 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge'Finance Wizard' at the FinLLM Challenge Task: Financial Text Summarization
Aug 07, 2024



This paper presents our participation under the team name `Finance Wizard' in the FinNLP-AgentScen 2024 shared task #2: Financial Text Summarization. It documents our pipeline approach of fine-tuning a foundation model into a task-specific model for Financial Text Summarization. It involves (1) adapting Llama3 8B, a foundation model, to the Finance domain via continued pre-training, (2) multi-task instruction-tuning to further equip the model with more finance-related capabilities, (3) finally fine-tuning the model into a task-specific `expert'. Our model, FinLlama3\_sum, yielded commendable results, securing the third position in its category with a ROUGE-1 score of 0.521.
Crude Oil-related Events Extraction and Processing: A Transfer Learning Approach
May 01, 2022


One of the challenges in event extraction via traditional supervised learning paradigm is the need for a sizeable annotated dataset to achieve satisfactory model performance. It is even more challenging when it comes to event extraction in the finance and economics domain, a domain with considerably fewer resources. This paper presents a complete framework for extracting and processing crude oil-related events found in CrudeOilNews corpus, addressing the issue of annotation scarcity and class imbalance by leveraging on the effectiveness of transfer learning. Apart from event extraction, we place special emphasis on event properties (Polarity, Modality, and Intensity) classification to determine the factual certainty of each event. We build baseline models first by supervised learning and then exploit Transfer Learning methods to boost event extraction model performance despite the limited amount of annotated data and severe class imbalance. This is done via methods within the transfer learning framework such as Domain Adaptive Pre-training, Multi-task Learning and Sequential Transfer Learning. Based on experiment results, we are able to improve all event extraction sub-task models both in F1 and MCC1-score as compared to baseline models trained via the standard supervised learning. Accurate and holistic event extraction from crude oil news is very useful for downstream tasks such as understanding event chains and learning event-event relations, which can be used for other downstream tasks such as commodity price prediction, summarisation, etc. to support a wide range of business decision making.
CrudeOilNews: An Annotated Crude Oil News Corpus for Event Extraction
Apr 08, 2022
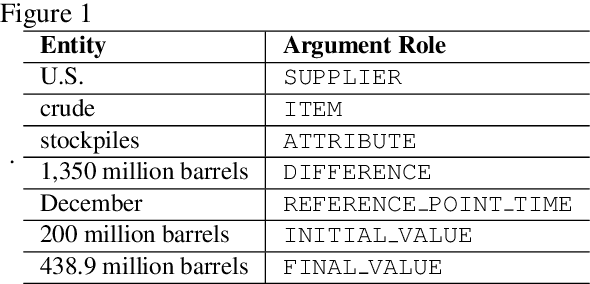
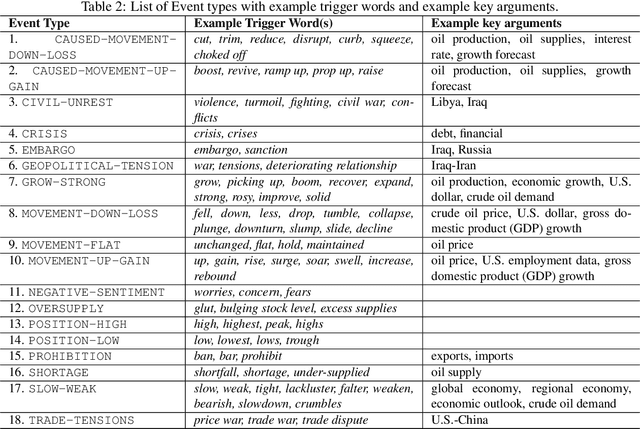
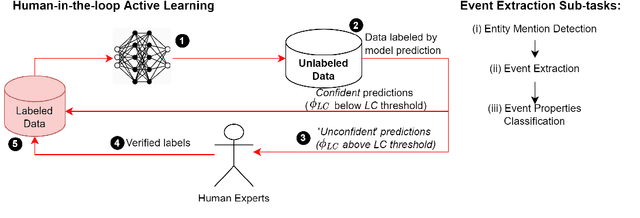
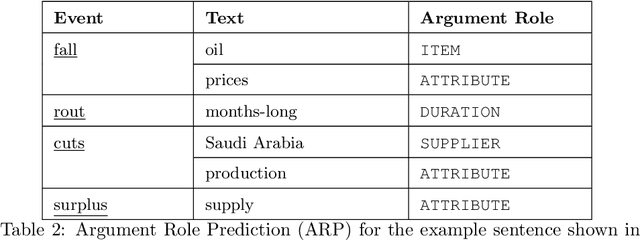
In this paper, we present CrudeOilNews, a corpus of English Crude Oil news for event extraction. It is the first of its kind for Commodity News and serve to contribute towards resource building for economic and financial text mining. This paper describes the data collection process, the annotation methodology and the event typology used in producing the corpus. Firstly, a seed set of 175 news articles were manually annotated, of which a subset of 25 news were used as the adjudicated reference test set for inter-annotator and system evaluation. Agreement was generally substantial and annotator performance was adequate, indicating that the annotation scheme produces consistent event annotations of high quality. Subsequently the dataset is expanded through (1) data augmentation and (2) Human-in-the-loop active learning. The resulting corpus has 425 news articles with approximately 11k events annotated. As part of active learning process, the corpus was used to train basic event extraction models for machine labeling, the resulting models also serve as a validation or as a pilot study demonstrating the use of the corpus in machine learning purposes. The annotated corpus is made available for academic research purpose at https://github.com/meisin/CrudeOilNews-Corpus.
Effective Use of Graph Convolution Network and Contextual Sub-Tree forCommodity News Event Extraction
Sep 27, 2021



Event extraction in commodity news is a less researched area as compared to generic event extraction. However, accurate event extraction from commodity news is useful in abroad range of applications such as under-standing event chains and learning event-event relations, which can then be used for commodity price prediction. The events found in commodity news exhibit characteristics different from generic events, hence posing a unique challenge in event extraction using existing methods. This paper proposes an effective use of Graph Convolutional Networks(GCN) with a pruned dependency parse tree, termed contextual sub-tree, for better event ex-traction in commodity news. The event ex-traction model is trained using feature embed-dings from ComBERT, a BERT-based masked language model that was produced through domain-adaptive pre-training on a commodity news corpus. Experimental results show the efficiency of the proposed solution, which out-performs existing methods with F1 scores as high as 0.90. Furthermore, our pre-trained language model outperforms GloVe by 23%, and BERT and RoBERTa by 7% in terms of argument roles classification. For the goal of re-producibility, the code and trained models are made publicly available1.
The Commodities News Corpus: A Resource forUnderstanding Commodity News Better
May 23, 2021
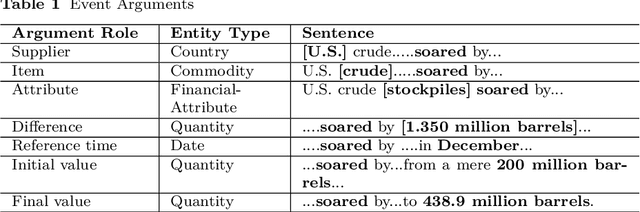


Commodity News contains a wealth of information such as sum-mary of the recent commodity price movement and notable events that led tothe movement. Through event extraction, useful information extracted fromcommodity news is extremely useful in mining for causal relation betweenevents and commodity price movement, which can be used for commodity priceprediction. To facilitate the future research, we introduce a new dataset withthe following information identified and annotated: (i) entities (both nomi-nal and named), (ii) events (trigger words and argument roles), (iii) eventmetadata: modality, polarity and intensity and (iv) event-event relations.