition of normality. Existing approaches typically address this by regularising the representation space during training, leading to separate optimisation in latent and label spaces. The learned normality is therefore not directly utilised at inference, and their anomaly scores often fall within arbitrary ranges that require explicit mapping or calibration for probabilistic interpretation. To achieve unified learning of geometric normality and label discrimination, we propose Centre-Enhanced Discriminative Learning (CEDL), a novel supervised anomaly detection framework that embeds geometric normality directly into the discriminative objective. CEDL reparameterises the conventional sigmoid-derived prediction logit through a centre-based radial distance function, unifying geometric and discriminative learning in a single end-to-end formulation. This design enables interpretable, geometry-aware anomaly scoring without post-hoc thresholding or reference calibration. Extensive experiments on tabular, time-series, and image data demonstrate that CEDL achieves competitive and balanced performance across diverse real-world anomaly detection tasks, validating its effectiveness and broad applicability.
GenIAS: Generator for Instantiating Anomalies in time Series
Feb 12, 2025



A recent and promising approach for building time series anomaly detection (TSAD) models is to inject synthetic samples of anomalies within real data sets. The existing injection mechanisms have significant limitations - most of them rely on ad hoc, hand-crafted strategies which fail to capture the natural diversity of anomalous patterns, or are restricted to univariate time series settings. To address these challenges, we design a generative model for TSAD using a variational autoencoder, which is referred to as a Generator for Instantiating Anomalies in Time Series (GenIAS). GenIAS is designed to produce diverse and realistic synthetic anomalies for TSAD tasks. By employing a novel learned perturbation mechanism in the latent space and injecting the perturbed patterns in different segments of time series, GenIAS can generate anomalies with greater diversity and varying scales. Further, guided by a new triplet loss function, which uses a min-max margin and a new variance-scaling approach to further enforce the learning of compact normal patterns, GenIAS ensures that anomalies are distinct from normal samples while remaining realistic. The approach is effective for both univariate and multivariate time series. We demonstrate the diversity and realism of the generated anomalies. Our extensive experiments demonstrate that GenIAS - when integrated into a TSAD task - consistently outperforms seventeen traditional and deep anomaly detection models, thereby highlighting the potential of generative models for time series anomaly generation.
DACAD: Domain Adaptation Contrastive Learning for Anomaly Detection in Multivariate Time Series
Apr 17, 2024Time series anomaly detection (TAD) faces a significant challenge due to the scarcity of labelled data, which hinders the development of accurate detection models. Unsupervised domain adaptation (UDA) addresses this challenge by leveraging a labelled dataset from a related domain to detect anomalies in a target dataset. Existing domain adaptation techniques assume that the number of anomalous classes does not change between the source and target domains. In this paper, we propose a novel Domain Adaptation Contrastive learning for Anomaly Detection in multivariate time series (DACAD) model to address this issue by combining UDA and contrastive representation learning. DACAD's approach includes an anomaly injection mechanism that introduces various types of synthetic anomalies, enhancing the model's ability to generalise across unseen anomalous classes in different domains. This method significantly broadens the model's adaptability and robustness. Additionally, we propose a supervised contrastive loss for the source domain and a self-supervised contrastive triplet loss for the target domain, improving comprehensive feature representation learning and extraction of domain-invariant features. Finally, an effective Centre-based Entropy Classifier (CEC) is proposed specifically for anomaly detection, facilitating accurate learning of normal boundaries in the source domain. Our extensive evaluation across multiple real-world datasets against leading models in time series anomaly detection and UDA underscores DACAD's effectiveness. The results validate DACAD's superiority in transferring knowledge across domains and its potential to mitigate the challenge of limited labelled data in time series anomaly detection.
CARLA: A Self-supervised Contrastive Representation Learning Approach for Time Series Anomaly Detection
Aug 18, 2023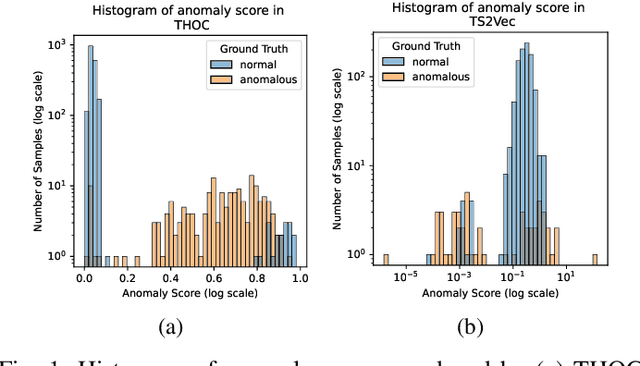
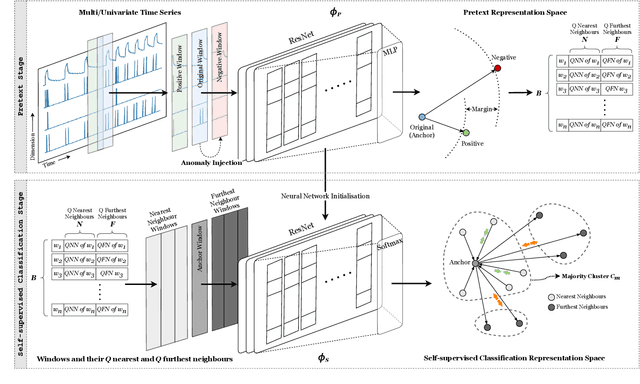
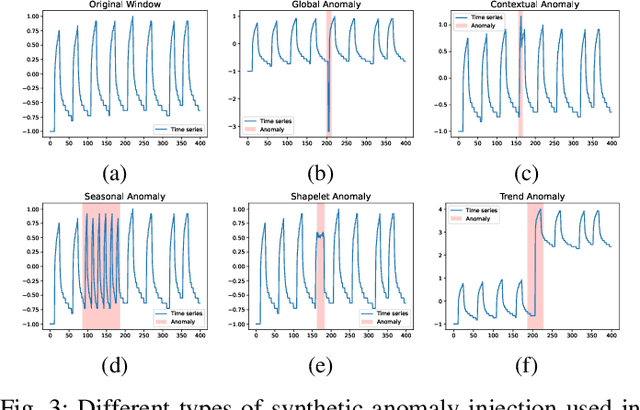
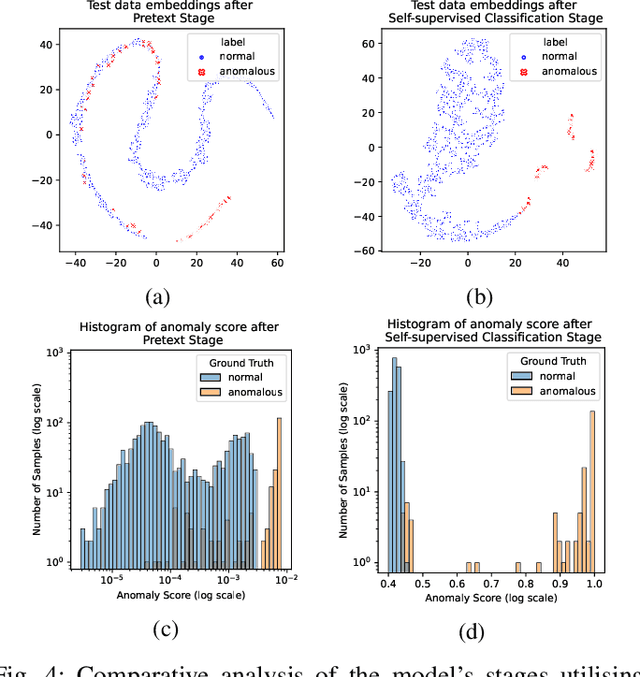
We introduce a Self-supervised Contrastive Representation Learning Approach for Time Series Anomaly Detection (CARLA), an innovative end-to-end self-supervised framework carefully developed to identify anomalous patterns in both univariate and multivariate time series data. By taking advantage of contrastive representation learning, We introduce an innovative end-to-end self-supervised deep learning framework carefully developed to identify anomalous patterns in both univariate and multivariate time series data. By taking advantage of contrastive representation learning, CARLA effectively generates robust representations for time series windows. It achieves this by 1) learning similar representations for temporally close windows and dissimilar representations for windows and their equivalent anomalous windows and 2) employing a self-supervised approach to classify normal/anomalous representations of windows based on their nearest/furthest neighbours in the representation space. Most of the existing models focus on learning normal behaviour. The normal boundary is often tightly defined, which can result in slight deviations being classified as anomalies, resulting in a high false positive rate and limited ability to generalise normal patterns. CARLA's contrastive learning methodology promotes the production of highly consistent and discriminative predictions, thereby empowering us to adeptly address the inherent challenges associated with anomaly detection in time series data. Through extensive experimentation on 7 standard real-world time series anomaly detection benchmark datasets, CARLA demonstrates F1 and AU-PR superior to existing state-of-the-art results. Our research highlights the immense potential of contrastive representation learning in advancing the field of time series anomaly detection, thus paving the way for novel applications and in-depth exploration in this domain.
Deep Learning for Time Series Anomaly Detection: A Survey
Nov 09, 2022
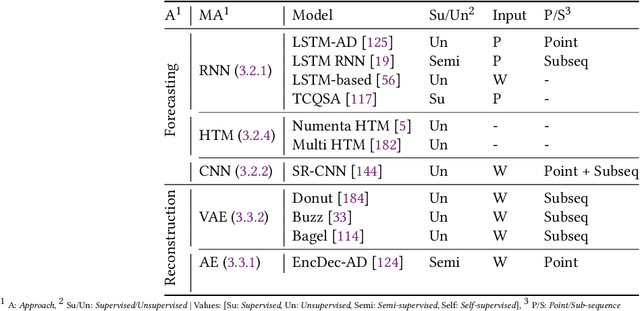

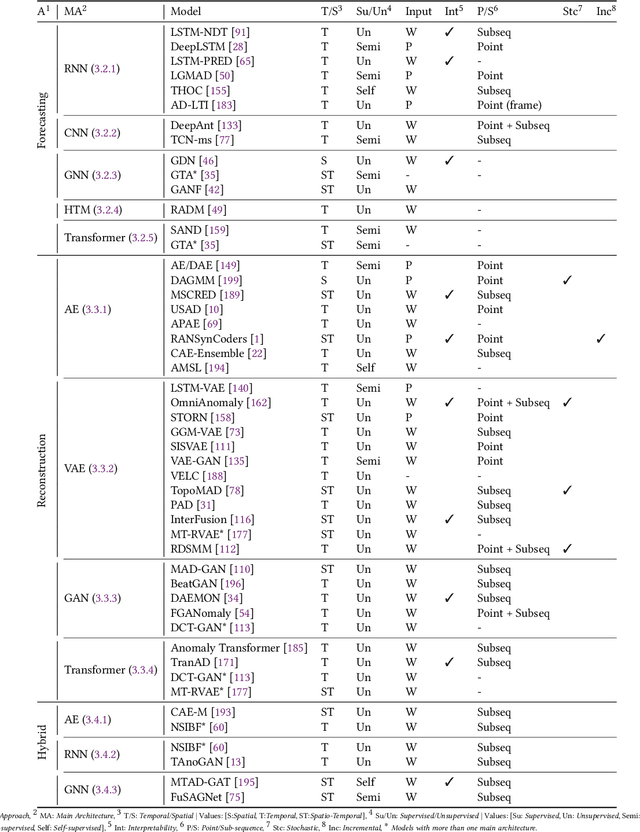
Time series anomaly detection has applications in a wide range of research fields and applications, including manufacturing and healthcare. The presence of anomalies can indicate novel or unexpected events, such as production faults, system defects, or heart fluttering, and is therefore of particular interest. The large size and complex patterns of time series have led researchers to develop specialised deep learning models for detecting anomalous patterns. This survey focuses on providing structured and comprehensive state-of-the-art time series anomaly detection models through the use of deep learning. It providing a taxonomy based on the factors that divide anomaly detection models into different categories. Aside from describing the basic anomaly detection technique for each category, the advantages and limitations are also discussed. Furthermore, this study includes examples of deep anomaly detection in time series across various application domains in recent years. It finally summarises open issues in research and challenges faced while adopting deep anomaly detection models.
GHRS: Graph-based Hybrid Recommendation System with Application to Movie Recommendation
Nov 06, 2021


Research about recommender systems emerges over the last decade and comprises valuable services to increase different companies' revenue. Several approaches exist in handling paper recommender systems. While most existing recommender systems rely either on a content-based approach or a collaborative approach, there are hybrid approaches that can improve recommendation accuracy using a combination of both approaches. Even though many algorithms are proposed using such methods, it is still necessary for further improvement. In this paper, we propose a recommender system method using a graph-based model associated with the similarity of users' ratings, in combination with users' demographic and location information. By utilizing the advantages of Autoencoder feature extraction, we extract new features based on all combined attributes. Using the new set of features for clustering users, our proposed approach (GHRS) has gained a significant improvement, which dominates other methods' performance in the cold-start problem. The experimental results on the MovieLens dataset show that the proposed algorithm outperforms many existing recommendation algorithms on recommendation accuracy.