 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser-centric Music Recommendations
May 16, 2025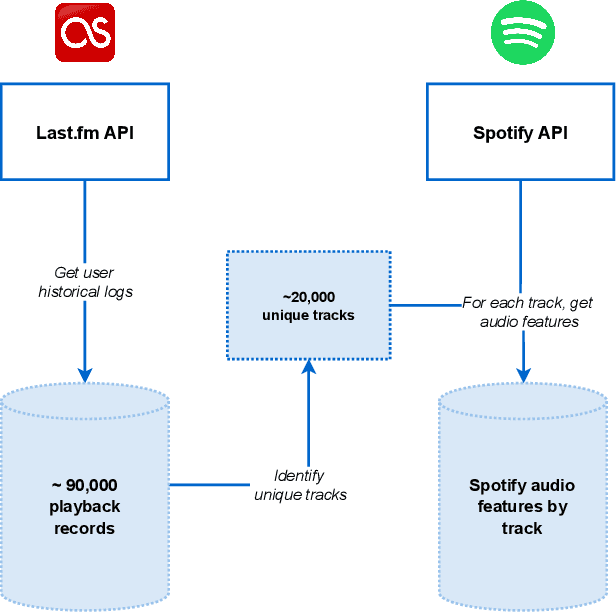



This work presents a user-centric recommendation framework, designed as a pipeline with four distinct, connected, and customizable phases. These phases are intended to improve explainability and boost user engagement. We have collected the historical Last.fm track playback records of a single user over approximately 15 years. The collected dataset includes more than 90,000 playbacks and approximately 14,000 unique tracks. From track playback records, we have created a dataset of user temporal contexts (each row is a specific moment when the user listened to certain music descriptors). As music descriptors, we have used community-contributed Last.fm tags and Spotify audio features. They represent the music that, throughout years, the user has been listening to. Next, given the most relevant Last.fm tags of a moment (e.g. the hour of the day), we predict the Spotify audio features that best fit the user preferences in that particular moment. Finally, we use the predicted audio features to find tracks similar to these features. The final aim is to recommend (and discover) tracks that the user may feel like listening to at a particular moment. For our initial study case, we have chosen to predict only a single audio feature target: danceability. The framework, however, allows to include more target variables. The ability to learn the musical habits from a single user can be quite powerful, and this framework could be extended to other users.
Causal knowledge engineering: A case study from COVID-19
Mar 21, 2024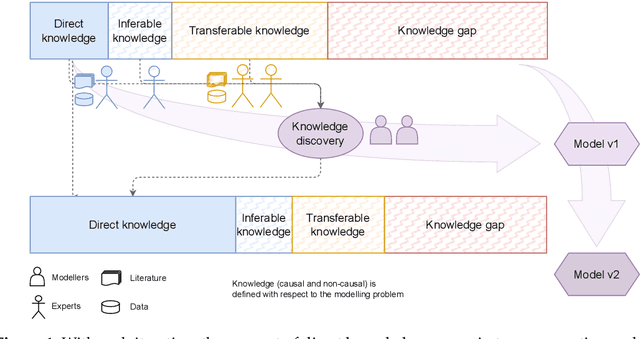
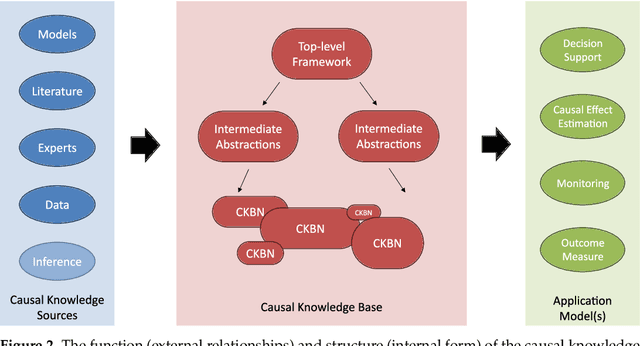
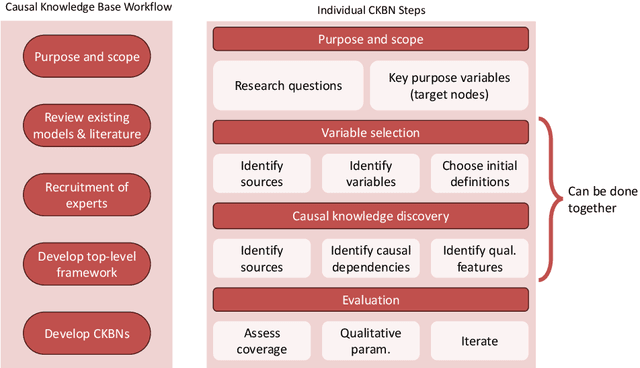
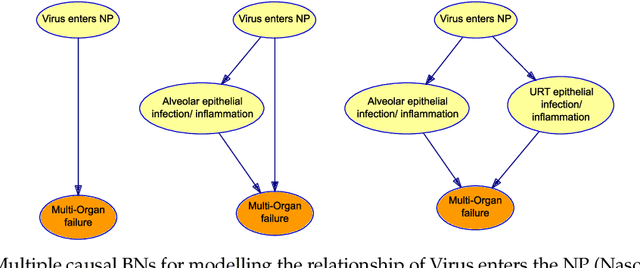
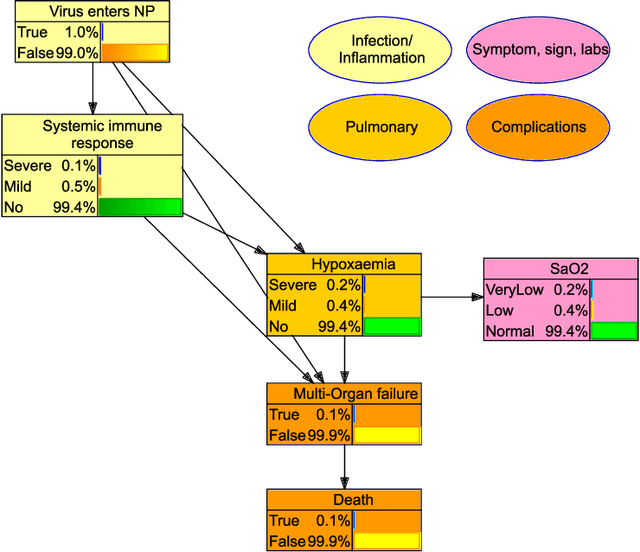
COVID-19 appeared abruptly in early 2020, requiring a rapid response amid a context of great uncertainty. Good quality data and knowledge was initially lacking, and many early models had to be developed with causal assumptions and estimations built in to supplement limited data, often with no reliable approach for identifying, validating and documenting these causal assumptions. Our team embarked on a knowledge engineering process to develop a causal knowledge base consisting of several causal BNs for diverse aspects of COVID-19. The unique challenges of the setting lead to experiments with the elicitation approach, and what emerged was a knowledge engineering method we call Causal Knowledge Engineering (CKE). The CKE provides a structured approach for building a causal knowledge base that can support the development of a variety of application-specific models. Here we describe the CKE method, and use our COVID-19 work as a case study to provide a detailed discussion and analysis of the method.
The practice of qualitative parameterisation in the development of Bayesian networks
Feb 20, 2024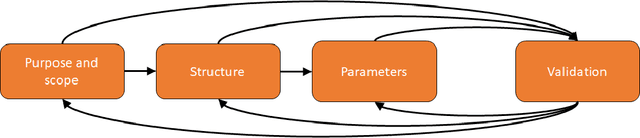
The typical phases of Bayesian network (BN) structured development include specification of purpose and scope, structure development, parameterisation and validation. Structure development is typically focused on qualitative issues and parameterisation quantitative issues, however there are qualitative and quantitative issues that arise in both phases. A common step that occurs after the initial structure has been developed is to perform a rough parameterisation that only captures and illustrates the intended qualitative behaviour of the model. This is done prior to a more rigorous parameterisation, ensuring that the structure is fit for purpose, as well as supporting later development and validation. In our collective experience and in discussions with other modellers, this step is an important part of the development process, but is under-reported in the literature. Since the practice focuses on qualitative issues, despite being quantitative in nature, we call this step qualitative parameterisation and provide an outline of its role in the BN development process.
BARD: A structured technique for group elicitation of Bayesian networks to support analytic reasoning
Mar 02, 2020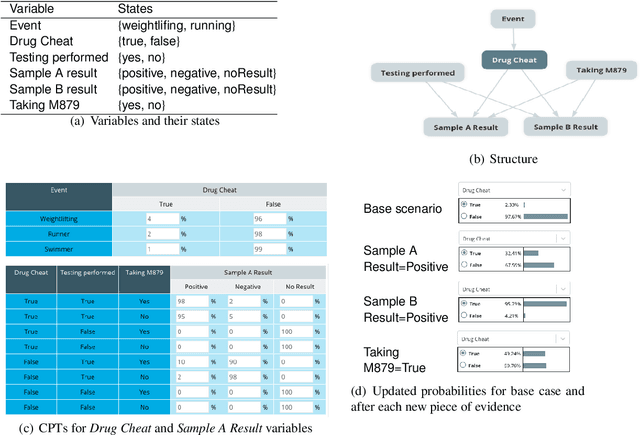
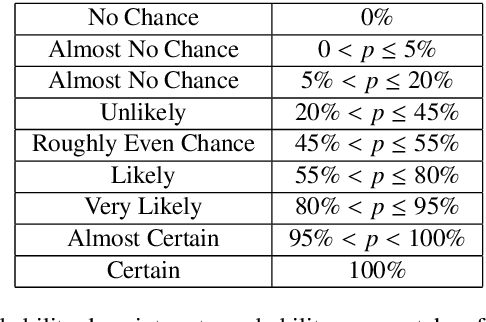
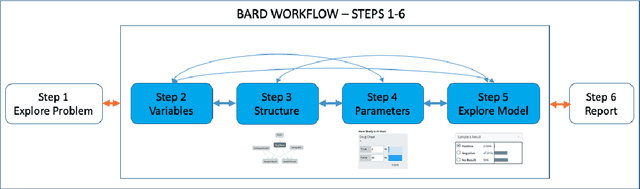
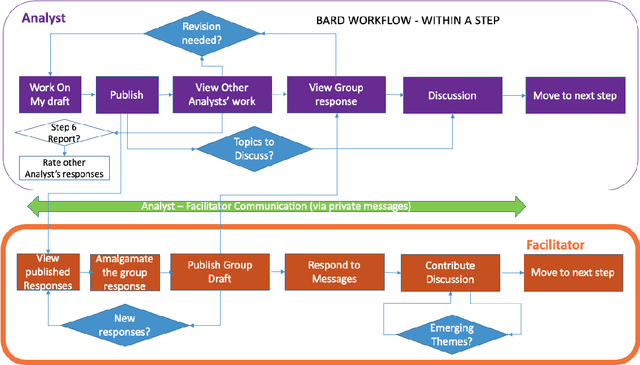
In many complex, real-world situations, problem solving and decision making require effective reasoning about causation and uncertainty. However, human reasoning in these cases is prone to confusion and error. Bayesian networks (BNs) are an artificial intelligence technology that models uncertain situations, supporting probabilistic and causal reasoning and decision making. However, to date, BN methodologies and software require significant upfront training, do not provide much guidance on the model building process, and do not support collaboratively building BNs. BARD (Bayesian ARgumentation via Delphi) is both a methodology and an expert system that utilises (1) BNs as the underlying structured representations for better argument analysis, (2) a multi-user web-based software platform and Delphi-style social processes to assist with collaboration, and (3) short, high-quality e-courses on demand, a highly structured process to guide BN construction, and a variety of helpful tools to assist in building and reasoning with BNs, including an automated explanation tool to assist effective report writing. The result is an end-to-end online platform, with associated online training, for groups without prior BN expertise to understand and analyse a problem, build a model of its underlying probabilistic causal structure, validate and reason with the causal model, and use it to produce a written analytic report. Initial experimental results demonstrate that BARD aids in problem solving, reasoning and collaboration.
Latent Variable Discovery Using Dependency Patterns
Jul 22, 2016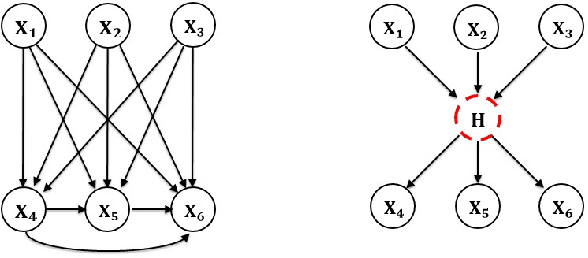


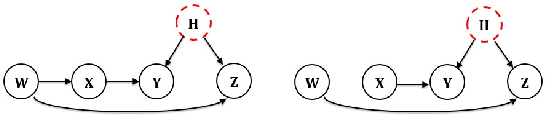
The causal discovery of Bayesian networks is an active and important research area, and it is based upon searching the space of causal models for those which can best explain a pattern of probabilistic dependencies shown in the data. However, some of those dependencies are generated by causal structures involving variables which have not been measured, i.e., latent variables. Some such patterns of dependency "reveal" themselves, in that no model based solely upon the observed variables can explain them as well as a model using a latent variable. That is what latent variable discovery is based upon. Here we did a search for finding them systematically, so that they may be applied in latent variable discovery in a more rigorous fashion.
Proximity-Based Non-uniform Abstractions for Approximate Planning
Jan 18, 2014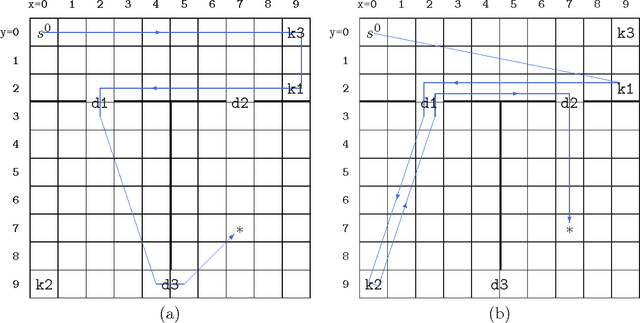


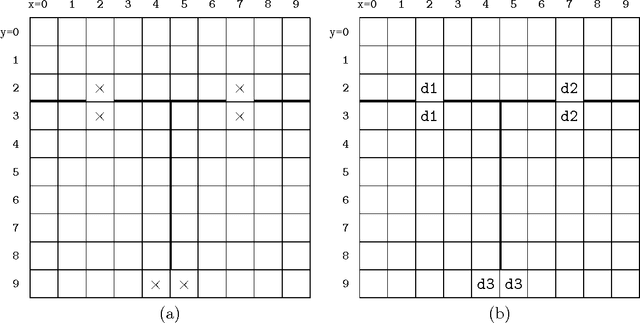
In a deterministic world, a planning agent can be certain of the consequences of its planned sequence of actions. Not so, however, in dynamic, stochastic domains where Markov decision processes are commonly used. Unfortunately these suffer from the curse of dimensionality: if the state space is a Cartesian product of many small sets (dimensions), planning is exponential in the number of those dimensions. Our new technique exploits the intuitive strategy of selectively ignoring various dimensions in different parts of the state space. The resulting non-uniformity has strong implications, since the approximation is no longer Markovian, requiring the use of a modified planner. We also use a spatial and temporal proximity measure, which responds to continued planning as well as movement of the agent through the state space, to dynamically adapt the abstraction as planning progresses. We present qualitative and quantitative results across a range of experimental domains showing that an agent exploiting this novel approximation method successfully finds solutions to the planning problem using much less than the full state space. We assess and analyse the features of domains which our method can exploit.