 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMelodySim: Measuring Melody-aware Music Similarity for Plagiarism Detection
May 27, 2025We propose MelodySim, a melody-aware music similarity model and dataset for plagiarism detection. First, we introduce a novel method to construct a dataset with focus on melodic similarity. By augmenting Slakh2100; an existing MIDI dataset, we generate variations of each piece while preserving the melody through modifications such as note splitting, arpeggiation, minor track dropout (excluding bass), and re-instrumentation. A user study confirms that positive pairs indeed contain similar melodies, with other musical tracks significantly changed. Second, we develop a segment-wise melodic-similarity detection model that uses a MERT encoder and applies a triplet neural network to capture melodic similarity. The resultant decision matrix highlights where plagiarism might occur. Our model achieves high accuracy on the MelodySim test set.
DART: Disentanglement of Accent and Speaker Representation in Multispeaker Text-to-Speech
Oct 17, 2024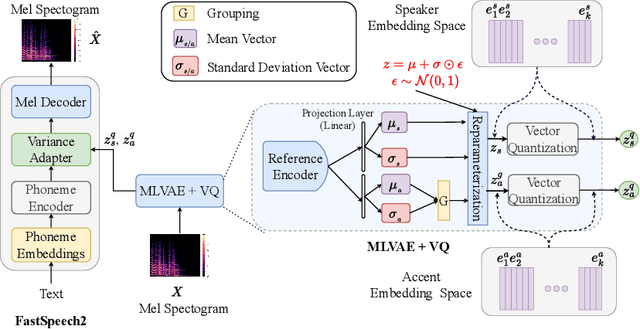
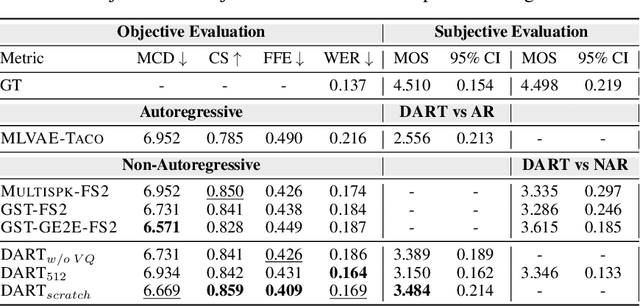
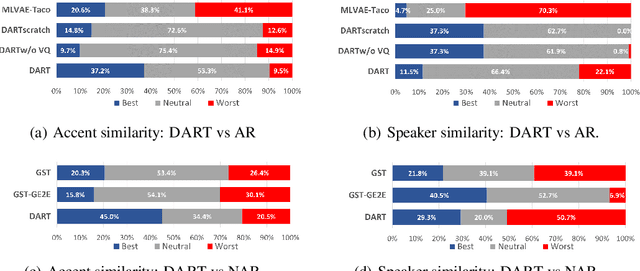
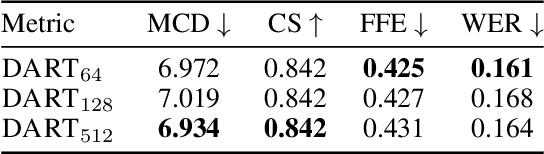
Recent advancements in Text-to-Speech (TTS) systems have enabled the generation of natural and expressive speech from textual input. Accented TTS aims to enhance user experience by making the synthesized speech more relatable to minority group listeners, and useful across various applications and context. Speech synthesis can further be made more flexible by allowing users to choose any combination of speaker identity and accent, resulting in a wide range of personalized speech outputs. Current models struggle to disentangle speaker and accent representation, making it difficult to accurately imitate different accents while maintaining the same speaker characteristics. We propose a novel approach to disentangle speaker and accent representations using multi-level variational autoencoders (ML-VAE) and vector quantization (VQ) to improve flexibility and enhance personalization in speech synthesis. Our proposed method addresses the challenge of effectively separating speaker and accent characteristics, enabling more fine-grained control over the synthesized speech. Code and speech samples are publicly available.
MidiCaps -- A large-scale MIDI dataset with text captions
Jun 04, 2024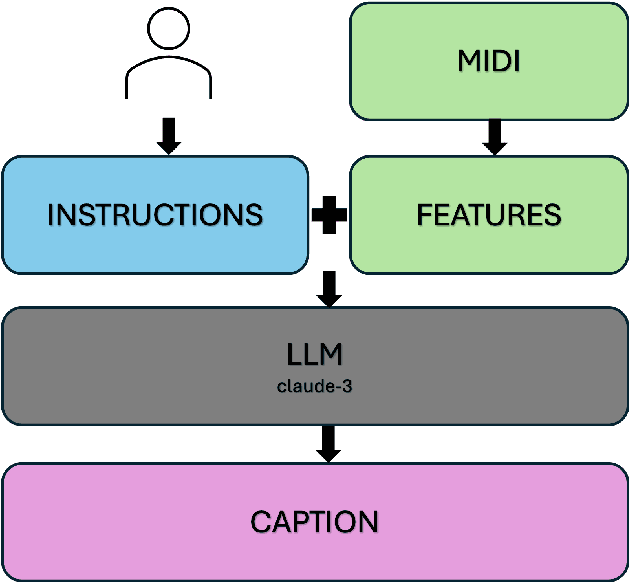
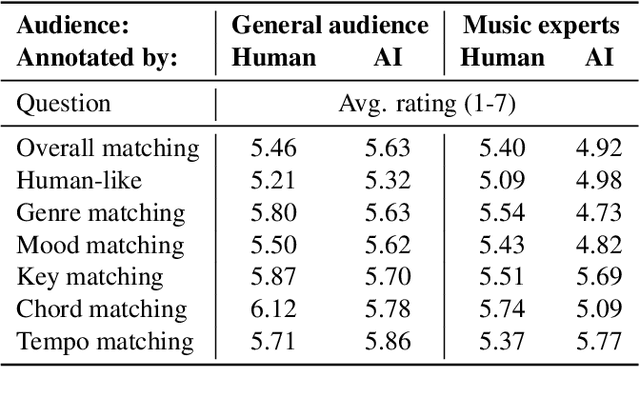
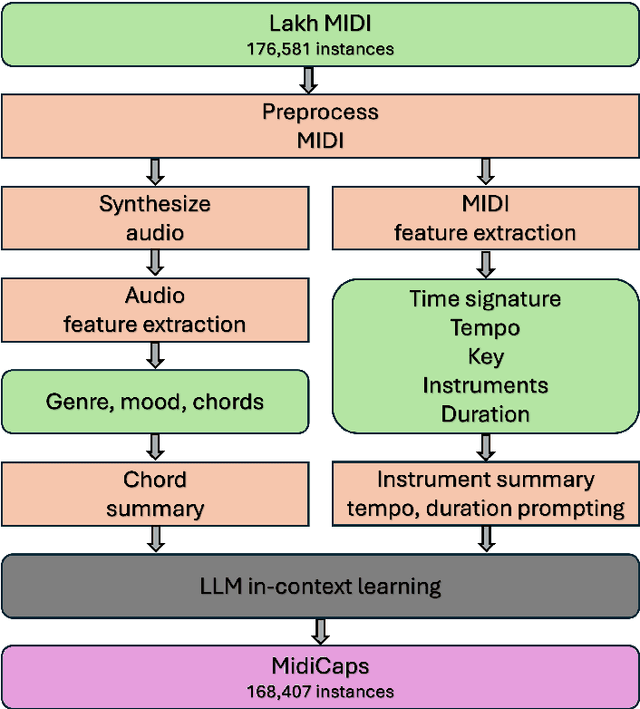
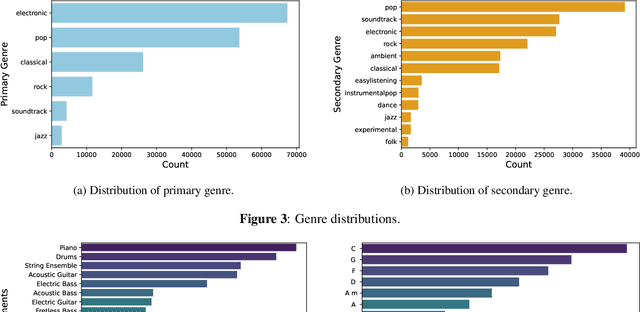
Generative models guided by text prompts are increasingly becoming more popular. However, no text-to-MIDI models currently exist, mostly due to the lack of a captioned MIDI dataset. This work aims to enable research that combines LLMs with symbolic music by presenting the first large-scale MIDI dataset with text captions that is openly available: MidiCaps. MIDI (Musical Instrument Digital Interface) files are a widely used format for encoding musical information. Their structured format captures the nuances of musical composition and has practical applications by music producers, composers, musicologists, as well as performers. Inspired by recent advancements in captioning techniques applied to various domains, we present a large-scale curated dataset of over 168k MIDI files accompanied by textual descriptions. Each MIDI caption succinctly describes the musical content, encompassing tempo, chord progression, time signature, instruments present, genre and mood; thereby facilitating multi-modal exploration and analysis. The dataset contains a mix of various genres, styles, and complexities, offering a rich source for training and evaluating models for tasks such as music information retrieval, music understanding and cross-modal translation. We provide detailed statistics about the dataset and have assessed the quality of the captions in an extensive listening study. We anticipate that this resource will stimulate further research in the intersection of music and natural language processing, fostering advancements in both fields.
Accent Conversion in Text-To-Speech Using Multi-Level VAE and Adversarial Training
Jun 03, 2024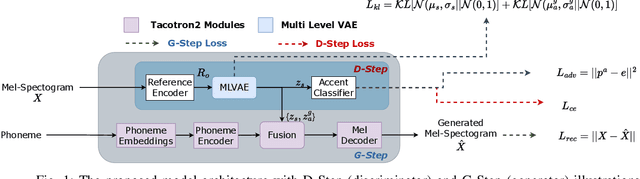
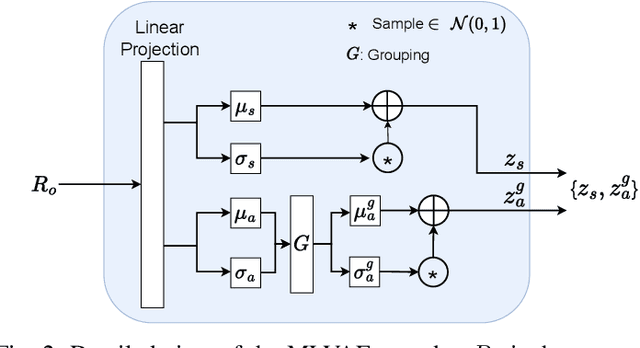
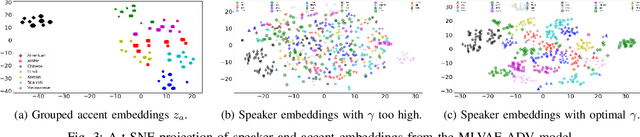
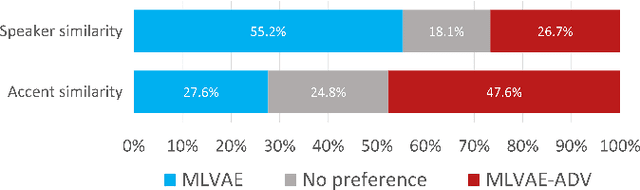
With rapid globalization, the need to build inclusive and representative speech technology cannot be overstated. Accent is an important aspect of speech that needs to be taken into consideration while building inclusive speech synthesizers. Inclusive speech technology aims to erase any biases towards specific groups, such as people of certain accent. We note that state-of-the-art Text-to-Speech (TTS) systems may currently not be suitable for all people, regardless of their background, as they are designed to generate high-quality voices without focusing on accent. In this paper, we propose a TTS model that utilizes a Multi-Level Variational Autoencoder with adversarial learning to address accented speech synthesis and conversion in TTS, with a vision for more inclusive systems in the future. We evaluate the performance through both objective metrics and subjective listening tests. The results show an improvement in accent conversion ability compared to the baseline.
Mustango: Toward Controllable Text-to-Music Generation
Nov 14, 2023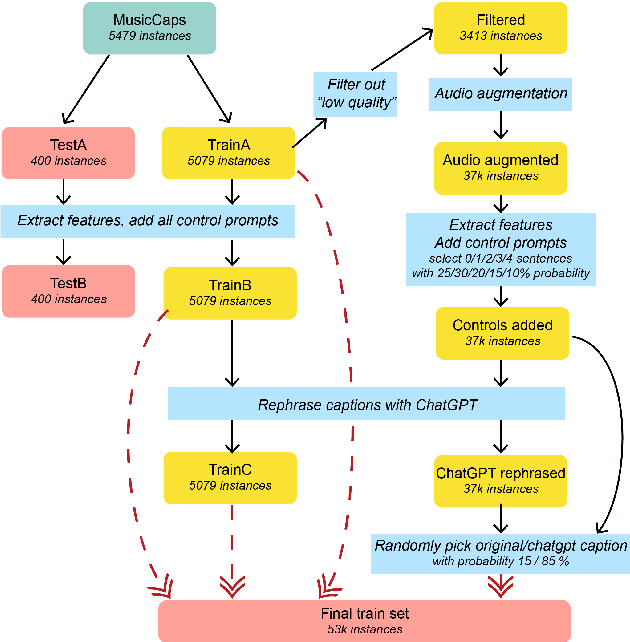
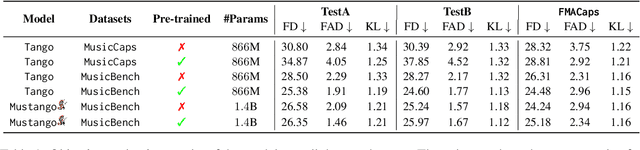
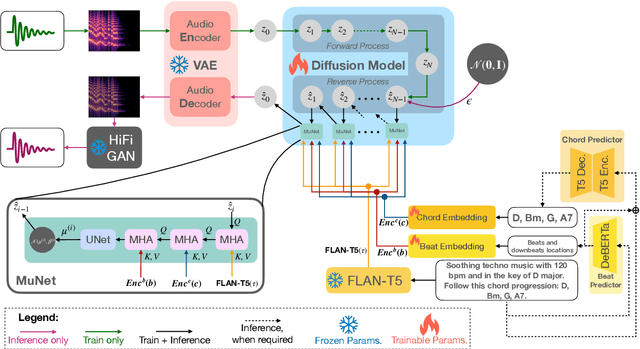

With recent advancements in text-to-audio and text-to-music based on latent diffusion models, the quality of generated content has been reaching new heights. The controllability of musical aspects, however, has not been explicitly explored in text-to-music systems yet. In this paper, we present Mustango, a music-domain-knowledge-inspired text-to-music system based on diffusion, that expands the Tango text-to-audio model. Mustango aims to control the generated music, not only with general text captions, but from more rich captions that could include specific instructions related to chords, beats, tempo, and key. As part of Mustango, we propose MuNet, a Music-Domain-Knowledge-Informed UNet sub-module to integrate these music-specific features, which we predict from the text prompt, as well as the general text embedding, into the diffusion denoising process. To overcome the limited availability of open datasets of music with text captions, we propose a novel data augmentation method that includes altering the harmonic, rhythmic, and dynamic aspects of music audio and using state-of-the-art Music Information Retrieval methods to extract the music features which will then be appended to the existing descriptions in text format. We release the resulting MusicBench dataset which contains over 52K instances and includes music-theory-based descriptions in the caption text. Through extensive experiments, we show that the quality of the music generated by Mustango is state-of-the-art, and the controllability through music-specific text prompts greatly outperforms other models in terms of desired chords, beat, key, and tempo, on multiple datasets.
Accented Text-to-Speech Synthesis with a Conditional Variational Autoencoder
Nov 07, 2022



Accent plays a significant role in speech communication, influencing understanding capabilities and also conveying a person's identity. This paper introduces a novel and efficient framework for accented Text-to-Speech (TTS) synthesis based on a Conditional Variational Autoencoder. It has the ability to synthesize a selected speaker's speech that is converted to any desired target accent. Our thorough experiments validate the effectiveness of our proposed framework using both objective and subjective evaluations. The results also show remarkable performance in terms of the ability to manipulate accents in the synthesized speech and provide a promising avenue for future accented TTS research.