 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogXpert: Driving Intelligent and Emotion-Aware Conversations through Online Value-Based Reinforcement Learning with LLM Priors
May 23, 2025Large-language-model (LLM) agents excel at reactive dialogue but struggle with proactive, goal-driven interactions due to myopic decoding and costly planning. We introduce DialogXpert, which leverages a frozen LLM to propose a small, high-quality set of candidate actions per turn and employs a compact Q-network over fixed BERT embeddings trained via temporal-difference learning to select optimal moves within this reduced space. By tracking the user's emotions, DialogXpert tailors each decision to advance the task while nurturing a genuine, empathetic connection. Across negotiation, emotional support, and tutoring benchmarks, DialogXpert drives conversations to under $3$ turns with success rates exceeding 94\% and, with a larger LLM prior, pushes success above 97\% while markedly improving negotiation outcomes. This framework delivers real-time, strategic, and emotionally intelligent dialogue planning at scale. Code available at https://github.com/declare-lab/dialogxpert/
PROEMO: Prompt-Driven Text-to-Speech Synthesis Based on Emotion and Intensity Control
Jan 10, 2025Speech synthesis has significantly advanced from statistical methods to deep neural network architectures, leading to various text-to-speech (TTS) models that closely mimic human speech patterns. However, capturing nuances such as emotion and style in speech synthesis is challenging. To address this challenge, we introduce an approach centered on prompt-based emotion control. The proposed architecture incorporates emotion and intensity control across multi-speakers. Furthermore, we leverage large language models (LLMs) to manipulate speech prosody while preserving linguistic content. Using embedding emotional cues, regulating intensity levels, and guiding prosodic variations with prompts, our approach infuses synthesized speech with human-like expressiveness and variability. Lastly, we demonstrate the effectiveness of our approach through a systematic exploration of the control mechanisms mentioned above.
TangoFlux: Super Fast and Faithful Text to Audio Generation with Flow Matching and Clap-Ranked Preference Optimization
Dec 30, 2024We introduce TangoFlux, an efficient Text-to-Audio (TTA) generative model with 515M parameters, capable of generating up to 30 seconds of 44.1kHz audio in just 3.7 seconds on a single A40 GPU. A key challenge in aligning TTA models lies in the difficulty of creating preference pairs, as TTA lacks structured mechanisms like verifiable rewards or gold-standard answers available for Large Language Models (LLMs). To address this, we propose CLAP-Ranked Preference Optimization (CRPO), a novel framework that iteratively generates and optimizes preference data to enhance TTA alignment. We demonstrate that the audio preference dataset generated using CRPO outperforms existing alternatives. With this framework, TangoFlux achieves state-of-the-art performance across both objective and subjective benchmarks. We open source all code and models to support further research in TTA generation.
DART: Disentanglement of Accent and Speaker Representation in Multispeaker Text-to-Speech
Oct 17, 2024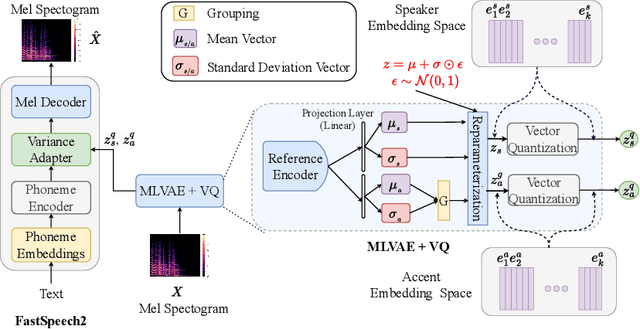
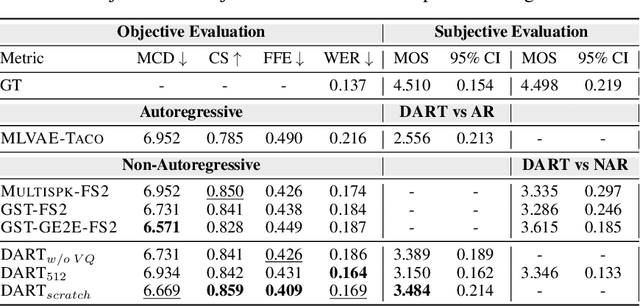
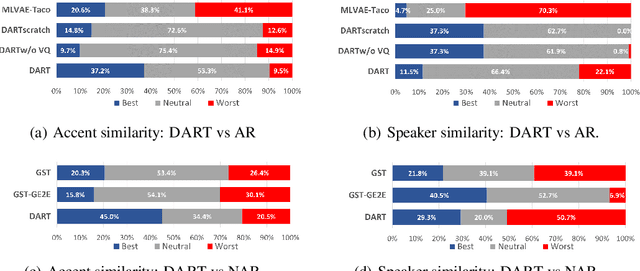
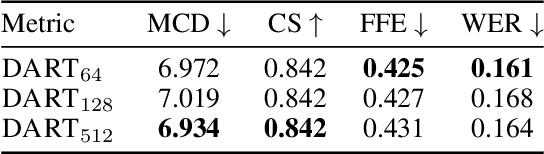
Recent advancements in Text-to-Speech (TTS) systems have enabled the generation of natural and expressive speech from textual input. Accented TTS aims to enhance user experience by making the synthesized speech more relatable to minority group listeners, and useful across various applications and context. Speech synthesis can further be made more flexible by allowing users to choose any combination of speaker identity and accent, resulting in a wide range of personalized speech outputs. Current models struggle to disentangle speaker and accent representation, making it difficult to accurately imitate different accents while maintaining the same speaker characteristics. We propose a novel approach to disentangle speaker and accent representations using multi-level variational autoencoders (ML-VAE) and vector quantization (VQ) to improve flexibility and enhance personalization in speech synthesis. Our proposed method addresses the challenge of effectively separating speaker and accent characteristics, enabling more fine-grained control over the synthesized speech. Code and speech samples are publicly available.
Reward Steering with Evolutionary Heuristics for Decoding-time Alignment
Jun 25, 2024



The widespread applicability and increasing omnipresence of LLMs have instigated a need to align LLM responses to user and stakeholder preferences. Many preference optimization approaches have been proposed that fine-tune LLM parameters to achieve good alignment. However, such parameter tuning is known to interfere with model performance on many tasks. Moreover, keeping up with shifting user preferences is tricky in such a situation. Decoding-time alignment with reward model guidance solves these issues at the cost of increased inference time. However, most of such methods fail to strike the right balance between exploration and exploitation of reward -- often due to the conflated formulation of these two aspects - to give well-aligned responses. To remedy this we decouple these two aspects and implement them in an evolutionary fashion: exploration is enforced by decoding from mutated instructions and exploitation is represented as the periodic replacement of poorly-rewarded generations with well-rewarded ones. Empirical evidences indicate that this strategy outperforms many preference optimization and decode-time alignment approaches on two widely accepted alignment benchmarks AlpacaEval 2 and MT-Bench. Our implementation will be available at: https://darwin-alignment.github.io.
Leveraging Parameter-Efficient Transfer Learning for Multi-Lingual Text-to-Speech Adaptation
Jun 25, 2024
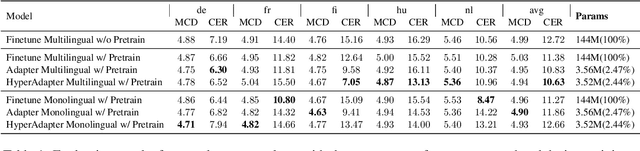


Different languages have distinct phonetic systems and vary in their prosodic features making it challenging to develop a Text-to-Speech (TTS) model that can effectively synthesise speech in multilingual settings. Furthermore, TTS architecture needs to be both efficient enough to capture nuances in multiple languages and efficient enough to be practical for deployment. The standard approach is to build transformer based model such as SpeechT5 and train it on large multilingual dataset. As the size of these models grow the conventional fine-tuning for adapting these model becomes impractical due to heavy computational cost. In this paper, we proposes to integrate parameter-efficient transfer learning (PETL) methods such as adapters and hypernetwork with TTS architecture for multilingual speech synthesis. Notably, in our experiments PETL methods able to achieve comparable or even better performance compared to full fine-tuning with only $\sim$2.5\% tunable parameters.The code and samples are available at: https://anonymous.4open.science/r/multilingualTTS-BA4C.
Improving Text-To-Audio Models with Synthetic Captions
Jun 18, 2024



It is an open challenge to obtain high quality training data, especially captions, for text-to-audio models. Although prior methods have leveraged \textit{text-only language models} to augment and improve captions, such methods have limitations related to scale and coherence between audio and captions. In this work, we propose an audio captioning pipeline that uses an \textit{audio language model} to synthesize accurate and diverse captions for audio at scale. We leverage this pipeline to produce a dataset of synthetic captions for AudioSet, named \texttt{AF-AudioSet}, and then evaluate the benefit of pre-training text-to-audio models on these synthetic captions. Through systematic evaluations on AudioCaps and MusicCaps, we find leveraging our pipeline and synthetic captions leads to significant improvements on audio generation quality, achieving a new \textit{state-of-the-art}.
Accent Conversion in Text-To-Speech Using Multi-Level VAE and Adversarial Training
Jun 03, 2024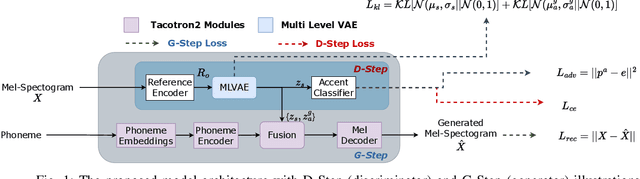
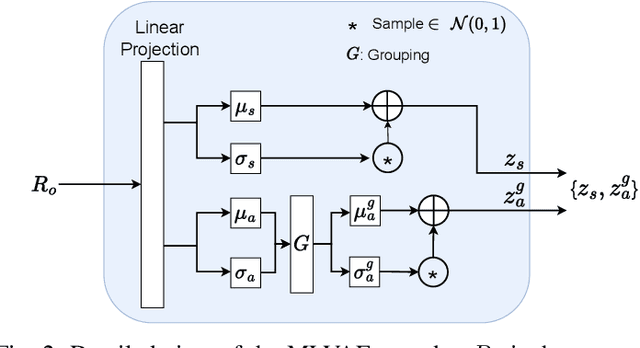
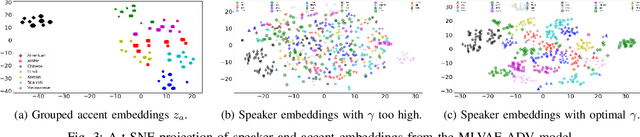
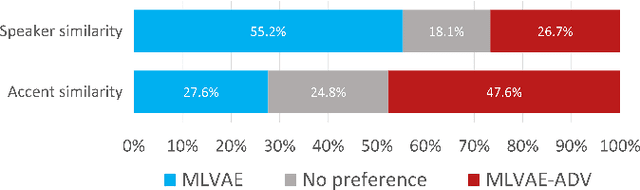
With rapid globalization, the need to build inclusive and representative speech technology cannot be overstated. Accent is an important aspect of speech that needs to be taken into consideration while building inclusive speech synthesizers. Inclusive speech technology aims to erase any biases towards specific groups, such as people of certain accent. We note that state-of-the-art Text-to-Speech (TTS) systems may currently not be suitable for all people, regardless of their background, as they are designed to generate high-quality voices without focusing on accent. In this paper, we propose a TTS model that utilizes a Multi-Level Variational Autoencoder with adversarial learning to address accented speech synthesis and conversion in TTS, with a vision for more inclusive systems in the future. We evaluate the performance through both objective metrics and subjective listening tests. The results show an improvement in accent conversion ability compared to the baseline.
HyperTTS: Parameter Efficient Adaptation in Text to Speech using Hypernetworks
Apr 06, 2024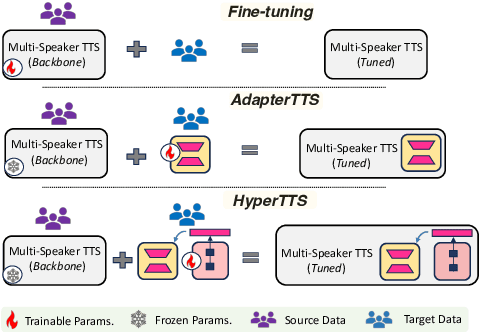
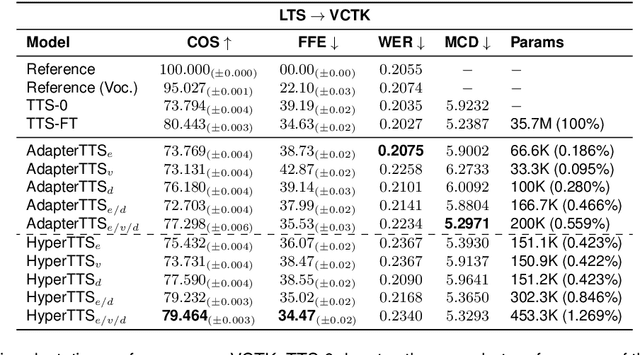
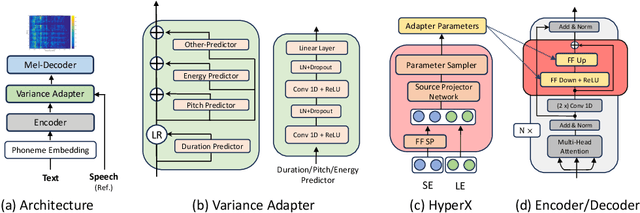

Neural speech synthesis, or text-to-speech (TTS), aims to transform a signal from the text domain to the speech domain. While developing TTS architectures that train and test on the same set of speakers has seen significant improvements, out-of-domain speaker performance still faces enormous limitations. Domain adaptation on a new set of speakers can be achieved by fine-tuning the whole model for each new domain, thus making it parameter-inefficient. This problem can be solved by Adapters that provide a parameter-efficient alternative to domain adaptation. Although famous in NLP, speech synthesis has not seen much improvement from Adapters. In this work, we present HyperTTS, which comprises a small learnable network, "hypernetwork", that generates parameters of the Adapter blocks, allowing us to condition Adapters on speaker representations and making them dynamic. Extensive evaluations of two domain adaptation settings demonstrate its effectiveness in achieving state-of-the-art performance in the parameter-efficient regime. We also compare different variants of HyperTTS, comparing them with baselines in different studies. Promising results on the dynamic adaptation of adapter parameters using hypernetworks open up new avenues for domain-generic multi-speaker TTS systems. The audio samples and code are available at https://github.com/declare-lab/HyperTTS.
CM-TTS: Enhancing Real Time Text-to-Speech Synthesis Efficiency through Weighted Samplers and Consistency Models
Mar 31, 2024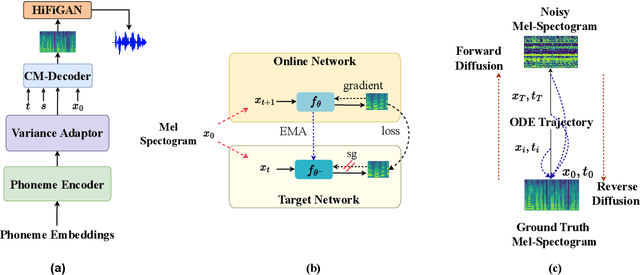
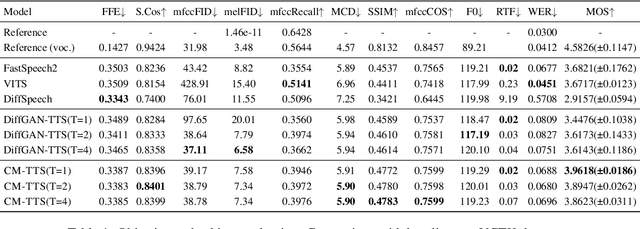
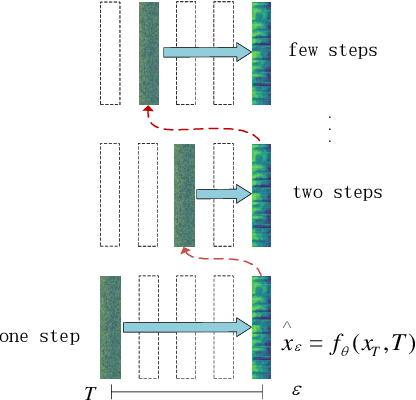

Neural Text-to-Speech (TTS) systems find broad applications in voice assistants, e-learning, and audiobook creation. The pursuit of modern models, like Diffusion Models (DMs), holds promise for achieving high-fidelity, real-time speech synthesis. Yet, the efficiency of multi-step sampling in Diffusion Models presents challenges. Efforts have been made to integrate GANs with DMs, speeding up inference by approximating denoising distributions, but this introduces issues with model convergence due to adversarial training. To overcome this, we introduce CM-TTS, a novel architecture grounded in consistency models (CMs). Drawing inspiration from continuous-time diffusion models, CM-TTS achieves top-quality speech synthesis in fewer steps without adversarial training or pre-trained model dependencies. We further design weighted samplers to incorporate different sampling positions into model training with dynamic probabilities, ensuring unbiased learning throughout the entire training process. We present a real-time mel-spectrogram generation consistency model, validated through comprehensive evaluations. Experimental results underscore CM-TTS's superiority over existing single-step speech synthesis systems, representing a significant advancement in the field.