 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoonbeam: A MIDI Foundation Model Using Both Absolute and Relative Music Attributes
May 21, 2025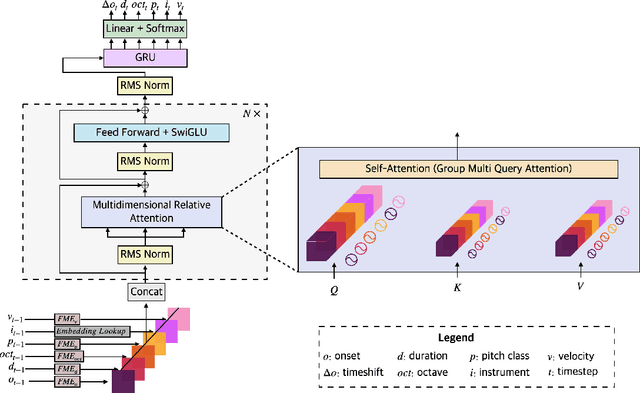
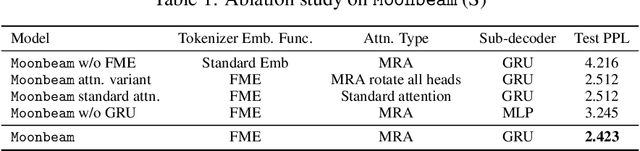
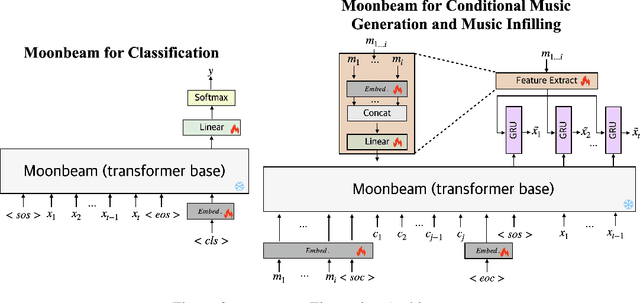
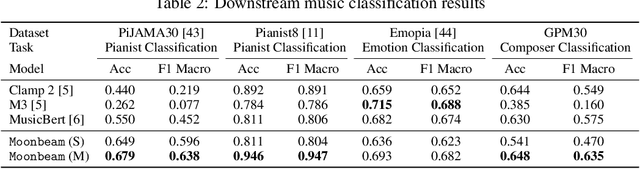
Moonbeam is a transformer-based foundation model for symbolic music, pretrained on a large and diverse collection of MIDI data totaling 81.6K hours of music and 18 billion tokens. Moonbeam incorporates music-domain inductive biases by capturing both absolute and relative musical attributes through the introduction of a novel domain-knowledge-inspired tokenization method and Multidimensional Relative Attention (MRA), which captures relative music information without additional trainable parameters. Leveraging the pretrained Moonbeam, we propose 2 finetuning architectures with full anticipatory capabilities, targeting 2 categories of downstream tasks: symbolic music understanding and conditional music generation (including music infilling). Our model outperforms other large-scale pretrained music models in most cases in terms of accuracy and F1 score across 3 downstream music classification tasks on 4 datasets. Moreover, our finetuned conditional music generation model outperforms a strong transformer baseline with a REMI-like tokenizer. We open-source the code, pretrained model, and generated samples on Github.
GAPS: A Large and Diverse Classical Guitar Dataset and Benchmark Transcription Model
Aug 16, 2024We introduce GAPS (Guitar-Aligned Performance Scores), a new dataset of classical guitar performances, and a benchmark guitar transcription model that achieves state-of-the-art performance on GuitarSet in both supervised and zero-shot settings. GAPS is the largest dataset of real guitar audio, containing 14 hours of freely available audio-score aligned pairs, recorded in diverse conditions by over 200 performers, together with high-resolution note-level MIDI alignments and performance videos. These enable us to train a state-of-the-art model for automatic transcription of solo guitar recordings which can generalise well to real world audio that is unseen during training.
Mustango: Toward Controllable Text-to-Music Generation
Nov 14, 2023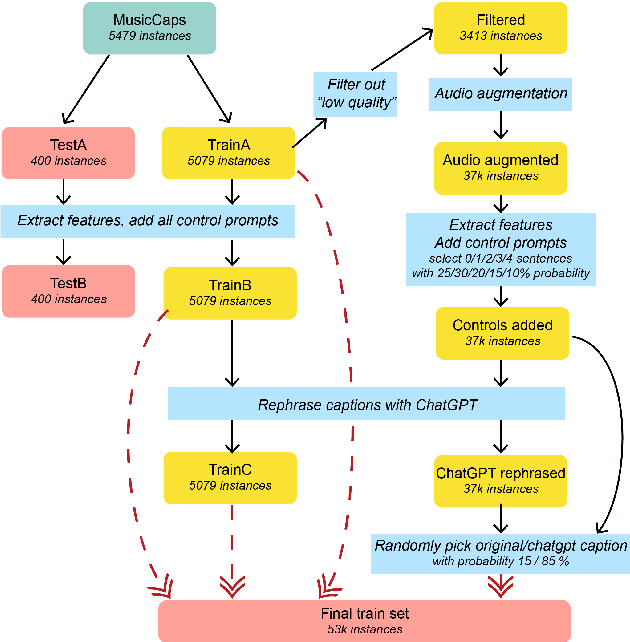
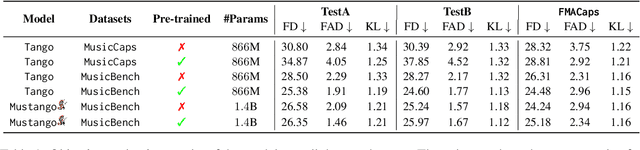
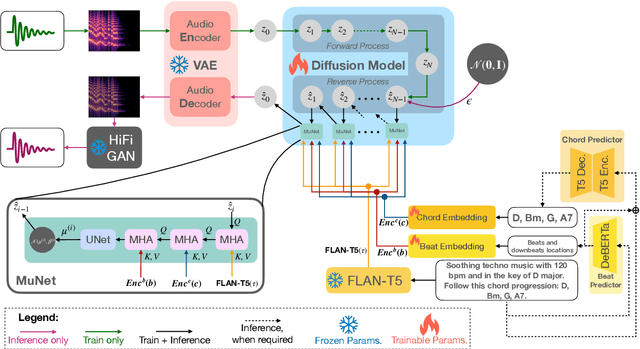

With recent advancements in text-to-audio and text-to-music based on latent diffusion models, the quality of generated content has been reaching new heights. The controllability of musical aspects, however, has not been explicitly explored in text-to-music systems yet. In this paper, we present Mustango, a music-domain-knowledge-inspired text-to-music system based on diffusion, that expands the Tango text-to-audio model. Mustango aims to control the generated music, not only with general text captions, but from more rich captions that could include specific instructions related to chords, beats, tempo, and key. As part of Mustango, we propose MuNet, a Music-Domain-Knowledge-Informed UNet sub-module to integrate these music-specific features, which we predict from the text prompt, as well as the general text embedding, into the diffusion denoising process. To overcome the limited availability of open datasets of music with text captions, we propose a novel data augmentation method that includes altering the harmonic, rhythmic, and dynamic aspects of music audio and using state-of-the-art Music Information Retrieval methods to extract the music features which will then be appended to the existing descriptions in text format. We release the resulting MusicBench dataset which contains over 52K instances and includes music-theory-based descriptions in the caption text. Through extensive experiments, we show that the quality of the music generated by Mustango is state-of-the-art, and the controllability through music-specific text prompts greatly outperforms other models in terms of desired chords, beat, key, and tempo, on multiple datasets.
Study of GANs for Noisy Speech Simulation from Clean Speech
May 21, 2023The performance of speech processing models trained on clean speech drops significantly in noisy conditions. Training with noisy datasets alleviates the problem, but procuring such datasets is not always feasible. Noisy speech simulation models that generate noisy speech from clean speech help remedy this issue. In our work, we study the ability of Generative Adversarial Networks (GANs) to simulate a variety of noises. Noise from the Ultra-High-Frequency/Very-High-Frequency (UHF/VHF), additive stationary and non-stationary, and codec distortion categories are studied. We propose four GANs, including the non-parallel translators, SpeechAttentionGAN, SimuGAN, and MaskCycleGAN-Augment, and the parallel translator, Speech2Speech-Augment. We achieved improvements of 55.8%, 28.9%, and 22.8% in terms of Multi-Scale Spectral Loss (MSSL) as compared to the baseline for the RATS, TIMIT-Cabin, and TIMIT-Helicopter datasets, respectively, after training on small datasets of about 3 minutes.
Hierarchical Recurrent Neural Networks for Conditional Melody Generation with Long-term Structure
Feb 19, 2021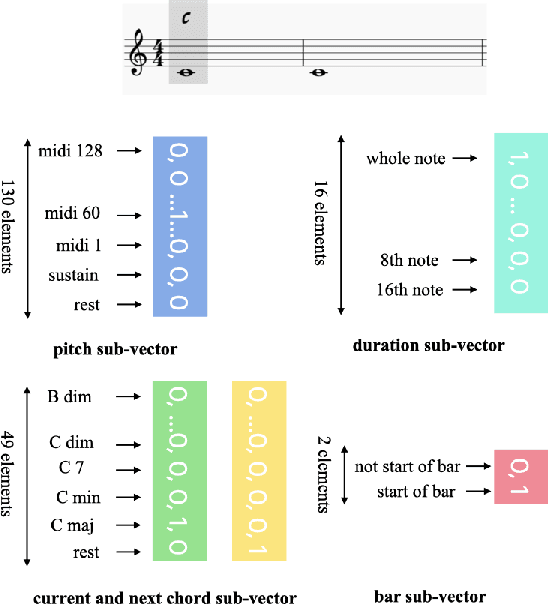
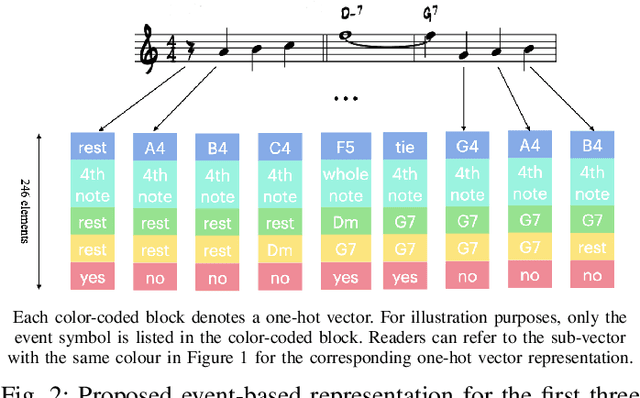
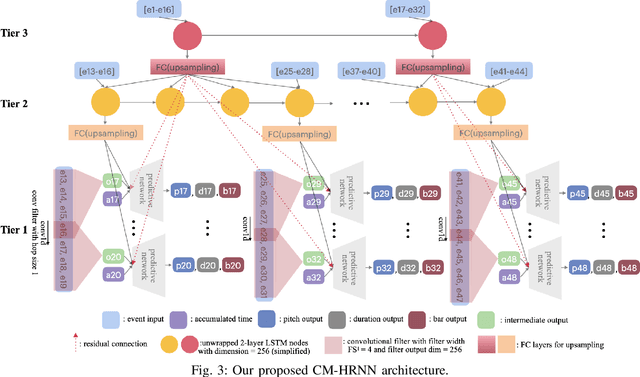
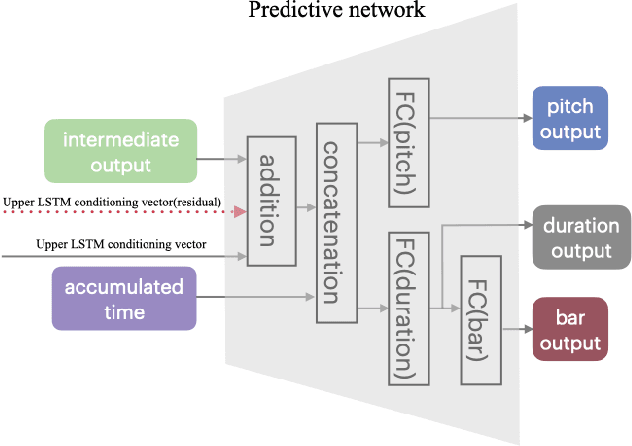
The rise of deep learning technologies has quickly advanced many fields, including that of generative music systems. There exist a number of systems that allow for the generation of good sounding short snippets, yet, these generated snippets often lack an overarching, longer-term structure. In this work, we propose CM-HRNN: a conditional melody generation model based on a hierarchical recurrent neural network. This model allows us to generate melodies with long-term structures based on given chord accompaniments. We also propose a novel, concise event-based representation to encode musical lead sheets while retaining the notes' relative position within the bar with respect to the musical meter. With this new data representation, the proposed architecture can simultaneously model the rhythmic, as well as the pitch structures in an effective way. Melodies generated by the proposed model were extensively evaluated in quantitative experiments as well as a user study to ensure the musical quality of the output as well as to evaluate if they contain repeating patterns. We also compared the system with the state-of-the-art AttentionRNN. This comparison shows that melodies generated by CM-HRNN contain more repeated patterns (i.e., higher compression ratio) and a lower tonal tension (i.e., more tonally concise). Results from our listening test indicate that CM-HRNN outperforms AttentionRNN in terms of long-term structure and overall rating.