 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimation of speaker age and height from speech signal using bi-encoder transformer mixture model
Paper and Code
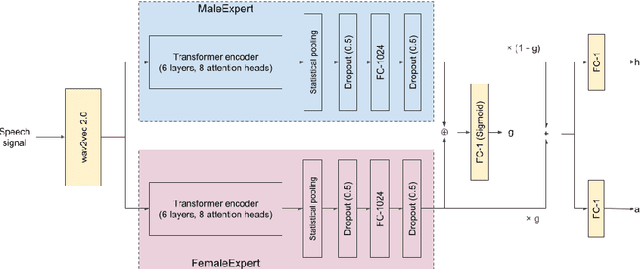
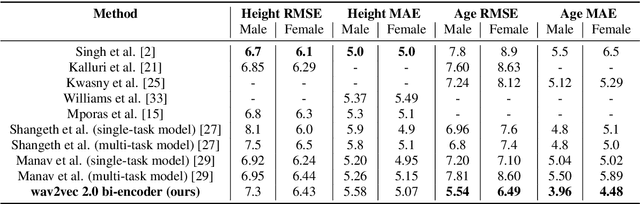


The estimation of speaker characteristics such as age and height is a challenging task, having numerous applications in voice forensic analysis. In this work, we propose a bi-encoder transformer mixture model for speaker age and height estimation. Considering the wide differences in male and female voice characteristics such as differences in formant and fundamental frequencies, we propose the use of two separate transformer encoders for the extraction of specific voice features in the male and female gender, using wav2vec 2.0 as a common-level feature extractor. This architecture reduces the interference effects during backpropagation and improves the generalizability of the model. We perform our experiments on the TIMIT dataset and significantly outperform the current state-of-the-art results on age estimation. Specifically, we achieve root mean squared error (RMSE) of 5.54 years and 6.49 years for male and female age estimation, respectively. Further experiment to evaluate the relative importance of different phonetic types for our task demonstrate that vowel sounds are the most distinguishing for age estimation.