 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLePREC: Reasoning as Classification over Structured Factors for Assessing Relevance of Legal Issues
Apr 21, 2026More than half of the global population struggles to meet their civil justice needs due to limited legal resources. While Large Language Models (LLMs) have demonstrated impressive reasoning capabilities, significant challenges remain even at the foundational step of legal issue identification. To investigate LLMs' capabilities in this task, we constructed a dataset from 769 real-world Malaysian Contract Act court cases, using GPT-4o to extract facts and generate candidate legal issues, annotated by senior legal experts, which reveals a critical limitation: while LLMs generate diverse issue candidates, their precision remains inadequate (GPT-4o achieves only 62%). To address this gap, we propose LePREC (Legal Professional-inspired Reasoning Elicitation and Classification), a neuro-symbolic framework combining neural generation with structured statistical reasoning. LePREC consists of: (1) a neuro component leverages LLMs to transform legal descriptions into question-answer pairs representing diverse analytical factors, and (2) a symbolic component applies sparse linear models over these discrete features, learning explicit algebraic weights that identify the most informative reasoning factors. Unlike end-to-end neural approaches, LePREC achieves interpretability through transparent feature weighting while maintaining data efficiency through correlation-based statistical classification. Experiments show a 30-40% improvement over advanced LLM baselines, including GPT-4o and Claude, confirming that correlation-based factor-issue analysis offers a more data-efficient solution for relevance decisions.
DialogXpert: Driving Intelligent and Emotion-Aware Conversations through Online Value-Based Reinforcement Learning with LLM Priors
May 23, 2025Large-language-model (LLM) agents excel at reactive dialogue but struggle with proactive, goal-driven interactions due to myopic decoding and costly planning. We introduce DialogXpert, which leverages a frozen LLM to propose a small, high-quality set of candidate actions per turn and employs a compact Q-network over fixed BERT embeddings trained via temporal-difference learning to select optimal moves within this reduced space. By tracking the user's emotions, DialogXpert tailors each decision to advance the task while nurturing a genuine, empathetic connection. Across negotiation, emotional support, and tutoring benchmarks, DialogXpert drives conversations to under $3$ turns with success rates exceeding 94\% and, with a larger LLM prior, pushes success above 97\% while markedly improving negotiation outcomes. This framework delivers real-time, strategic, and emotionally intelligent dialogue planning at scale. Code available at https://github.com/declare-lab/dialogxpert/
ACCESS : A Benchmark for Abstract Causal Event Discovery and Reasoning
Feb 12, 2025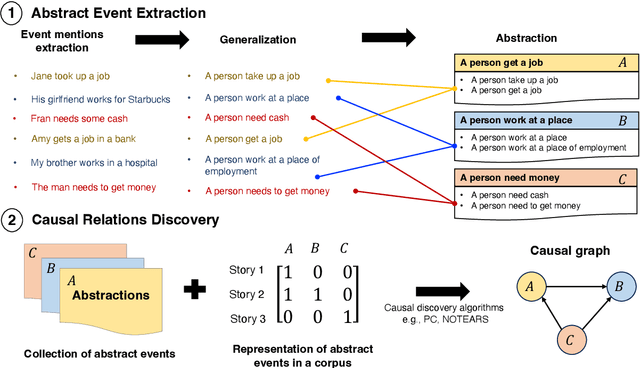

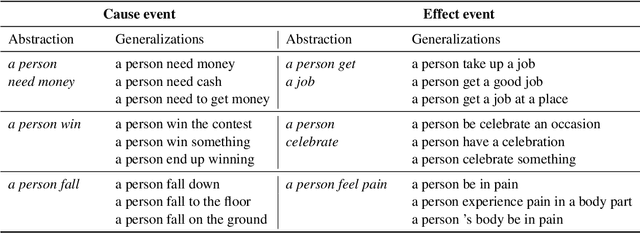
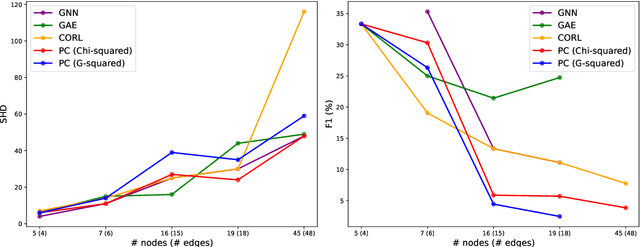
Identifying cause-and-effect relationships is critical to understanding real-world dynamics and ultimately causal reasoning. Existing methods for identifying event causality in NLP, including those based on Large Language Models (LLMs), exhibit difficulties in out-of-distribution settings due to the limited scale and heavy reliance on lexical cues within available benchmarks. Modern benchmarks, inspired by probabilistic causal inference, have attempted to construct causal graphs of events as a robust representation of causal knowledge, where \texttt{CRAB} \citep{romanou2023crab} is one such recent benchmark along this line. In this paper, we introduce \texttt{ACCESS}, a benchmark designed for discovery and reasoning over abstract causal events. Unlike existing resources, \texttt{ACCESS} focuses on causality of everyday life events on the abstraction level. We propose a pipeline for identifying abstractions for event generalizations from \texttt{GLUCOSE} \citep{mostafazadeh-etal-2020-glucose}, a large-scale dataset of implicit commonsense causal knowledge, from which we subsequently extract $1,4$K causal pairs. Our experiments highlight the ongoing challenges of using statistical methods and/or LLMs for automatic abstraction identification and causal discovery in NLP. Nonetheless, we demonstrate that the abstract causal knowledge provided in \texttt{ACCESS} can be leveraged for enhancing QA reasoning performance in LLMs.
Bridging the Gap: Transfer Learning from English PLMs to Malaysian English
Jul 01, 2024Malaysian English is a low resource creole language, where it carries the elements of Malay, Chinese, and Tamil languages, in addition to Standard English. Named Entity Recognition (NER) models underperform when capturing entities from Malaysian English text due to its distinctive morphosyntactic adaptations, semantic features and code-switching (mixing English and Malay). Considering these gaps, we introduce MENmBERT and MENBERT, a pre-trained language model with contextual understanding, specifically tailored for Malaysian English. We have fine-tuned MENmBERT and MENBERT using manually annotated entities and relations from the Malaysian English News Article (MEN) Dataset. This fine-tuning process allows the PLM to learn representations that capture the nuances of Malaysian English relevant for NER and RE tasks. MENmBERT achieved a 1.52\% and 26.27\% improvement on NER and RE tasks respectively compared to the bert-base-multilingual-cased model. Although the overall performance of NER does not have a significant improvement, our further analysis shows that there is a significant improvement when evaluated by the 12 entity labels. These findings suggest that pre-training language models on language-specific and geographically-focused corpora can be a promising approach for improving NER performance in low-resource settings. The dataset and code published in this paper provide valuable resources for NLP research work focusing on Malaysian English.
Bridging Law and Data: Augmenting Reasoning via a Semi-Structured Dataset with IRAC methodology
Jun 19, 2024The effectiveness of Large Language Models (LLMs) in legal reasoning is often limited due to the unique legal terminologies and the necessity for highly specialized knowledge. These limitations highlight the need for high-quality data tailored for complex legal reasoning tasks. This paper introduces LEGALSEMI, a benchmark specifically curated for legal scenario analysis. LEGALSEMI comprises 54 legal scenarios, each rigorously annotated by legal experts, based on the comprehensive IRAC (Issue, Rule, Application, Conclusion) framework. In addition, LEGALSEMI is accompanied by a structured knowledge graph (SKG). A series of experiments were conducted to assess the usefulness of LEGALSEMI for IRAC analysis. The experimental results demonstrate the effectiveness of incorporating the SKG for issue identification, rule retrieval, application and conclusion generation using four different LLMs. LEGALSEMI will be publicly available upon acceptance of this paper.
Malaysian English News Decoded: A Linguistic Resource for Named Entity and Relation Extraction
Feb 22, 2024Standard English and Malaysian English exhibit notable differences, posing challenges for natural language processing (NLP) tasks on Malaysian English. Unfortunately, most of the existing datasets are mainly based on standard English and therefore inadequate for improving NLP tasks in Malaysian English. An experiment using state-of-the-art Named Entity Recognition (NER) solutions on Malaysian English news articles highlights that they cannot handle morphosyntactic variations in Malaysian English. To the best of our knowledge, there is no annotated dataset available to improvise the model. To address these issues, we constructed a Malaysian English News (MEN) dataset, which contains 200 news articles that are manually annotated with entities and relations. We then fine-tuned the spaCy NER tool and validated that having a dataset tailor-made for Malaysian English could improve the performance of NER in Malaysian English significantly. This paper presents our effort in the data acquisition, annotation methodology, and thorough analysis of the annotated dataset. To validate the quality of the annotation, inter-annotator agreement was used, followed by adjudication of disagreements by a subject matter expert. Upon completion of these tasks, we managed to develop a dataset with 6,061 entities and 3,268 relation instances. Finally, we discuss on spaCy fine-tuning setup and analysis on the NER performance. This unique dataset will contribute significantly to the advancement of NLP research in Malaysian English, allowing researchers to accelerate their progress, particularly in NER and relation extraction. The dataset and annotation guideline has been published on Github.
RENOVI: A Benchmark Towards Remediating Norm Violations in Socio-Cultural Conversations
Feb 17, 2024



Norm violations occur when individuals fail to conform to culturally accepted behaviors, which may lead to potential conflicts. Remediating norm violations requires social awareness and cultural sensitivity of the nuances at play. To equip interactive AI systems with a remediation ability, we offer ReNoVi - a large-scale corpus of 9,258 multi-turn dialogues annotated with social norms, as well as define a sequence of tasks to help understand and remediate norm violations step by step. ReNoVi consists of two parts: 512 human-authored dialogues (real data), and 8,746 synthetic conversations generated by ChatGPT through prompt learning. While collecting sufficient human-authored data is costly, synthetic conversations provide suitable amounts of data to help mitigate the scarcity of training data, as well as the chance to assess the alignment between LLMs and humans in the awareness of social norms. We thus harness the power of ChatGPT to generate synthetic training data for our task. To ensure the quality of both human-authored and synthetic data, we follow a quality control protocol during data collection. Our experimental results demonstrate the importance of remediating norm violations in socio-cultural conversations, as well as the improvement in performance obtained from synthetic data.
How well ChatGPT understand Malaysian English? An Evaluation on Named Entity Recognition and Relation Extraction
Nov 20, 2023Recently, ChatGPT has attracted a lot of interest from both researchers and the general public. While the performance of ChatGPT in named entity recognition and relation extraction from Standard English texts is satisfactory, it remains to be seen if it can perform similarly for Malaysian English. Malaysian English is unique as it exhibits morphosyntactic and semantical adaptation from local contexts. In this study, we assess ChatGPT's capability in extracting entities and relations from the Malaysian English News (MEN) dataset. We propose a three-step methodology referred to as \textbf{\textit{educate-predict-evaluate}}. The performance of ChatGPT is assessed using F1-Score across 18 unique prompt settings, which were carefully engineered for a comprehensive review. From our evaluation, we found that ChatGPT does not perform well in extracting entities from Malaysian English news articles, with the highest F1-Score of 0.497. Further analysis shows that the morphosyntactic adaptation in Malaysian English caused the limitation. However, interestingly, this morphosyntactic adaptation does not impact the performance of ChatGPT for relation extraction.
Can ChatGPT Perform Reasoning Using the IRAC Method in Analyzing Legal Scenarios Like a Lawyer?
Nov 03, 2023



Large Language Models (LLMs), such as ChatGPT, have drawn a lot of attentions recently in the legal domain due to its emergent ability to tackle a variety of legal tasks. However, it is still unknown if LLMs are able to analyze a legal case and perform reasoning in the same manner as lawyers. Therefore, we constructed a novel corpus consisting of scenarios pertain to Contract Acts Malaysia and Australian Social Act for Dependent Child. ChatGPT is applied to perform analysis on the corpus using the IRAC method, which is a framework widely used by legal professionals for organizing legal analysis. Each scenario in the corpus is annotated with a complete IRAC analysis in a semi-structured format so that both machines and legal professionals are able to interpret and understand the annotations. In addition, we conducted the first empirical assessment of ChatGPT for IRAC analysis in order to understand how well it aligns with the analysis of legal professionals. Our experimental results shed lights on possible future research directions to improve alignments between LLMs and legal experts in terms of legal reasoning.
SocialDial: A Benchmark for Socially-Aware Dialogue Systems
Apr 24, 2023



Dialogue systems have been widely applied in many scenarios and are now more powerful and ubiquitous than ever before. With large neural models and massive available data, current dialogue systems have access to more knowledge than any people in their life. However, current dialogue systems still do not perform at a human level. One major gap between conversational agents and humans lies in their abilities to be aware of social norms. The development of socially-aware dialogue systems is impeded due to the lack of resources. In this paper, we present the first socially-aware dialogue corpus - SocialDial, based on Chinese social culture. SocialDial consists of two parts: 1,563 multi-turn dialogues between two human speakers with fine-grained labels, and 4,870 synthetic conversations generated by ChatGPT. The human corpus covers five categories of social norms, which have 14 sub-categories in total. Specifically, it contains social factor annotations including social relation, context, social distance, and social norms. However, collecting sufficient socially-aware dialogues is costly. Thus, we harness the power of ChatGPT and devise an ontology-based synthetic data generation framework. This framework is able to generate synthetic data at scale. To ensure the quality of synthetic dialogues, we design several mechanisms for quality control during data collection. Finally, we evaluate our dataset using several pre-trained models, such as BERT and RoBERTa. Comprehensive empirical results based on state-of-the-art neural models demonstrate that modeling of social norms for dialogue systems is a promising research direction. To the best of our knowledge, SocialDial is the first socially-aware dialogue dataset that covers multiple social factors and has fine-grained labels.