 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCEDL: Centre-Enhanced Discriminative Learning for Anomaly Detection
Nov 15, 2025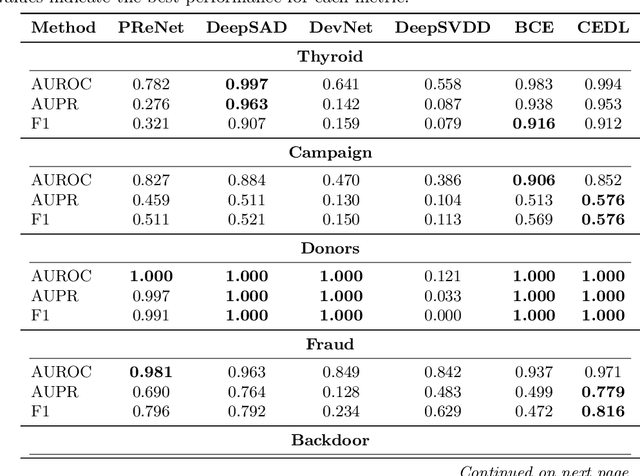
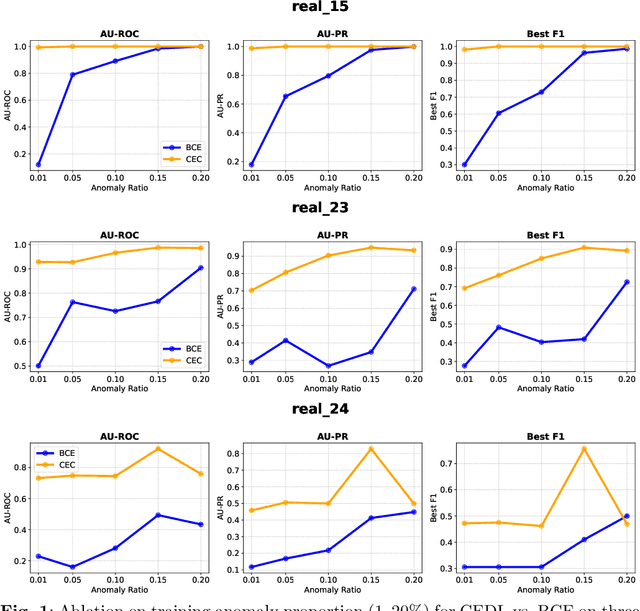
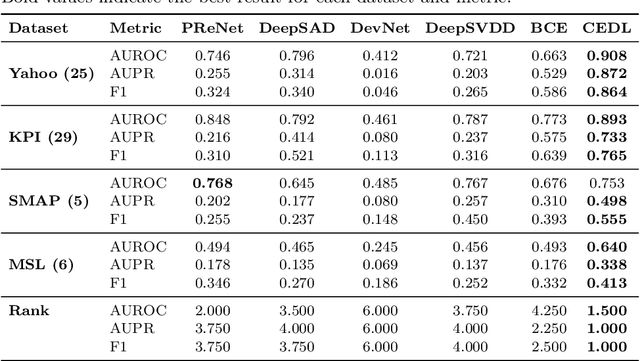
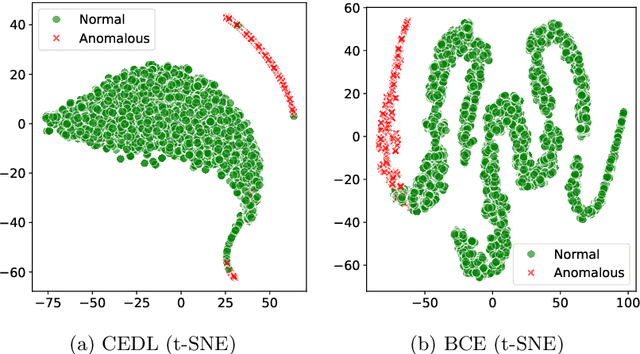
Supervised anomaly detection methods perform well in identifying known anomalies that are well represented in the training set. However, they often struggle to generalise beyond the training distribution due to decision boundaries that lack a clear definition of normality. Existing approaches typically address this by regularising the representation space during training, leading to separate optimisation in latent and label spaces. The learned normality is therefore not directly utilised at inference, and their anomaly scores often fall within arbitrary ranges that require explicit mapping or calibration for probabilistic interpretation. To achieve unified learning of geometric normality and label discrimination, we propose Centre-Enhanced Discriminative Learning (CEDL), a novel supervised anomaly detection framework that embeds geometric normality directly into the discriminative objective. CEDL reparameterises the conventional sigmoid-derived prediction logit through a centre-based radial distance function, unifying geometric and discriminative learning in a single end-to-end formulation. This design enables interpretable, geometry-aware anomaly scoring without post-hoc thresholding or reference calibration. Extensive experiments on tabular, time-series, and image data demonstrate that CEDL achieves competitive and balanced performance across diverse real-world anomaly detection tasks, validating its effectiveness and broad applicability.
EEG-X: Device-Agnostic and Noise-Robust Foundation Model for EEG
Nov 12, 2025



Foundation models for EEG analysis are still in their infancy, limited by two key challenges: (1) variability across datasets caused by differences in recording devices and configurations, and (2) the low signal-to-noise ratio (SNR) of EEG, where brain signals are often buried under artifacts and non-brain sources. To address these challenges, we present EEG-X, a device-agnostic and noise-robust foundation model for EEG representation learning. EEG-X introduces a novel location-based channel embedding that encodes spatial information and improves generalization across domains and tasks by allowing the model to handle varying channel numbers, combinations, and recording lengths. To enhance robustness against noise, EEG-X employs a noise-aware masking and reconstruction strategy in both raw and latent spaces. Unlike previous models that mask and reconstruct raw noisy EEG signals, EEG-X is trained to reconstruct denoised signals obtained through an artifact removal process, ensuring that the learned representations focus on neural activity rather than noise. To further enhance reconstruction-based pretraining, EEG-X introduces a dictionary-inspired convolutional transformation (DiCT) layer that projects signals into a structured feature space before computing reconstruction (MSE) loss, reducing noise sensitivity and capturing frequency- and shape-aware similarities. Experiments on datasets collected from diverse devices show that EEG-X outperforms state-of-the-art methods across multiple downstream EEG tasks and excels in cross-domain settings where pre-trained and downstream datasets differ in electrode layouts. The models and code are available at: https://github.com/Emotiv/EEG-X
MONSTER: Monash Scalable Time Series Evaluation Repository
Feb 21, 2025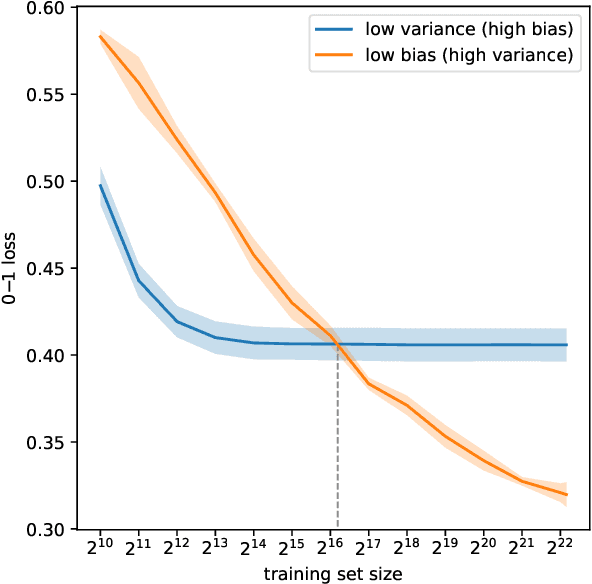
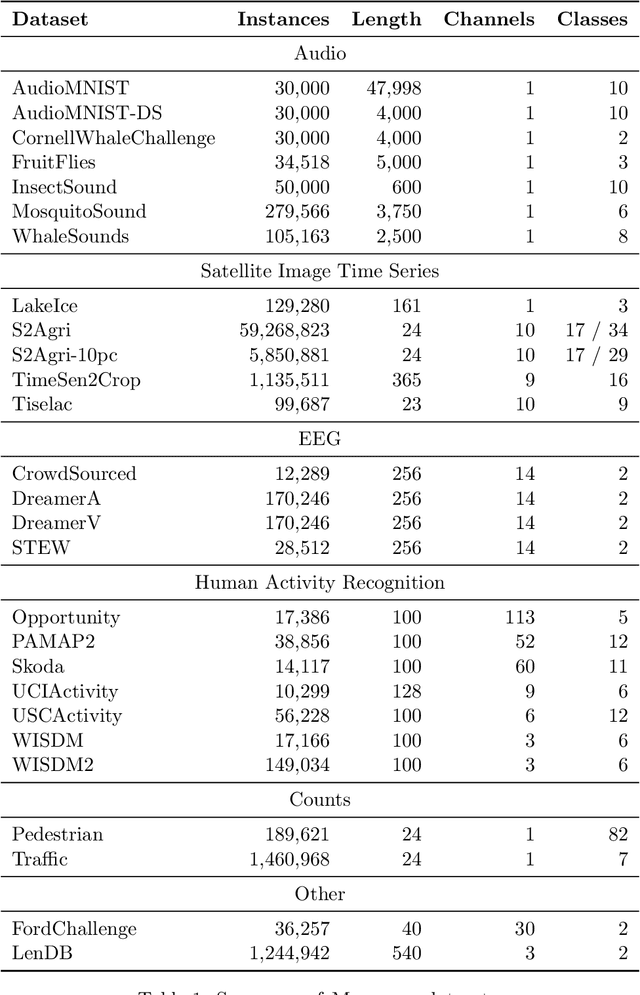
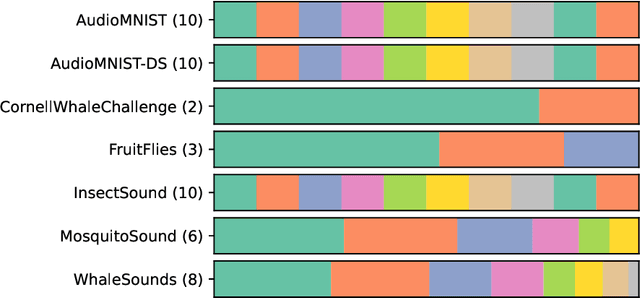
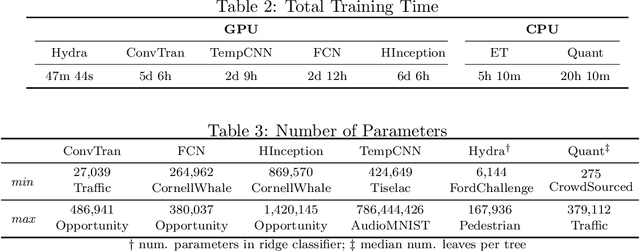
We introduce MONSTER-the MONash Scalable Time Series Evaluation Repository-a collection of large datasets for time series classification. The field of time series classification has benefitted from common benchmarks set by the UCR and UEA time series classification repositories. However, the datasets in these benchmarks are small, with median sizes of 217 and 255 examples, respectively. In consequence they favour a narrow subspace of models that are optimised to achieve low classification error on a wide variety of smaller datasets, that is, models that minimise variance, and give little weight to computational issues such as scalability. Our hope is to diversify the field by introducing benchmarks using larger datasets. We believe that there is enormous potential for new progress in the field by engaging with the theoretical and practical challenges of learning effectively from larger quantities of data.
GenIAS: Generator for Instantiating Anomalies in time Series
Feb 12, 2025



A recent and promising approach for building time series anomaly detection (TSAD) models is to inject synthetic samples of anomalies within real data sets. The existing injection mechanisms have significant limitations - most of them rely on ad hoc, hand-crafted strategies which fail to capture the natural diversity of anomalous patterns, or are restricted to univariate time series settings. To address these challenges, we design a generative model for TSAD using a variational autoencoder, which is referred to as a Generator for Instantiating Anomalies in Time Series (GenIAS). GenIAS is designed to produce diverse and realistic synthetic anomalies for TSAD tasks. By employing a novel learned perturbation mechanism in the latent space and injecting the perturbed patterns in different segments of time series, GenIAS can generate anomalies with greater diversity and varying scales. Further, guided by a new triplet loss function, which uses a min-max margin and a new variance-scaling approach to further enforce the learning of compact normal patterns, GenIAS ensures that anomalies are distinct from normal samples while remaining realistic. The approach is effective for both univariate and multivariate time series. We demonstrate the diversity and realism of the generated anomalies. Our extensive experiments demonstrate that GenIAS - when integrated into a TSAD task - consistently outperforms seventeen traditional and deep anomaly detection models, thereby highlighting the potential of generative models for time series anomaly generation.
DACAD: Domain Adaptation Contrastive Learning for Anomaly Detection in Multivariate Time Series
Apr 17, 2024Time series anomaly detection (TAD) faces a significant challenge due to the scarcity of labelled data, which hinders the development of accurate detection models. Unsupervised domain adaptation (UDA) addresses this challenge by leveraging a labelled dataset from a related domain to detect anomalies in a target dataset. Existing domain adaptation techniques assume that the number of anomalous classes does not change between the source and target domains. In this paper, we propose a novel Domain Adaptation Contrastive learning for Anomaly Detection in multivariate time series (DACAD) model to address this issue by combining UDA and contrastive representation learning. DACAD's approach includes an anomaly injection mechanism that introduces various types of synthetic anomalies, enhancing the model's ability to generalise across unseen anomalous classes in different domains. This method significantly broadens the model's adaptability and robustness. Additionally, we propose a supervised contrastive loss for the source domain and a self-supervised contrastive triplet loss for the target domain, improving comprehensive feature representation learning and extraction of domain-invariant features. Finally, an effective Centre-based Entropy Classifier (CEC) is proposed specifically for anomaly detection, facilitating accurate learning of normal boundaries in the source domain. Our extensive evaluation across multiple real-world datasets against leading models in time series anomaly detection and UDA underscores DACAD's effectiveness. The results validate DACAD's superiority in transferring knowledge across domains and its potential to mitigate the challenge of limited labelled data in time series anomaly detection.
Human Brain Exhibits Distinct Patterns When Listening to Fake Versus Real Audio: Preliminary Evidence
Feb 22, 2024



In this paper we study the variations in human brain activity when listening to real and fake audio. Our preliminary results suggest that the representations learned by a state-of-the-art deepfake audio detection algorithm, do not exhibit clear distinct patterns between real and fake audio. In contrast, human brain activity, as measured by EEG, displays distinct patterns when individuals are exposed to fake versus real audio. This preliminary evidence enables future research directions in areas such as deepfake audio detection.
EEG2Rep: Enhancing Self-supervised EEG Representation Through Informative Masked Inputs
Feb 17, 2024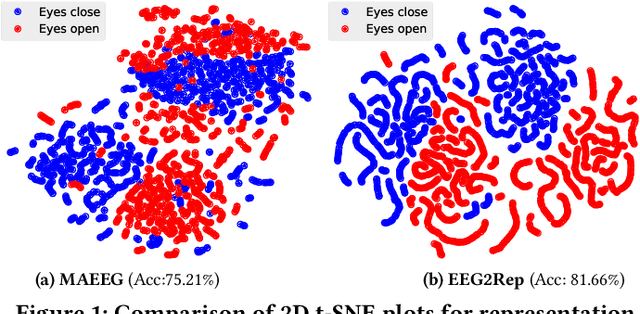
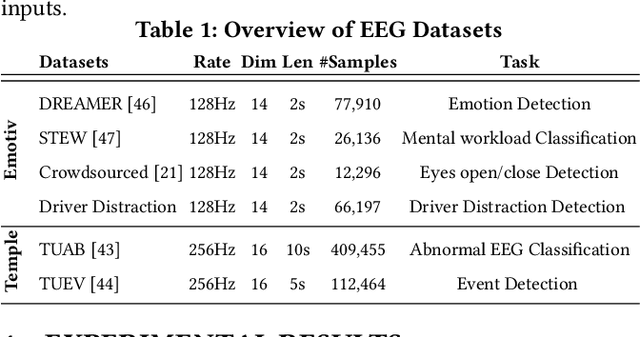
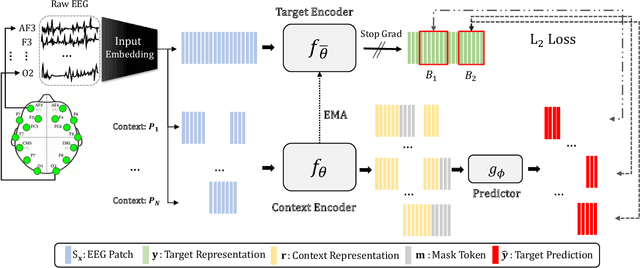
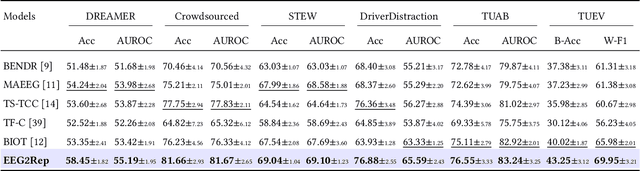
Self-supervised approaches for electroencephalography (EEG) representation learning face three specific challenges inherent to EEG data: (1) The low signal-to-noise ratio which challenges the quality of the representation learned, (2) The wide range of amplitudes from very small to relatively large due to factors such as the inter-subject variability, risks the models to be dominated by higher amplitude ranges, and (3) The absence of explicit segmentation in the continuous-valued sequences which can result in less informative representations. To address these challenges, we introduce EEG2Rep, a self-prediction approach for self-supervised representation learning from EEG. Two core novel components of EEG2Rep are as follows: 1) Instead of learning to predict the masked input from raw EEG, EEG2Rep learns to predict masked input in latent representation space, and 2) Instead of conventional masking methods, EEG2Rep uses a new semantic subsequence preserving (SSP) method which provides informative masked inputs to guide EEG2Rep to generate rich semantic representations. In experiments on 6 diverse EEG tasks with subject variability, EEG2Rep significantly outperforms state-of-the-art methods. We show that our semantic subsequence preserving improves the existing masking methods in self-prediction literature and find that preserving 50\% of EEG recordings will result in the most accurate results on all 6 tasks on average. Finally, we show that EEG2Rep is robust to noise addressing a significant challenge that exists in EEG data. Models and code are available at: https://github.com/Navidfoumani/EEG2Rep
Series2Vec: Similarity-based Self-supervised Representation Learning for Time Series Classification
Dec 12, 2023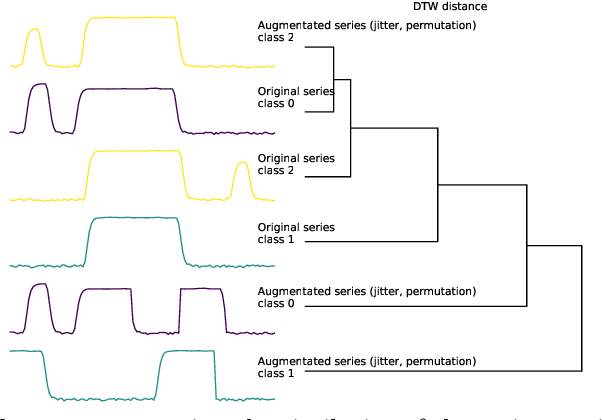
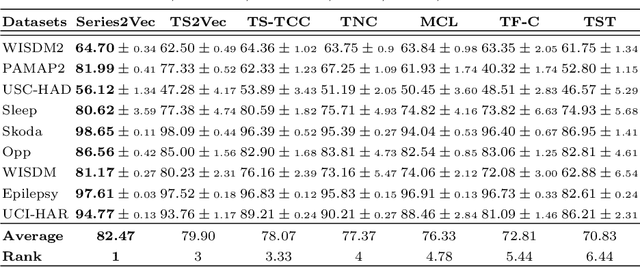
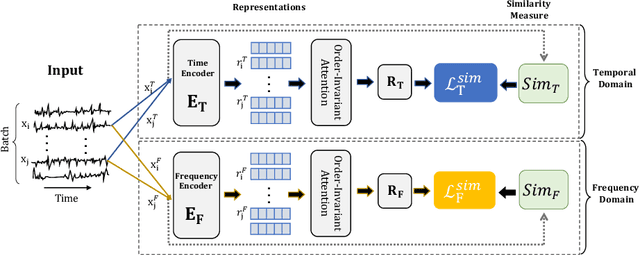

We argue that time series analysis is fundamentally different in nature to either vision or natural language processing with respect to the forms of meaningful self-supervised learning tasks that can be defined. Motivated by this insight, we introduce a novel approach called \textit{Series2Vec} for self-supervised representation learning. Unlike other self-supervised methods in time series, which carry the risk of positive sample variants being less similar to the anchor sample than series in the negative set, Series2Vec is trained to predict the similarity between two series in both temporal and spectral domains through a self-supervised task. Series2Vec relies primarily on the consistency of the unsupervised similarity step, rather than the intrinsic quality of the similarity measurement, without the need for hand-crafted data augmentation. To further enforce the network to learn similar representations for similar time series, we propose a novel approach that applies order-invariant attention to each representation within the batch during training. Our evaluation of Series2Vec on nine large real-world datasets, along with the UCR/UEA archive, shows enhanced performance compared to current state-of-the-art self-supervised techniques for time series. Additionally, our extensive experiments show that Series2Vec performs comparably with fully supervised training and offers high efficiency in datasets with limited-labeled data. Finally, we show that the fusion of Series2Vec with other representation learning models leads to enhanced performance for time series classification. Code and models are open-source at \url{https://github.com/Navidfoumani/Series2Vec.}
Open-Set Graph Anomaly Detection via Normal Structure Regularisation
Nov 12, 2023



This paper considers an under-explored Graph Anomaly Detection (GAD) task, namely open-set GAD, which aims to detect anomalous nodes using a small number of labelled training normal and anomaly nodes (known as seen anomalies) that cannot illustrate all possible inference-time abnormalities. The task has attracted growing attention due to the availability of anomaly prior knowledge from the label information that can help to substantially reduce detection errors. However, current methods tend to over-emphasise fitting the seen anomalies, leading to a weak generalisation ability to detect unseen anomalies, i.e., those that are not illustrated by the labelled anomaly nodes. Further, they were introduced to handle Euclidean data, failing to effectively capture important non-Euclidean features for GAD. In this work, we propose a novel open-set GAD approach, namely normal structure regularisation (NSReg), to leverage the rich normal graph structure embedded in the labelled nodes to tackle the aforementioned two issues. In particular, NSReg trains an anomaly-discriminative supervised graph anomaly detector, with a plug-and-play regularisation term to enforce compact, semantically-rich representations of normal nodes. To this end, the regularisation is designed to differentiate various types of normal nodes, including labelled normal nodes that are connected in their local neighbourhood, and those that are not connected. By doing so, it helps incorporate strong normality into the supervised anomaly detector learning, mitigating their overfitting to the seen anomalies. Extensive empirical results on real-world datasets demonstrate the superiority of our proposed NSReg for open-set GAD.
CARLA: A Self-supervised Contrastive Representation Learning Approach for Time Series Anomaly Detection
Aug 18, 2023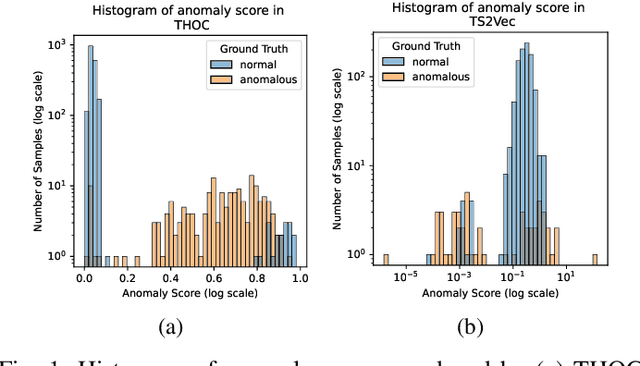
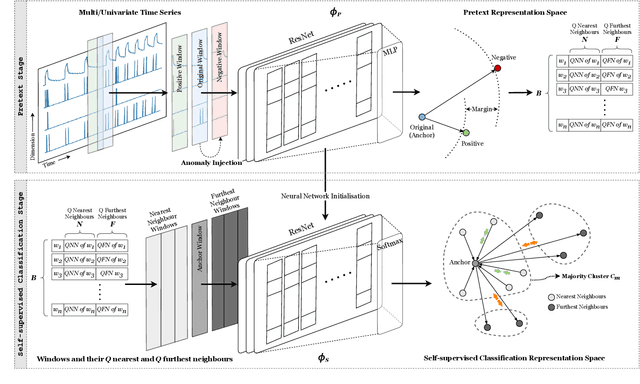
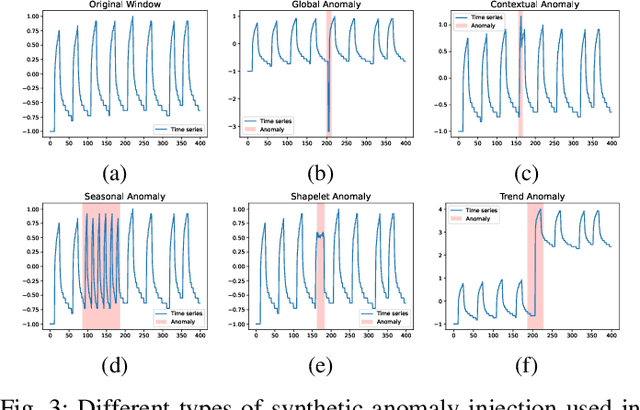
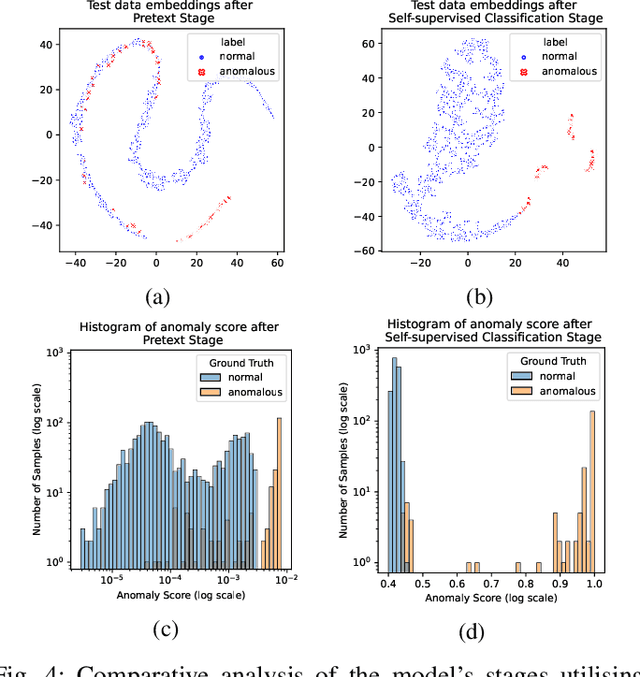
We introduce a Self-supervised Contrastive Representation Learning Approach for Time Series Anomaly Detection (CARLA), an innovative end-to-end self-supervised framework carefully developed to identify anomalous patterns in both univariate and multivariate time series data. By taking advantage of contrastive representation learning, We introduce an innovative end-to-end self-supervised deep learning framework carefully developed to identify anomalous patterns in both univariate and multivariate time series data. By taking advantage of contrastive representation learning, CARLA effectively generates robust representations for time series windows. It achieves this by 1) learning similar representations for temporally close windows and dissimilar representations for windows and their equivalent anomalous windows and 2) employing a self-supervised approach to classify normal/anomalous representations of windows based on their nearest/furthest neighbours in the representation space. Most of the existing models focus on learning normal behaviour. The normal boundary is often tightly defined, which can result in slight deviations being classified as anomalies, resulting in a high false positive rate and limited ability to generalise normal patterns. CARLA's contrastive learning methodology promotes the production of highly consistent and discriminative predictions, thereby empowering us to adeptly address the inherent challenges associated with anomaly detection in time series data. Through extensive experimentation on 7 standard real-world time series anomaly detection benchmark datasets, CARLA demonstrates F1 and AU-PR superior to existing state-of-the-art results. Our research highlights the immense potential of contrastive representation learning in advancing the field of time series anomaly detection, thus paving the way for novel applications and in-depth exploration in this domain.