 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Application of Large Language Models to Coding Negotiation Transcripts
Jul 18, 2024
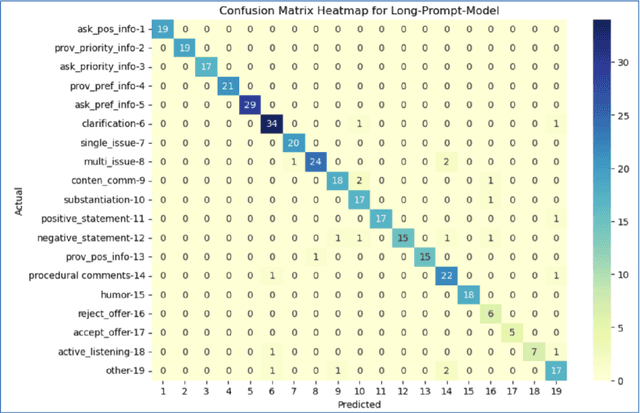
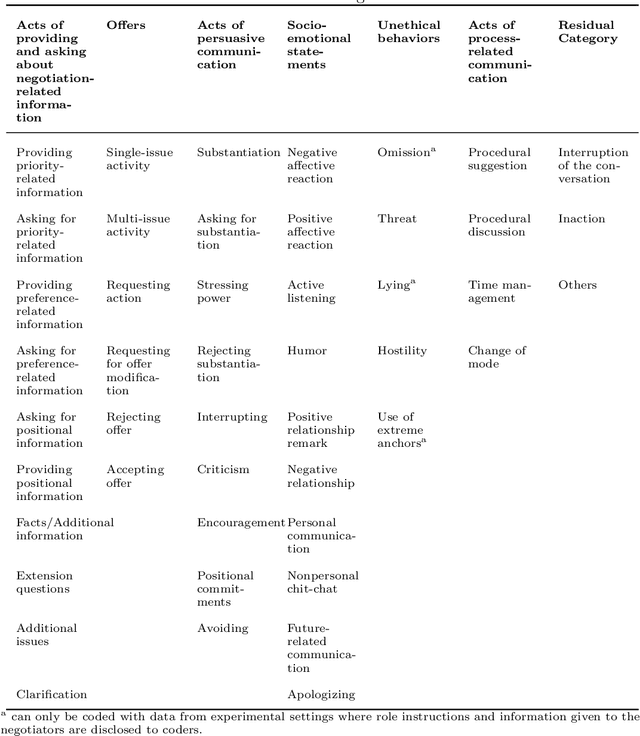
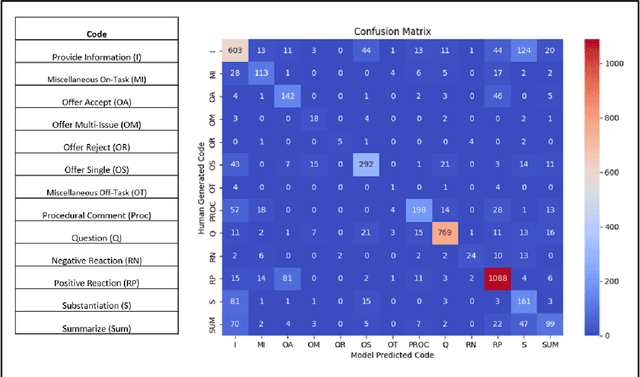
In recent years, Large Language Models (LLM) have demonstrated impressive capabilities in the field of natural language processing (NLP). This paper explores the application of LLMs in negotiation transcript analysis by the Vanderbilt AI Negotiation Lab. Starting in September 2022, we applied multiple strategies using LLMs from zero shot learning to fine tuning models to in-context learning). The final strategy we developed is explained, along with how to access and use the model. This study provides a sense of both the opportunities and roadblocks for the implementation of LLMs in real life applications and offers a model for how LLMs can be applied to coding in other fields.
SADAS: A Dialogue Assistant System Towards Remediating Norm Violations in Bilingual Socio-Cultural Conversations
Jan 29, 2024In today's globalized world, bridging the cultural divide is more critical than ever for forging meaningful connections. The Socially-Aware Dialogue Assistant System (SADAS) is our answer to this global challenge, and it's designed to ensure that conversations between individuals from diverse cultural backgrounds unfold with respect and understanding. Our system's novel architecture includes: (1) identifying the categories of norms present in the dialogue, (2) detecting potential norm violations, (3) evaluating the severity of these violations, (4) implementing targeted remedies to rectify the breaches, and (5) articulates the rationale behind these corrective actions. We employ a series of State-Of-The-Art (SOTA) techniques to build different modules, and conduct numerous experiments to select the most suitable backbone model for each of the modules. We also design a human preference experiment to validate the overall performance of the system. We will open-source our system (including source code, tools and applications), hoping to advance future research. A demo video of our system can be found at:~\url{https://youtu.be/JqetWkfsejk}. We have released our code and software at:~\url{https://github.com/AnonymousEACLDemo/SADAS}.
SocialDial: A Benchmark for Socially-Aware Dialogue Systems
Apr 24, 2023



Dialogue systems have been widely applied in many scenarios and are now more powerful and ubiquitous than ever before. With large neural models and massive available data, current dialogue systems have access to more knowledge than any people in their life. However, current dialogue systems still do not perform at a human level. One major gap between conversational agents and humans lies in their abilities to be aware of social norms. The development of socially-aware dialogue systems is impeded due to the lack of resources. In this paper, we present the first socially-aware dialogue corpus - SocialDial, based on Chinese social culture. SocialDial consists of two parts: 1,563 multi-turn dialogues between two human speakers with fine-grained labels, and 4,870 synthetic conversations generated by ChatGPT. The human corpus covers five categories of social norms, which have 14 sub-categories in total. Specifically, it contains social factor annotations including social relation, context, social distance, and social norms. However, collecting sufficient socially-aware dialogues is costly. Thus, we harness the power of ChatGPT and devise an ontology-based synthetic data generation framework. This framework is able to generate synthetic data at scale. To ensure the quality of synthetic dialogues, we design several mechanisms for quality control during data collection. Finally, we evaluate our dataset using several pre-trained models, such as BERT and RoBERTa. Comprehensive empirical results based on state-of-the-art neural models demonstrate that modeling of social norms for dialogue systems is a promising research direction. To the best of our knowledge, SocialDial is the first socially-aware dialogue dataset that covers multiple social factors and has fine-grained labels.