 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimation of speaker age and height from speech signal using bi-encoder transformer mixture model
Mar 22, 2022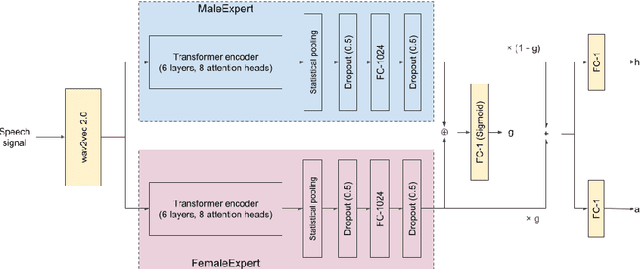
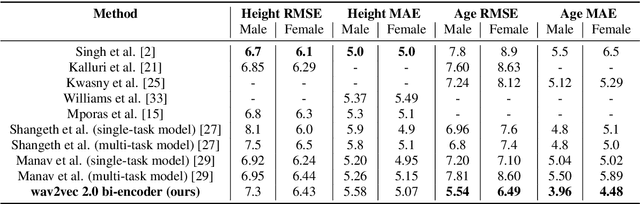


The estimation of speaker characteristics such as age and height is a challenging task, having numerous applications in voice forensic analysis. In this work, we propose a bi-encoder transformer mixture model for speaker age and height estimation. Considering the wide differences in male and female voice characteristics such as differences in formant and fundamental frequencies, we propose the use of two separate transformer encoders for the extraction of specific voice features in the male and female gender, using wav2vec 2.0 as a common-level feature extractor. This architecture reduces the interference effects during backpropagation and improves the generalizability of the model. We perform our experiments on the TIMIT dataset and significantly outperform the current state-of-the-art results on age estimation. Specifically, we achieve root mean squared error (RMSE) of 5.54 years and 6.49 years for male and female age estimation, respectively. Further experiment to evaluate the relative importance of different phonetic types for our task demonstrate that vowel sounds are the most distinguishing for age estimation.
Resource Management for Blockchain-enabled Federated Learning: A Deep Reinforcement Learning Approach
May 01, 2020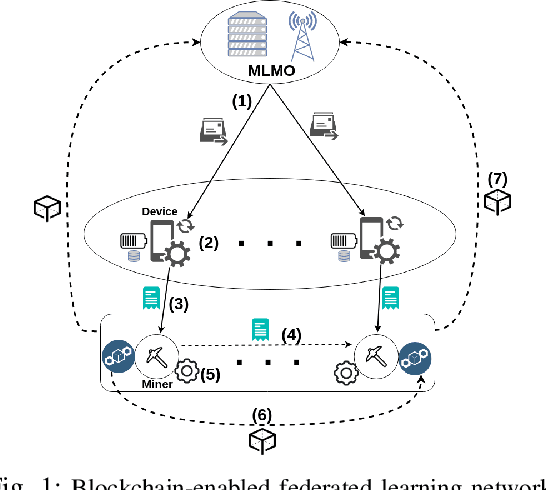
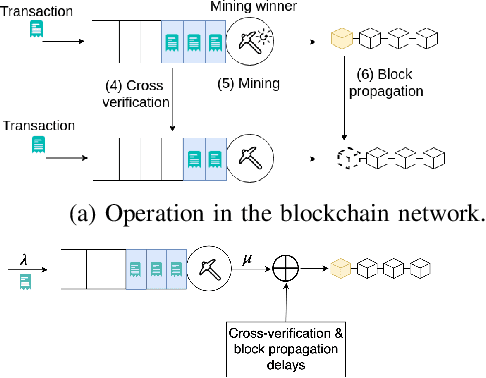
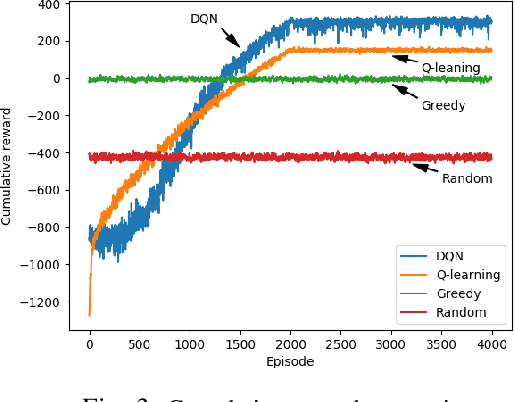
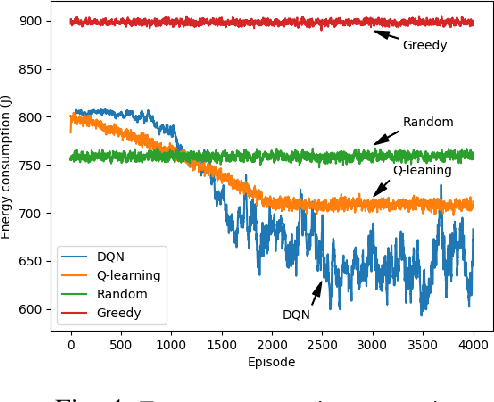
Blockchain-enabled Federated Learning (BFL) enables mobile devices to collaboratively train neural network models required by a Machine Learning Model Owner (MLMO) while keeping data on the mobile devices. Then, the model updates are stored in the blockchain in a decentralized and reliable manner. However, the issue of BFL is that the mobile devices have energy and CPU constraints that may reduce the system lifetime and training efficiency. The other issue is that the training latency may increase due to the blockchain mining process. To address these issues, the MLMO needs to (i) decide how much data and energy that the mobile devices use for the training and (ii) determine the block generation rate to minimize the system latency, energy consumption, and incentive cost while achieving the target accuracy for the model. Under the uncertainty of the BFL environment, it is challenging for the MLMO to determine the optimal decisions. We propose to use the Deep Reinforcement Learning (DRL) to derive the optimal decisions for the MLMO.
Deep Reinforcement Learning for Time Scheduling in RF-Powered Backscatter Cognitive Radio Networks
Oct 03, 2018

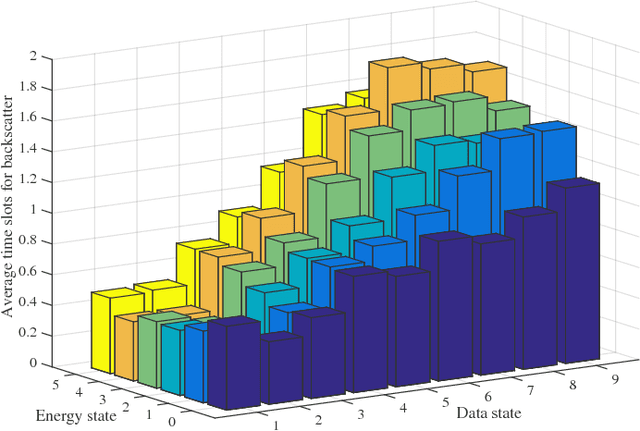
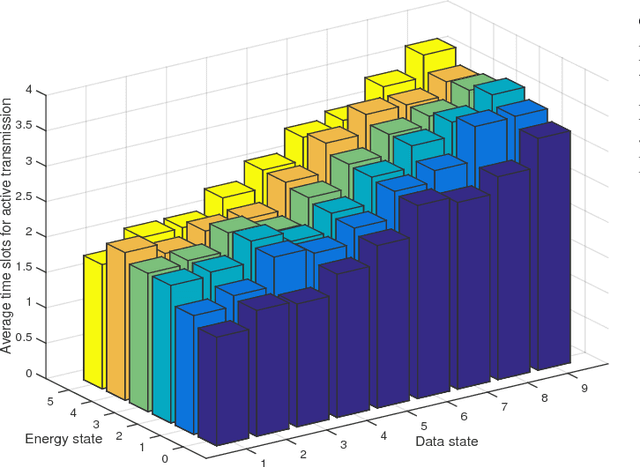
In an RF-powered backscatter cognitive radio network, multiple secondary users communicate with a secondary gateway by backscattering or harvesting energy and actively transmitting their data depending on the primary channel state. To coordinate the transmission of multiple secondary transmitters, the secondary gateway needs to schedule the backscattering time, energy harvesting time, and transmission time among them. However, under the dynamics of the primary channel and the uncertainty of the energy state of the secondary transmitters, it is challenging for the gateway to find a time scheduling mechanism which maximizes the total throughput. In this paper, we propose to use the deep reinforcement learning algorithm to derive an optimal time scheduling policy for the gateway. Specifically, to deal with the problem with large state and action spaces, we adopt a Double Deep-Q Network (DDQN) that enables the gateway to learn the optimal policy. The simulation results clearly show that the proposed deep reinforcement learning algorithm outperforms non-learning schemes in terms of network throughput.