 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Brief Summary of Explanatory Virtues
Nov 22, 2024In this report, I provide a brief summary of the literature in philosophy, psychology and cognitive science about Explanatory Virtues, and link these concepts to eXplainable AI.
RENOVI: A Benchmark Towards Remediating Norm Violations in Socio-Cultural Conversations
Feb 17, 2024



Norm violations occur when individuals fail to conform to culturally accepted behaviors, which may lead to potential conflicts. Remediating norm violations requires social awareness and cultural sensitivity of the nuances at play. To equip interactive AI systems with a remediation ability, we offer ReNoVi - a large-scale corpus of 9,258 multi-turn dialogues annotated with social norms, as well as define a sequence of tasks to help understand and remediate norm violations step by step. ReNoVi consists of two parts: 512 human-authored dialogues (real data), and 8,746 synthetic conversations generated by ChatGPT through prompt learning. While collecting sufficient human-authored data is costly, synthetic conversations provide suitable amounts of data to help mitigate the scarcity of training data, as well as the chance to assess the alignment between LLMs and humans in the awareness of social norms. We thus harness the power of ChatGPT to generate synthetic training data for our task. To ensure the quality of both human-authored and synthetic data, we follow a quality control protocol during data collection. Our experimental results demonstrate the importance of remediating norm violations in socio-cultural conversations, as well as the improvement in performance obtained from synthetic data.
Let's Negotiate! A Survey of Negotiation Dialogue Systems
Feb 02, 2024
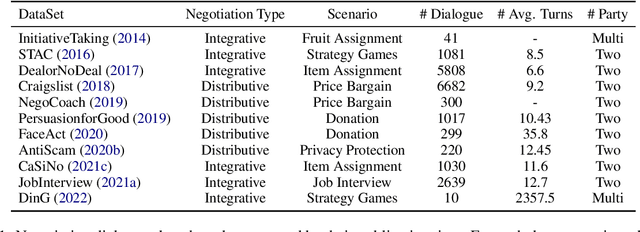


Negotiation is a crucial ability in human communication. Recently, there has been a resurgent research interest in negotiation dialogue systems, whose goal is to create intelligent agents that can assist people in resolving conflicts or reaching agreements. Although there have been many explorations into negotiation dialogue systems, a systematic review of this task has not been performed to date. We aim to fill this gap by investigating recent studies in the field of negotiation dialogue systems, and covering benchmarks, evaluations and methodologies within the literature. We also discuss potential future directions, including multi-modal, multi-party and cross-cultural negotiation scenarios. Our goal is to provide the community with a systematic overview of negotiation dialogue systems and to inspire future research.
SADAS: A Dialogue Assistant System Towards Remediating Norm Violations in Bilingual Socio-Cultural Conversations
Jan 29, 2024In today's globalized world, bridging the cultural divide is more critical than ever for forging meaningful connections. The Socially-Aware Dialogue Assistant System (SADAS) is our answer to this global challenge, and it's designed to ensure that conversations between individuals from diverse cultural backgrounds unfold with respect and understanding. Our system's novel architecture includes: (1) identifying the categories of norms present in the dialogue, (2) detecting potential norm violations, (3) evaluating the severity of these violations, (4) implementing targeted remedies to rectify the breaches, and (5) articulates the rationale behind these corrective actions. We employ a series of State-Of-The-Art (SOTA) techniques to build different modules, and conduct numerous experiments to select the most suitable backbone model for each of the modules. We also design a human preference experiment to validate the overall performance of the system. We will open-source our system (including source code, tools and applications), hoping to advance future research. A demo video of our system can be found at:~\url{https://youtu.be/JqetWkfsejk}. We have released our code and software at:~\url{https://github.com/AnonymousEACLDemo/SADAS}.
Turning Flowchart into Dialog: Plan-based Data Augmentation for Low-Resource Flowchart-grounded Troubleshooting Dialogs
May 10, 2023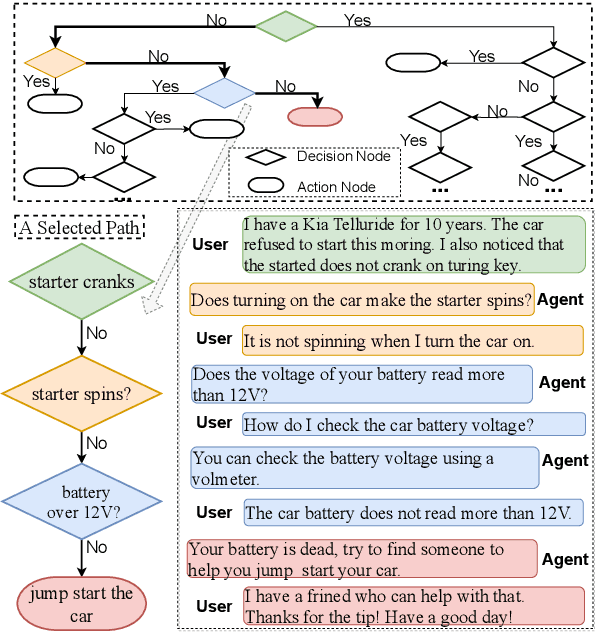
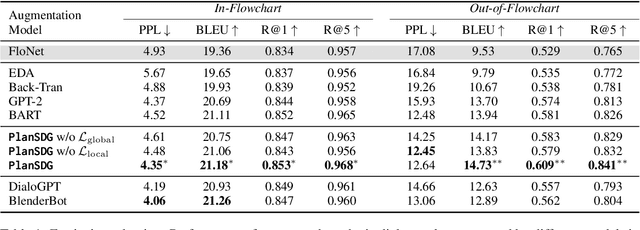
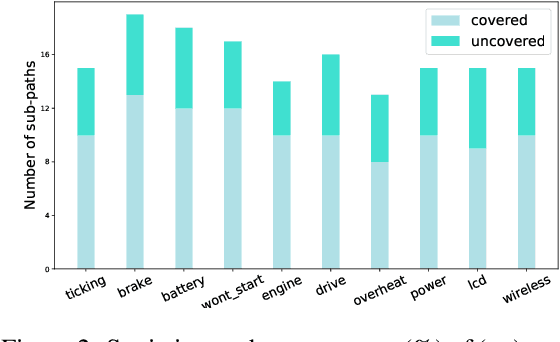

Flowchart-grounded troubleshooting dialogue (FTD) systems, which follow the instructions of a flowchart to diagnose users' problems in specific domains (eg., vehicle, laptop), have been gaining research interest in recent years. However, collecting sufficient dialogues that are naturally grounded on flowcharts is costly, thus FTD systems are impeded by scarce training data. To mitigate the data sparsity issue, we propose a plan-based data augmentation (PlanDA) approach that generates diverse synthetic dialog data at scale by transforming concise flowchart into dialogues. Specifically, its generative model employs a variational-base framework with a hierarchical planning strategy that includes global and local latent planning variables. Experiments on the FloDial dataset show that synthetic dialogue produced by PlanDA improves the performance of downstream tasks, including flowchart path retrieval and response generation, in particular on the Out-of-Flowchart settings. In addition, further analysis demonstrate the quality of synthetic data generated by PlanDA in paths that are covered by current sample dialogues and paths that are not covered.
SocialDial: A Benchmark for Socially-Aware Dialogue Systems
Apr 24, 2023



Dialogue systems have been widely applied in many scenarios and are now more powerful and ubiquitous than ever before. With large neural models and massive available data, current dialogue systems have access to more knowledge than any people in their life. However, current dialogue systems still do not perform at a human level. One major gap between conversational agents and humans lies in their abilities to be aware of social norms. The development of socially-aware dialogue systems is impeded due to the lack of resources. In this paper, we present the first socially-aware dialogue corpus - SocialDial, based on Chinese social culture. SocialDial consists of two parts: 1,563 multi-turn dialogues between two human speakers with fine-grained labels, and 4,870 synthetic conversations generated by ChatGPT. The human corpus covers five categories of social norms, which have 14 sub-categories in total. Specifically, it contains social factor annotations including social relation, context, social distance, and social norms. However, collecting sufficient socially-aware dialogues is costly. Thus, we harness the power of ChatGPT and devise an ontology-based synthetic data generation framework. This framework is able to generate synthetic data at scale. To ensure the quality of synthetic dialogues, we design several mechanisms for quality control during data collection. Finally, we evaluate our dataset using several pre-trained models, such as BERT and RoBERTa. Comprehensive empirical results based on state-of-the-art neural models demonstrate that modeling of social norms for dialogue systems is a promising research direction. To the best of our knowledge, SocialDial is the first socially-aware dialogue dataset that covers multiple social factors and has fine-grained labels.
BARD: A structured technique for group elicitation of Bayesian networks to support analytic reasoning
Mar 02, 2020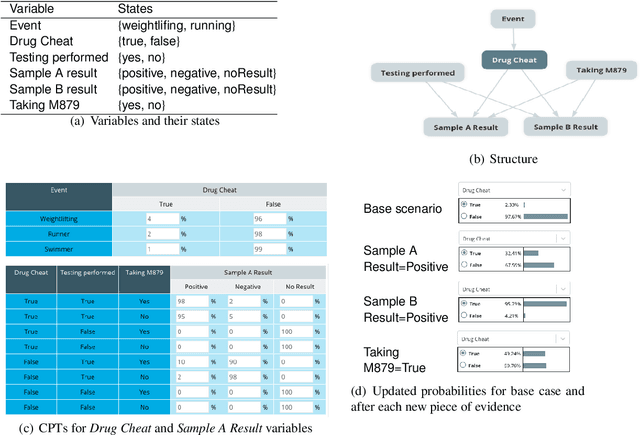
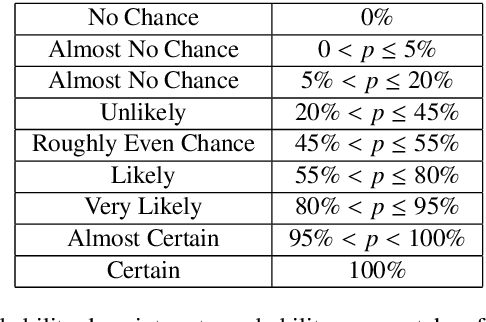
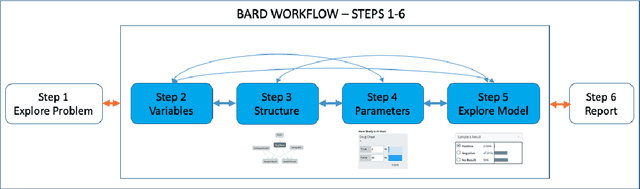
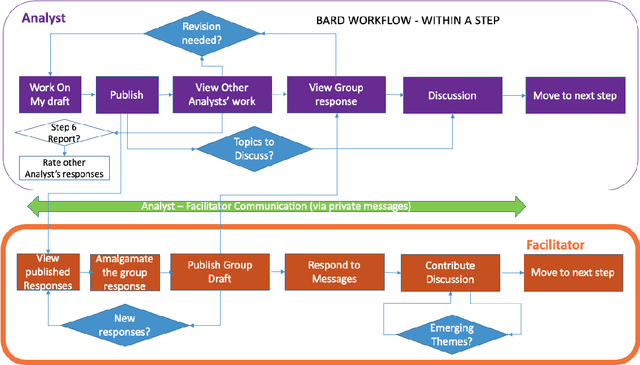
In many complex, real-world situations, problem solving and decision making require effective reasoning about causation and uncertainty. However, human reasoning in these cases is prone to confusion and error. Bayesian networks (BNs) are an artificial intelligence technology that models uncertain situations, supporting probabilistic and causal reasoning and decision making. However, to date, BN methodologies and software require significant upfront training, do not provide much guidance on the model building process, and do not support collaboratively building BNs. BARD (Bayesian ARgumentation via Delphi) is both a methodology and an expert system that utilises (1) BNs as the underlying structured representations for better argument analysis, (2) a multi-user web-based software platform and Delphi-style social processes to assist with collaboration, and (3) short, high-quality e-courses on demand, a highly structured process to guide BN construction, and a variety of helpful tools to assist in building and reasoning with BNs, including an automated explanation tool to assist effective report writing. The result is an end-to-end online platform, with associated online training, for groups without prior BN expertise to understand and analyse a problem, build a model of its underlying probabilistic causal structure, validate and reason with the causal model, and use it to produce a written analytic report. Initial experimental results demonstrate that BARD aids in problem solving, reasoning and collaboration.
Exploring Textual and Speech information in Dialogue Act Classification with Speaker Domain Adaptation
Oct 17, 2018
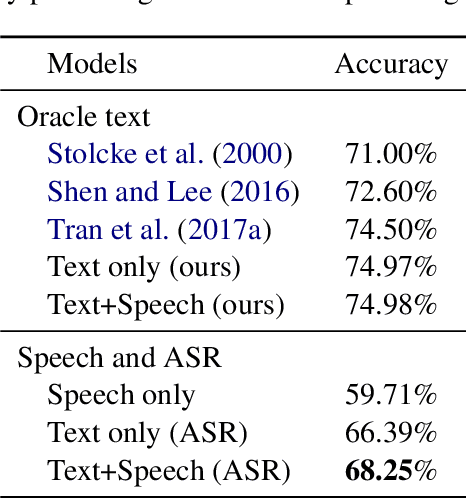
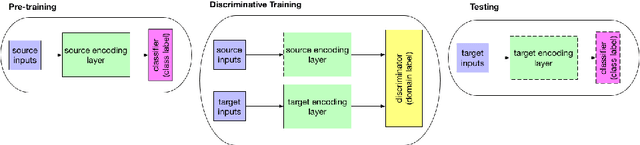

In spite of the recent success of Dialogue Act (DA) classification, the majority of prior works focus on text-based classification with oracle transcriptions, i.e. human transcriptions, instead of Automatic Speech Recognition (ASR)'s transcriptions. In spoken dialog systems, however, the agent would only have access to noisy ASR transcriptions, which may further suffer performance degradation due to domain shift. In this paper, we explore the effectiveness of using both acoustic and textual signals, either oracle or ASR transcriptions, and investigate speaker domain adaptation for DA classification. Our multimodal model proves to be superior to the unimodal models, particularly when the oracle transcriptions are not available. We also propose an effective method for speaker domain adaptation, which achieves competitive results.
Strategies for Generating Micro Explanations for Bayesian Belief Networks
Mar 27, 2013Bayesian Belief Networks have been largely overlooked by Expert Systems practitioners on the grounds that they do not correspond to the human inference mechanism. In this paper, we introduce an explanation mechanism designed to generate intuitive yet probabilistically sound explanations of inferences drawn by a Bayesian Belief Network. In particular, our mechanism accounts for the results obtained due to changes in the causal and the evidential support of a node.
Handling Uncertainty during Plan Recognition in Task-Oriented Consultation Systems
Mar 20, 2013During interactions with human consultants, people are used to providing partial and/or inaccurate information, and still be understood and assisted. We attempt to emulate this capability of human consultants; in computer consultation systems. In this paper, we present a mechanism for handling uncertainty in plan recognition during task-oriented consultations. The uncertainty arises while choosing an appropriate interpretation of a user?s statements among many possible interpretations. Our mechanism handles this uncertainty by using probability theory to assess the probabilities of the interpretations, and complements this assessment by taking into account the information content of the interpretations. The information content of an interpretation is a measure of how well defined an interpretation is in terms of the actions to be performed on the basis of the interpretation. This measure is used to guide the inference process towards interpretations with a higher information content. The information content for an interpretation depends on the specificity and the strength of the inferences in it, where the strength of an inference depends on the reliability of the information on which the inference is based. Our mechanism has been developed for use in task-oriented consultation systems. The domain that we have chosen for exploration is that of a travel agency.