 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-based Talking Video Editing with Cascaded Conditional Diffusion
Jul 20, 2024
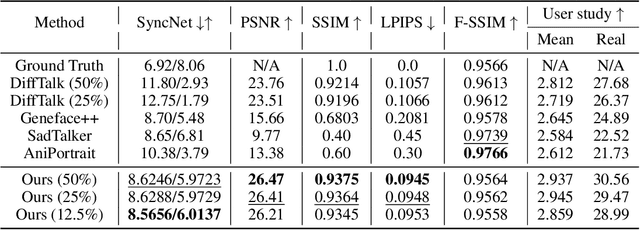


Text-based talking-head video editing aims to efficiently insert, delete, and substitute segments of talking videos through a user-friendly text editing approach. It is challenging because of \textbf{1)} generalizable talking-face representation, \textbf{2)} seamless audio-visual transitions, and \textbf{3)} identity-preserved talking faces. Previous works either require minutes of talking-face video training data and expensive test-time optimization for customized talking video editing or directly generate a video sequence without considering in-context information, leading to a poor generalizable representation, or incoherent transitions, or even inconsistent identity. In this paper, we propose an efficient cascaded conditional diffusion-based framework, which consists of two stages: audio to dense-landmark motion and motion to video. \textit{\textbf{In the first stage}}, we first propose a dynamic weighted in-context diffusion module to synthesize dense-landmark motions given an edited audio. \textit{\textbf{In the second stage}}, we introduce a warping-guided conditional diffusion module. The module first interpolates between the start and end frames of the editing interval to generate smooth intermediate frames. Then, with the help of the audio-to-dense motion images, these intermediate frames are warped to obtain coarse intermediate frames. Conditioned on the warped intermedia frames, a diffusion model is adopted to generate detailed and high-resolution target frames, which guarantees coherent and identity-preserved transitions. The cascaded conditional diffusion model decomposes the complex talking editing task into two flexible generation tasks, which provides a generalizable talking-face representation, seamless audio-visual transitions, and identity-preserved faces on a small dataset. Experiments show the effectiveness and superiority of the proposed method.
Analysis of Speech Separation Performance Degradation on Emotional Speech Mixtures
Sep 14, 2023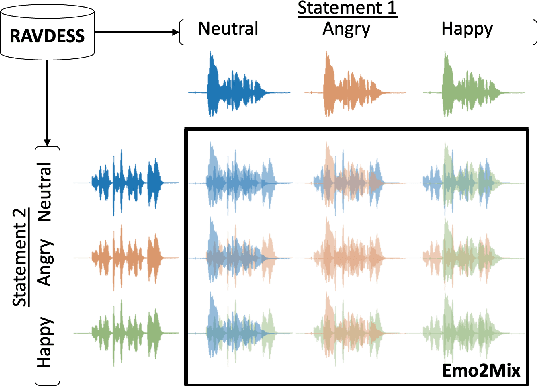
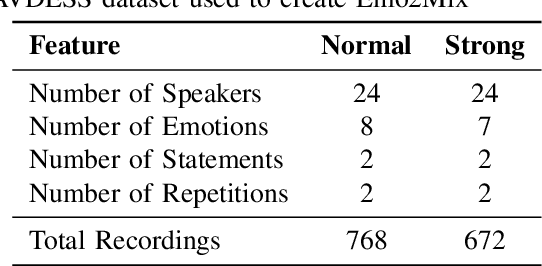
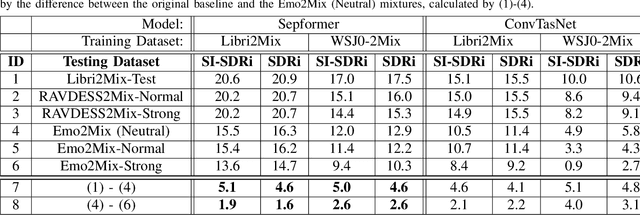
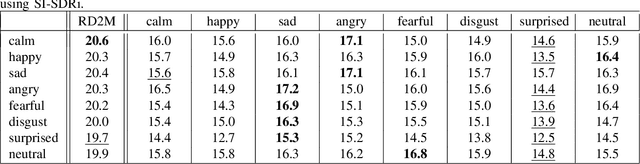
Despite recent strides made in Speech Separation, most models are trained on datasets with neutral emotions. Emotional speech has been known to degrade performance of models in a variety of speech tasks, which reduces the effectiveness of these models when deployed in real-world scenarios. In this paper we perform analysis to differentiate the performance degradation arising from the emotions in speech from the impact of out-of-domain inference. This is measured using a carefully designed test dataset, Emo2Mix, consisting of balanced data across all emotional combinations. We show that even models with strong out-of-domain performance such as Sepformer can still suffer significant degradation of up to 5.1 dB SI-SDRi on mixtures with strong emotions. This demonstrates the importance of accounting for emotions in real-world speech separation applications.
Study of GANs for Noisy Speech Simulation from Clean Speech
May 21, 2023The performance of speech processing models trained on clean speech drops significantly in noisy conditions. Training with noisy datasets alleviates the problem, but procuring such datasets is not always feasible. Noisy speech simulation models that generate noisy speech from clean speech help remedy this issue. In our work, we study the ability of Generative Adversarial Networks (GANs) to simulate a variety of noises. Noise from the Ultra-High-Frequency/Very-High-Frequency (UHF/VHF), additive stationary and non-stationary, and codec distortion categories are studied. We propose four GANs, including the non-parallel translators, SpeechAttentionGAN, SimuGAN, and MaskCycleGAN-Augment, and the parallel translator, Speech2Speech-Augment. We achieved improvements of 55.8%, 28.9%, and 22.8% in terms of Multi-Scale Spectral Loss (MSSL) as compared to the baseline for the RATS, TIMIT-Cabin, and TIMIT-Helicopter datasets, respectively, after training on small datasets of about 3 minutes.
Automated Audio Captioning with Epochal Difficult Captions for Curriculum Learning
Jun 04, 2022

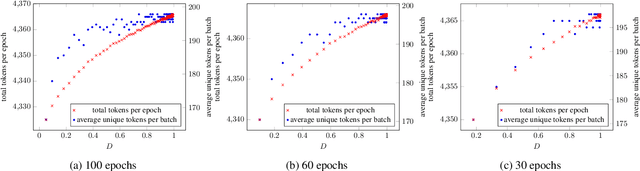
In this paper, we propose an algorithm, Epochal Difficult Captions, to supplement the training of any model for the Automated Audio Captioning task. Epochal Difficult Captions is an elegant evolution to the keyword estimation task that previous work have used to train the encoder of the AAC model. Epochal Difficult Captions modifies the target captions based on a curriculum and a difficulty level determined as a function of current epoch. Epochal Difficult Captions can be used with any model architecture and is a lightweight function that does not increase training time. We test our results on three systems and show that using Epochal Difficult Captions consistently improves performance
Estimation of speaker age and height from speech signal using bi-encoder transformer mixture model
Mar 22, 2022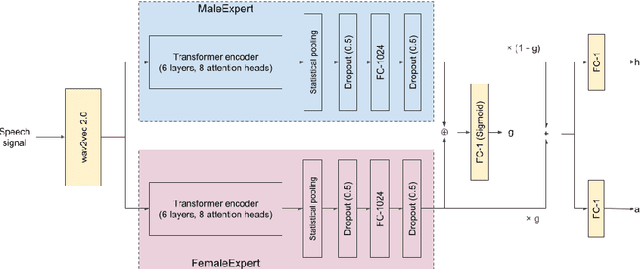
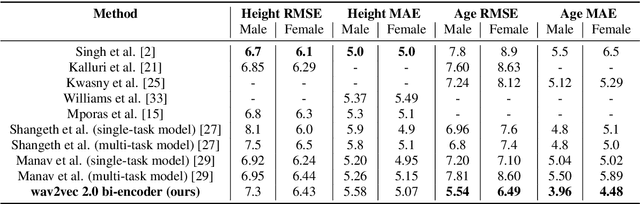


The estimation of speaker characteristics such as age and height is a challenging task, having numerous applications in voice forensic analysis. In this work, we propose a bi-encoder transformer mixture model for speaker age and height estimation. Considering the wide differences in male and female voice characteristics such as differences in formant and fundamental frequencies, we propose the use of two separate transformer encoders for the extraction of specific voice features in the male and female gender, using wav2vec 2.0 as a common-level feature extractor. This architecture reduces the interference effects during backpropagation and improves the generalizability of the model. We perform our experiments on the TIMIT dataset and significantly outperform the current state-of-the-art results on age estimation. Specifically, we achieve root mean squared error (RMSE) of 5.54 years and 6.49 years for male and female age estimation, respectively. Further experiment to evaluate the relative importance of different phonetic types for our task demonstrate that vowel sounds are the most distinguishing for age estimation.
Learning Speaker Representation with Semi-supervised Learning approach for Speaker Profiling
Oct 24, 2021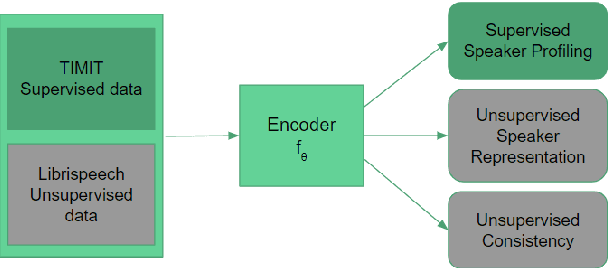
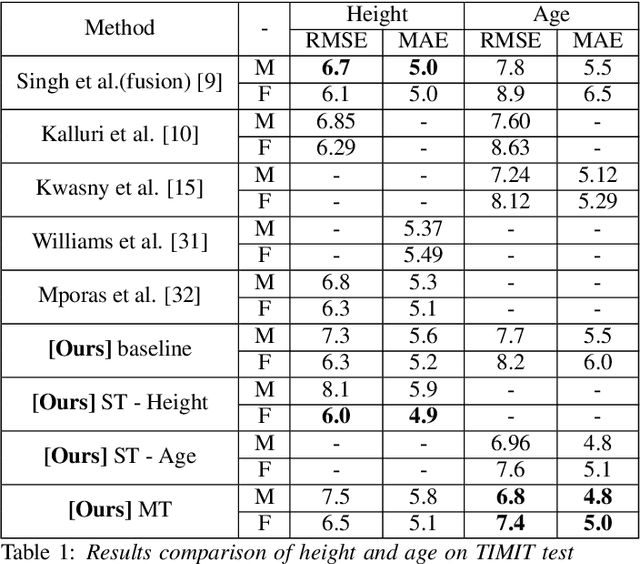
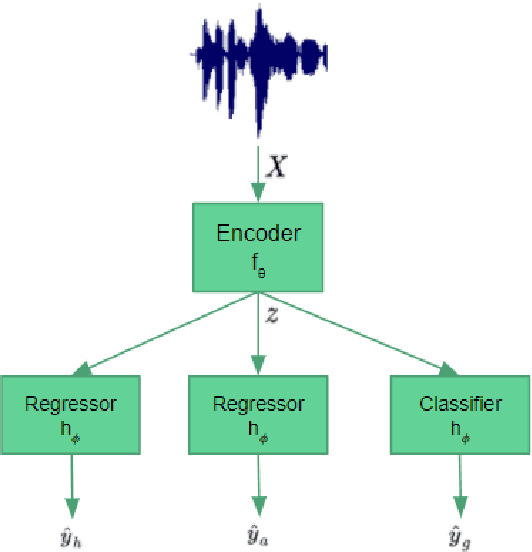
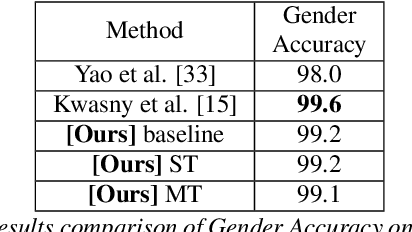
Speaker profiling, which aims to estimate speaker characteristics such as age and height, has a wide range of applications inforensics, recommendation systems, etc. In this work, we propose a semisupervised learning approach to mitigate the issue of low training data for speaker profiling. This is done by utilizing external corpus with speaker information to train a better representation which can help to improve the speaker profiling systems. Specifically, besides the standard supervised learning path, the proposed framework has two more paths: (1) an unsupervised speaker representation learning path that helps to capture the speaker information; (2) a consistency training path that helps to improve the robustness of the system by enforcing it to produce similar predictions for utterances of the same speaker.The proposed approach is evaluated on the TIMIT and NISP datasets for age, height, and gender estimation, while the Librispeech is used as the unsupervised external corpus. Trained both on single-task and multi-task settings, our approach was able to achieve state-of-the-art results on age estimation on the TIMIT Test dataset with Root Mean Square Error(RMSE) of6.8 and 7.4 years and Mean Absolute Error(MAE) of 4.8 and5.0 years for male and female speakers respectively.