 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMustango: Toward Controllable Text-to-Music Generation
Paper and Code
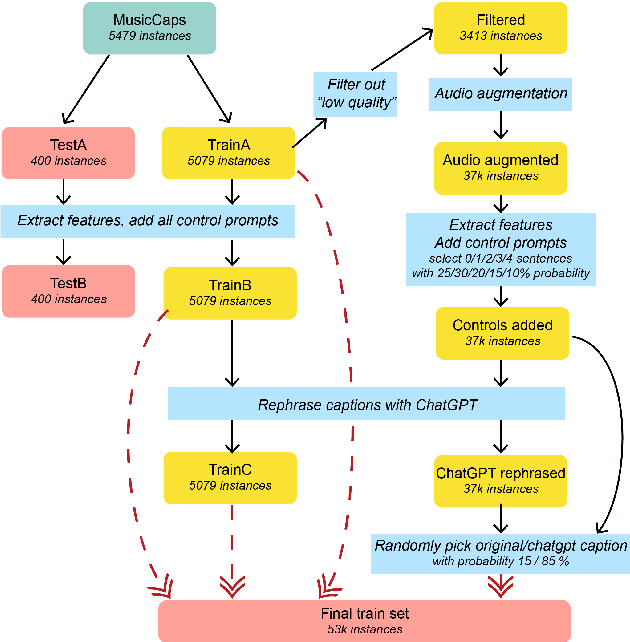
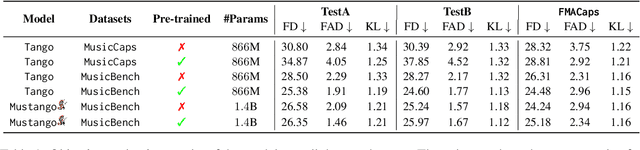
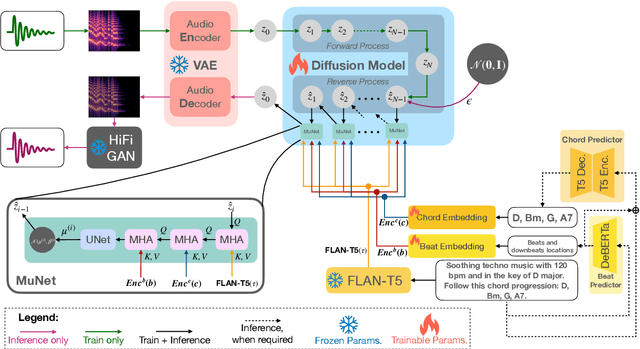

With recent advancements in text-to-audio and text-to-music based on latent diffusion models, the quality of generated content has been reaching new heights. The controllability of musical aspects, however, has not been explicitly explored in text-to-music systems yet. In this paper, we present Mustango, a music-domain-knowledge-inspired text-to-music system based on diffusion, that expands the Tango text-to-audio model. Mustango aims to control the generated music, not only with general text captions, but from more rich captions that could include specific instructions related to chords, beats, tempo, and key. As part of Mustango, we propose MuNet, a Music-Domain-Knowledge-Informed UNet sub-module to integrate these music-specific features, which we predict from the text prompt, as well as the general text embedding, into the diffusion denoising process. To overcome the limited availability of open datasets of music with text captions, we propose a novel data augmentation method that includes altering the harmonic, rhythmic, and dynamic aspects of music audio and using state-of-the-art Music Information Retrieval methods to extract the music features which will then be appended to the existing descriptions in text format. We release the resulting MusicBench dataset which contains over 52K instances and includes music-theory-based descriptions in the caption text. Through extensive experiments, we show that the quality of the music generated by Mustango is state-of-the-art, and the controllability through music-specific text prompts greatly outperforms other models in terms of desired chords, beat, key, and tempo, on multiple datasets.