 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDART: Disentanglement of Accent and Speaker Representation in Multispeaker Text-to-Speech
Paper and Code
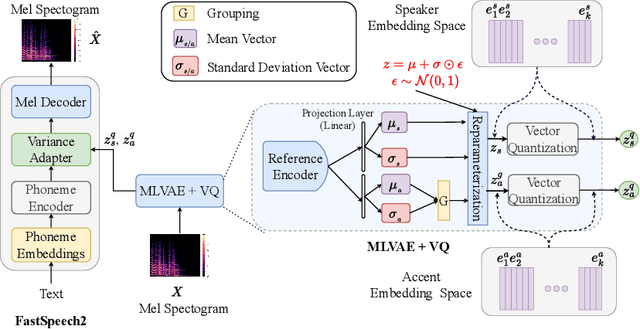
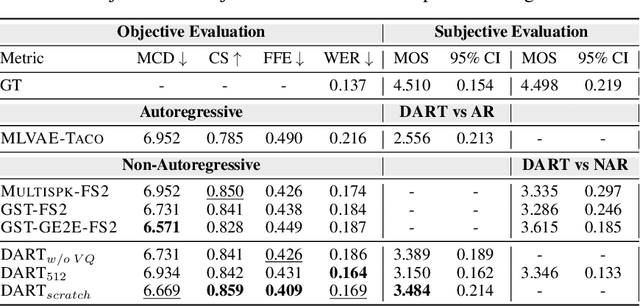
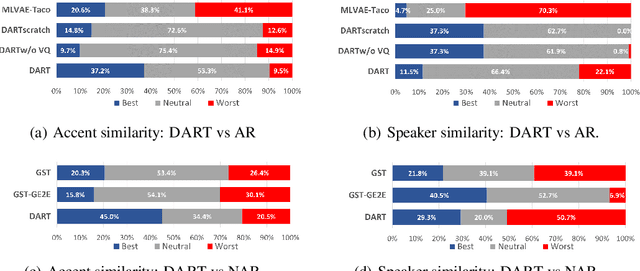
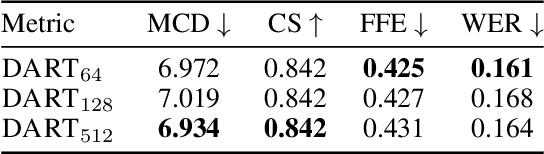
Recent advancements in Text-to-Speech (TTS) systems have enabled the generation of natural and expressive speech from textual input. Accented TTS aims to enhance user experience by making the synthesized speech more relatable to minority group listeners, and useful across various applications and context. Speech synthesis can further be made more flexible by allowing users to choose any combination of speaker identity and accent, resulting in a wide range of personalized speech outputs. Current models struggle to disentangle speaker and accent representation, making it difficult to accurately imitate different accents while maintaining the same speaker characteristics. We propose a novel approach to disentangle speaker and accent representations using multi-level variational autoencoders (ML-VAE) and vector quantization (VQ) to improve flexibility and enhance personalization in speech synthesis. Our proposed method addresses the challenge of effectively separating speaker and accent characteristics, enabling more fine-grained control over the synthesized speech. Code and speech samples are publicly available.