 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Audio-Tagging Assisted Sound Event Detection using Weakified Strong Labels and Frequency Dynamic Convolutions
Apr 25, 2023



Jointly learning from a small labeled set and a larger unlabeled set is an active research topic under semi-supervised learning (SSL). In this paper, we propose a novel SSL method based on a two-stage framework for leveraging a large unlabeled in-domain set. Stage-1 of our proposed framework focuses on audio-tagging (AT), which assists the sound event detection (SED) system in Stage-2. The AT system is trained utilizing a strongly labeled set converted into weak predictions referred to as weakified set, a weakly labeled set, and an unlabeled set. This AT system then infers on the unlabeled set to generate reliable pseudo-weak labels, which are used with the strongly and weakly labeled set to train a frequency dynamic convolutional recurrent neural network-based SED system at Stage-2 in a supervised manner. Our system outperforms the baseline by 45.5% in terms of polyphonic sound detection score on the DESED real validation set.
Language-Based Audio Retrieval with Converging Tied Layers and Contrastive Loss
Jun 29, 2022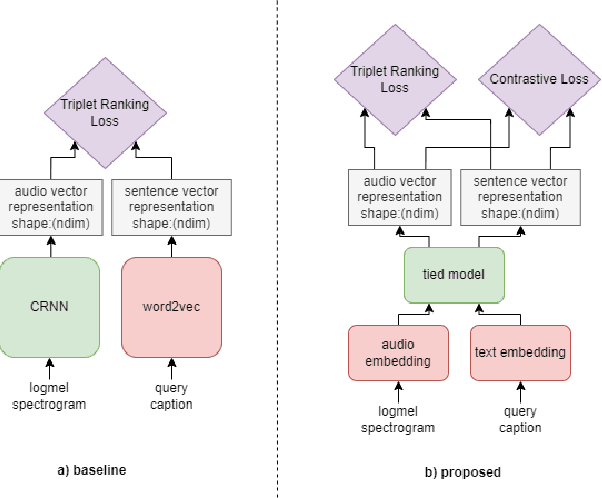

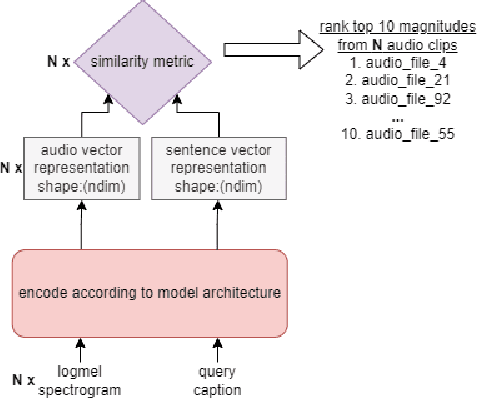
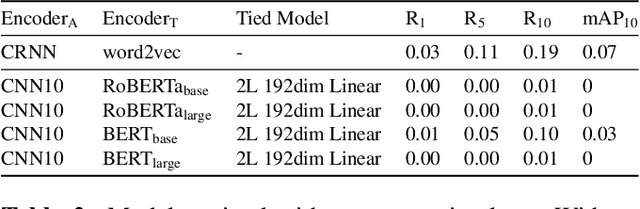
In this paper, we tackle the new Language-Based Audio Retrieval task proposed in DCASE 2022. Firstly, we introduce a simple, scalable architecture which ties both the audio and text encoder together. Secondly, we show that using this architecture along with contrastive loss allows the model to significantly beat the performance of the baseline model. Finally, in addition to having an extremely low training memory requirement, we are able to use pretrained models as it is without needing to finetune them. We test our methods and show that using a combination of our methods beats the baseline scores significantly.
Automated Audio Captioning with Epochal Difficult Captions for Curriculum Learning
Jun 04, 2022

In this paper, we propose an algorithm, Epochal Difficult Captions, to supplement the training of any model for the Automated Audio Captioning task. Epochal Difficult Captions is an elegant evolution to the keyword estimation task that previous work have used to train the encoder of the AAC model. Epochal Difficult Captions modifies the target captions based on a curriculum and a difficulty level determined as a function of current epoch. Epochal Difficult Captions can be used with any model architecture and is a lightweight function that does not increase training time. We test our results on three systems and show that using Epochal Difficult Captions consistently improves performance
Automated Audio Captioning using Transfer Learning and Reconstruction Latent Space Similarity Regularization
Aug 10, 2021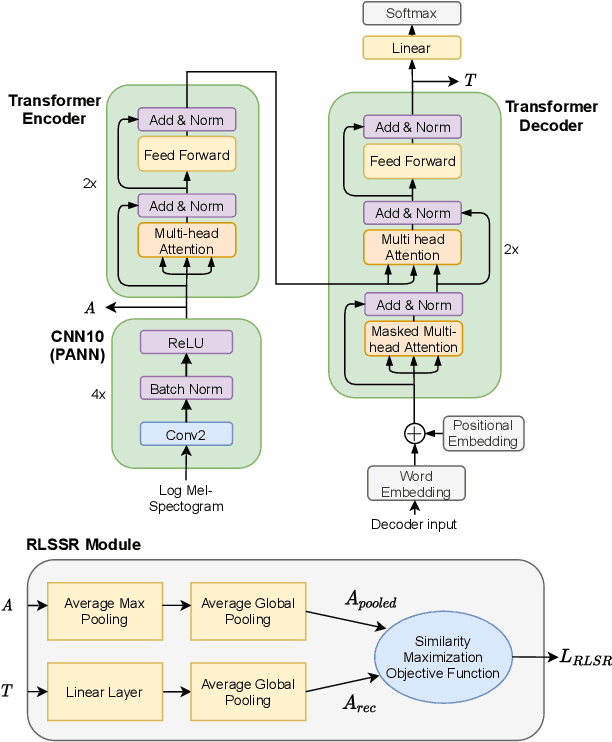

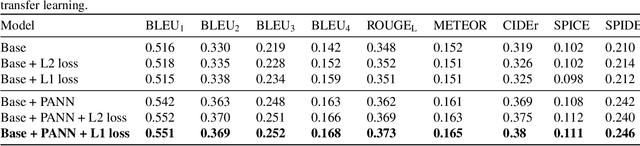

In this paper, we examine the use of Transfer Learning using Pretrained Audio Neural Networks (PANNs), and propose an architecture that is able to better leverage the acoustic features provided by PANNs for the Automated Audio Captioning Task. We also introduce a novel self-supervised objective, Reconstruction Latent Space Similarity Regularization (RLSSR). The RLSSR module supplements the training of the model by minimizing the similarity between the encoder and decoder embedding. The combination of both methods allows us to surpass state of the art results by a significant margin on the Clotho dataset across several metrics and benchmarks.
Adapting BERT for Word Sense Disambiguation with Gloss Selection Objective and Example Sentences
Oct 01, 2020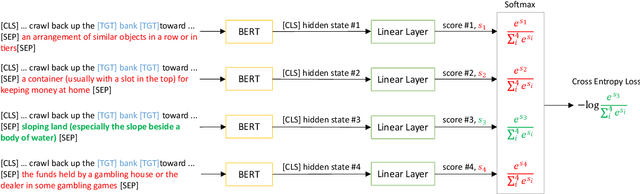
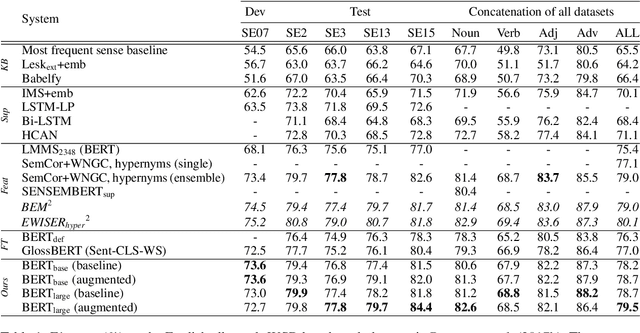

Domain adaptation or transfer learning using pre-trained language models such as BERT has proven to be an effective approach for many natural language processing tasks. In this work, we propose to formulate word sense disambiguation as a relevance ranking task, and fine-tune BERT on sequence-pair ranking task to select the most probable sense definition given a context sentence and a list of candidate sense definitions. We also introduce a data augmentation technique for WSD using existing example sentences from WordNet. Using the proposed training objective and data augmentation technique, our models are able to achieve state-of-the-art results on the English all-words benchmark datasets.