 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Approach to Multiple Comparison Benchmark Evaluations that is Stable Under Manipulation of the Comparate Set
May 19, 2023
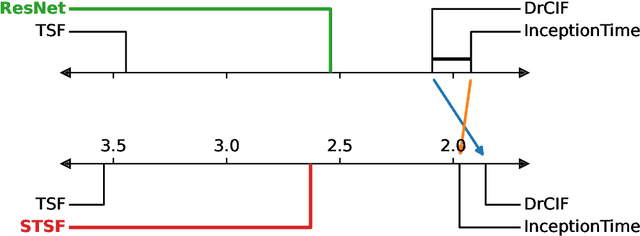
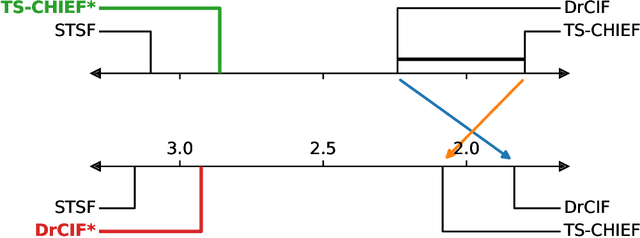
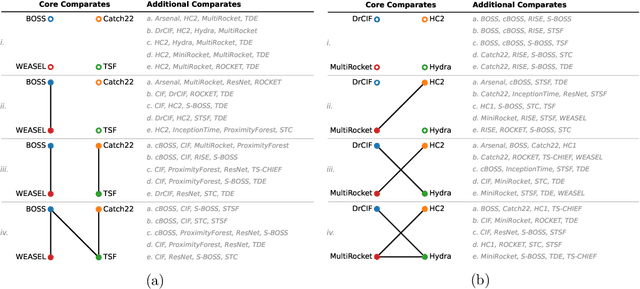
The measurement of progress using benchmarks evaluations is ubiquitous in computer science and machine learning. However, common approaches to analyzing and presenting the results of benchmark comparisons of multiple algorithms over multiple datasets, such as the critical difference diagram introduced by Dem\v{s}ar (2006), have important shortcomings and, we show, are open to both inadvertent and intentional manipulation. To address these issues, we propose a new approach to presenting the results of benchmark comparisons, the Multiple Comparison Matrix (MCM), that prioritizes pairwise comparisons and precludes the means of manipulating experimental results in existing approaches. MCM can be used to show the results of an all-pairs comparison, or to show the results of a comparison between one or more selected algorithms and the state of the art. MCM is implemented in Python and is publicly available.
Proximity Forest 2.0: A new effective and scalable similarity-based classifier for time series
Apr 13, 2023



Time series classification (TSC) is a challenging task due to the diversity of types of feature that may be relevant for different classification tasks, including trends, variance, frequency, magnitude, and various patterns. To address this challenge, several alternative classes of approach have been developed, including similarity-based, features and intervals, shapelets, dictionary, kernel, neural network, and hybrid approaches. While kernel, neural network, and hybrid approaches perform well overall, some specialized approaches are better suited for specific tasks. In this paper, we propose a new similarity-based classifier, Proximity Forest version 2.0 (PF 2.0), which outperforms previous state-of-the-art similarity-based classifiers across the UCR benchmark and outperforms state-of-the-art kernel, neural network, and hybrid methods on specific datasets in the benchmark that are best addressed by similarity-base methods. PF 2.0 incorporates three recent advances in time series similarity measures -- (1) computationally efficient early abandoning and pruning to speedup elastic similarity computations; (2) a new elastic similarity measure, Amerced Dynamic Time Warping (ADTW); and (3) cost function tuning. It rationalizes the set of similarity measures employed, reducing the eight base measures of the original PF to three and using the first derivative transform with all similarity measures, rather than a limited subset. We have implemented both PF 1.0 and PF 2.0 in a single C++ framework, making the PF framework more efficient.
Parameterizing the cost function of Dynamic Time Warping with application to time series classification
Jan 24, 2023Dynamic Time Warping (DTW) is a popular time series distance measure that aligns the points in two series with one another. These alignments support warping of the time dimension to allow for processes that unfold at differing rates. The distance is the minimum sum of costs of the resulting alignments over any allowable warping of the time dimension. The cost of an alignment of two points is a function of the difference in the values of those points. The original cost function was the absolute value of this difference. Other cost functions have been proposed. A popular alternative is the square of the difference. However, to our knowledge, this is the first investigation of both the relative impacts of using different cost functions and the potential to tune cost functions to different tasks. We do so in this paper by using a tunable cost function {\lambda}{\gamma} with parameter {\gamma}. We show that higher values of {\gamma} place greater weight on larger pairwise differences, while lower values place greater weight on smaller pairwise differences. We demonstrate that training {\gamma} significantly improves the accuracy of both the DTW nearest neighbor and Proximity Forest classifiers.
Amercing: An Intuitive, Elegant and Effective Constraint for Dynamic Time Warping
Nov 26, 2021

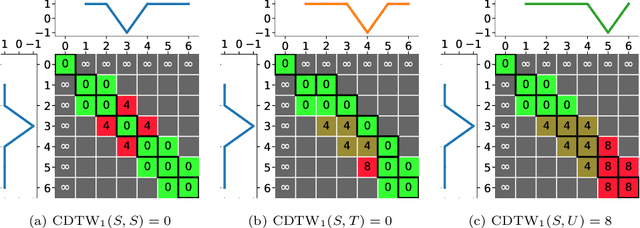
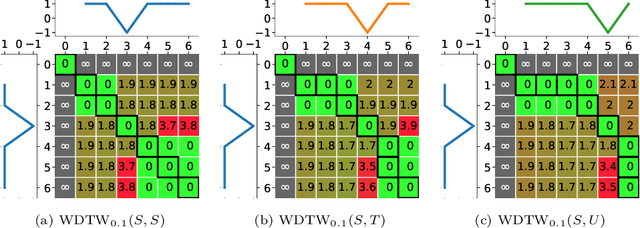
Dynamic Time Warping (DTW), and its constrained (CDTW) and weighted (WDTW) variants, are time series distances with a wide range of applications. They minimize the cost of non-linear alignments between series. CDTW and WDTW have been introduced because DTW is too permissive in its alignments. However, CDTW uses a crude step function, allowing unconstrained flexibility within the window, and none beyond it. WDTW's multiplicative weight is relative to the distances between aligned points along a warped path, rather than being a direct function of the amount of warping that is introduced. In this paper, we introduce Amerced Dynamic Time Warping (ADTW), a new, intuitive, DTW variant that penalizes the act of warping by a fixed additive cost. Like CDTW and WDTW, ADTW constrains the amount of warping. However, it avoids both abrupt discontinuities in the amount of warping allowed and the limitations of a multiplicative penalty. We formally introduce ADTW, prove some of its properties, and discuss its parameterization. We show on a simple example how it can be parameterized to achieve an intuitive outcome, and demonstrate its usefulness on a standard time series classification benchmark. We provide a demonstration application in C++.
Early Abandoning and Pruning for Elastic Distances
Feb 10, 2021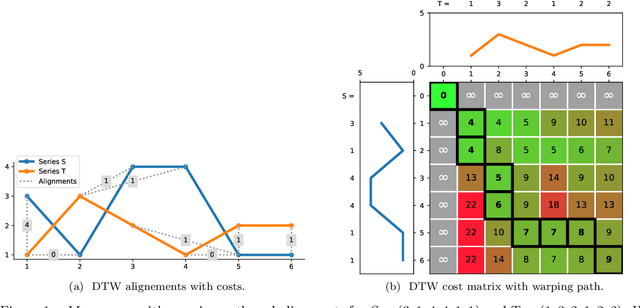
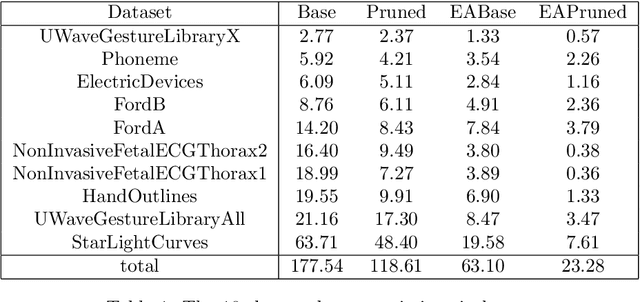
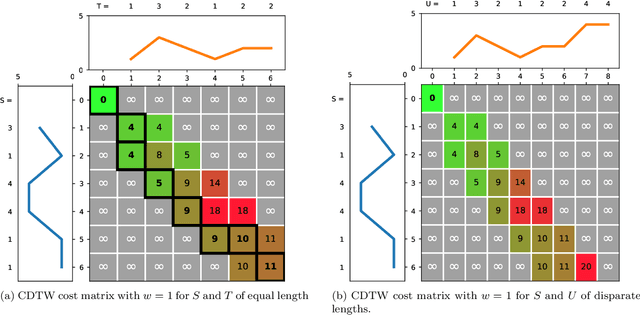
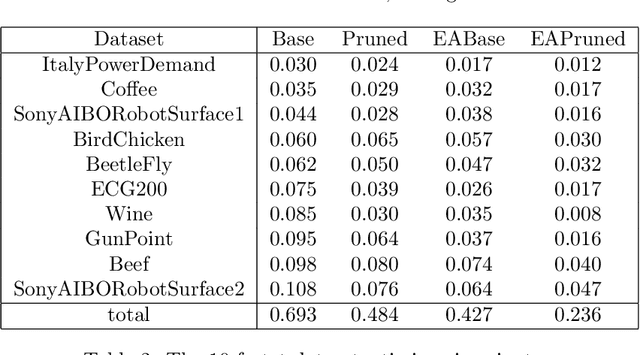
Elastic distances are key tools for time series analysis. Straightforward implementations require O(n2)space and time complexities, preventing many applications from scaling to long series. Much work hasbeen devoted in speeding up these applications, mostly with the development of lower bounds, allowing to avoid costly distance computations when a given threshold is exceeded. This threshold also allows to early abandon the computation of the distance itself. Another approach, developed for DTW, is to prune parts of the computation. All these techniques are orthogonal to each other. In this work, we develop a new generic strategy, "EAPruned", that tightly integrates pruning with early abandoning. We apply it to DTW, CDTW, WDTW, ERP, MSM and TWE, showing substantial speedup in NN1-like scenarios. Pruning also shows substantial speedup for some distances, benefiting applications such as clustering where all pairwise distances are required and hence early abandoning is not applicable. We release our implementation as part of a new C++ library for time series classification, along with easy to usePython/Numpy bindings.
Early Abandoning PrunedDTW and its application to similarity search
Oct 11, 2020


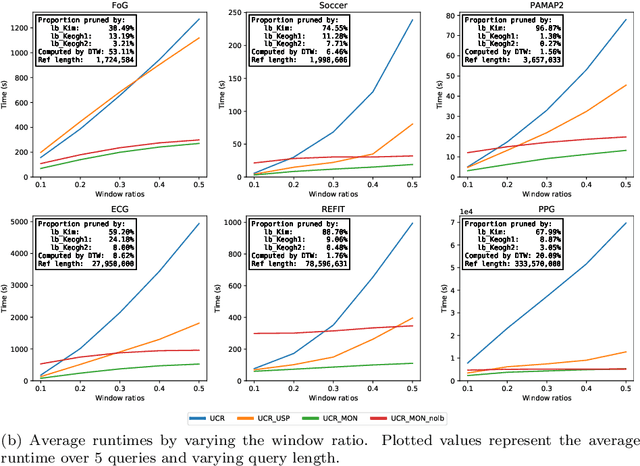
The Dynamic Time Warping ("DTW") distance is widely used in time series analysis, be it for classification, clustering or similarity search. However, its quadratic time complexity prevents it from scaling. Strategies, based on early abandoning DTW or skipping its computation altogether thanks to lower bounds, have been developed for certain use cases such as nearest neighbour search. But vectorization and approximation aside, no advance was made on DTW itself until recently with the introduction of PrunedDTW. This algorithm, able to prune unpromising alignments, was later fitted with early abandoning. We present a new version of PrunedDTW, "EAPrunedDTW", designed with early abandon in mind from the start, and able to early abandon faster than before. We show that EAPrunedDTW significantly improves the computation time of similarity search in the UCR Suite, and renders lower bounds dispensable.
BARD: A structured technique for group elicitation of Bayesian networks to support analytic reasoning
Mar 02, 2020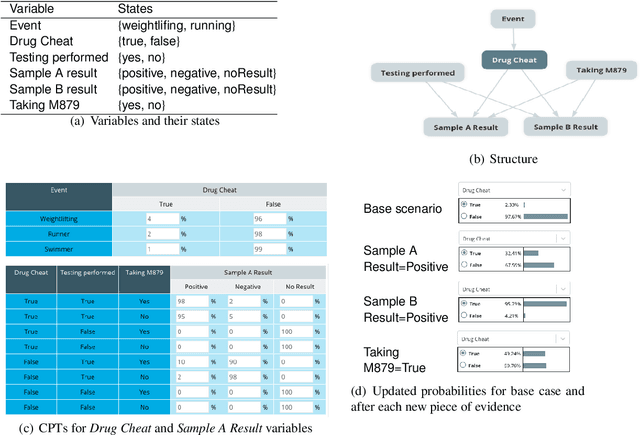
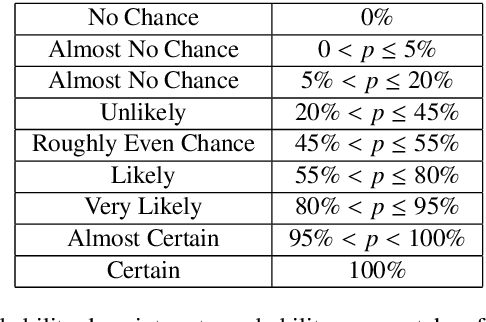
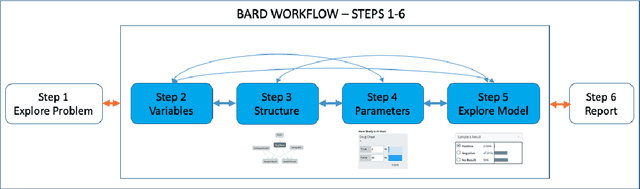
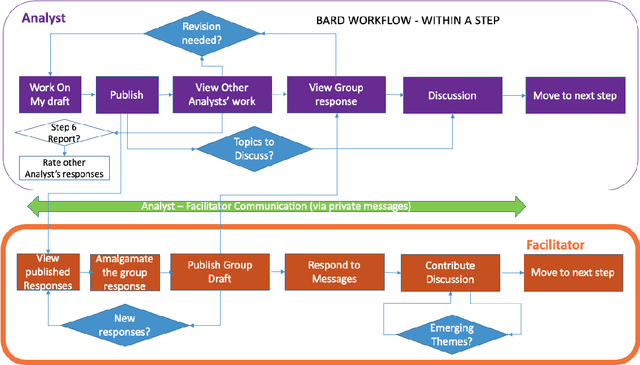
In many complex, real-world situations, problem solving and decision making require effective reasoning about causation and uncertainty. However, human reasoning in these cases is prone to confusion and error. Bayesian networks (BNs) are an artificial intelligence technology that models uncertain situations, supporting probabilistic and causal reasoning and decision making. However, to date, BN methodologies and software require significant upfront training, do not provide much guidance on the model building process, and do not support collaboratively building BNs. BARD (Bayesian ARgumentation via Delphi) is both a methodology and an expert system that utilises (1) BNs as the underlying structured representations for better argument analysis, (2) a multi-user web-based software platform and Delphi-style social processes to assist with collaboration, and (3) short, high-quality e-courses on demand, a highly structured process to guide BN construction, and a variety of helpful tools to assist in building and reasoning with BNs, including an automated explanation tool to assist effective report writing. The result is an end-to-end online platform, with associated online training, for groups without prior BN expertise to understand and analyse a problem, build a model of its underlying probabilistic causal structure, validate and reason with the causal model, and use it to produce a written analytic report. Initial experimental results demonstrate that BARD aids in problem solving, reasoning and collaboration.