 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBona fide Cross Testing Reveals Weak Spot in Audio Deepfake Detection Systems
Sep 11, 2025Audio deepfake detection (ADD) models are commonly evaluated using datasets that combine multiple synthesizers, with performance reported as a single Equal Error Rate (EER). However, this approach disproportionately weights synthesizers with more samples, underrepresenting others and reducing the overall reliability of EER. Additionally, most ADD datasets lack diversity in bona fide speech, often featuring a single environment and speech style (e.g., clean read speech), limiting their ability to simulate real-world conditions. To address these challenges, we propose bona fide cross-testing, a novel evaluation framework that incorporates diverse bona fide datasets and aggregates EERs for more balanced assessments. Our approach improves robustness and interpretability compared to traditional evaluation methods. We benchmark over 150 synthesizers across nine bona fide speech types and release a new dataset to facilitate further research at https://github.com/cyaaronk/audio_deepfake_eval.
Improving Synthetic Data Training for Contextual Biasing Models with a Keyword-Aware Cost Function
Sep 11, 2025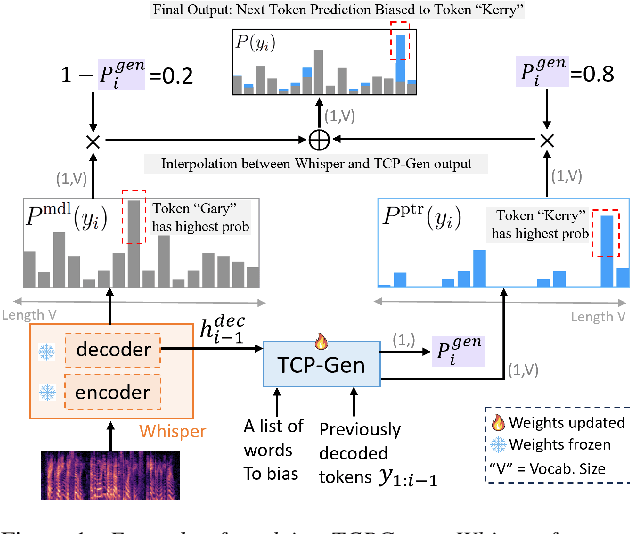
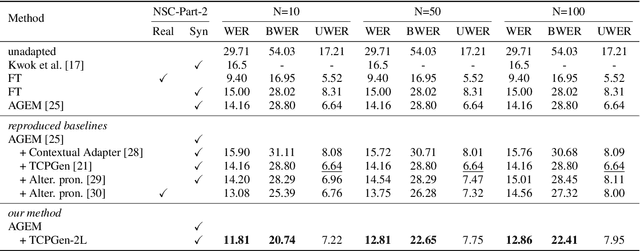
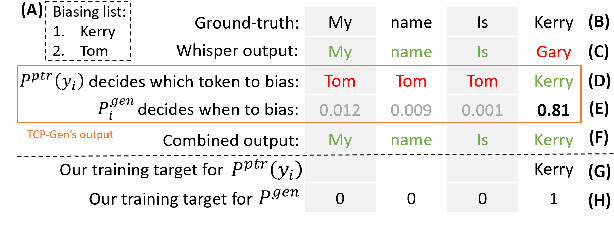
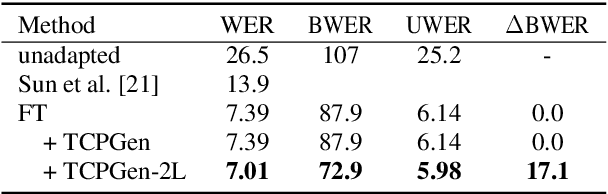
Rare word recognition can be improved by adapting ASR models to synthetic data that includes these words. Further improvements can be achieved through contextual biasing, which trains and adds a biasing module into the model architecture to prioritize rare words. While training the module on synthetic rare word data is more effective than using non-rare-word data, it can lead to overfitting due to artifacts in the synthetic audio. To address this, we enhance the TCPGen-based contextual biasing approach and propose a keyword-aware loss function that additionally focuses on biased words when training biasing modules. This loss includes a masked cross-entropy term for biased word prediction and a binary classification term for detecting biased word positions. These two terms complementarily support the decoding of biased words during inference. By adapting Whisper to 10 hours of synthetic data, our method reduced the word error rate on the NSC Part 2 test set from 29.71% to 11.81%.
Speechless: Speech Instruction Training Without Speech for Low Resource Languages
May 23, 2025The rapid growth of voice assistants powered by large language models (LLM) has highlighted a need for speech instruction data to train these systems. Despite the abundance of speech recognition data, there is a notable scarcity of speech instruction data, which is essential for fine-tuning models to understand and execute spoken commands. Generating high-quality synthetic speech requires a good text-to-speech (TTS) model, which may not be available to low resource languages. Our novel approach addresses this challenge by halting synthesis at the semantic representation level, bypassing the need for TTS. We achieve this by aligning synthetic semantic representations with the pre-trained Whisper encoder, enabling an LLM to be fine-tuned on text instructions while maintaining the ability to understand spoken instructions during inference. This simplified training process is a promising approach to building voice assistant for low-resource languages.
Speech Enhancement Using Continuous Embeddings of Neural Audio Codec
Feb 22, 2025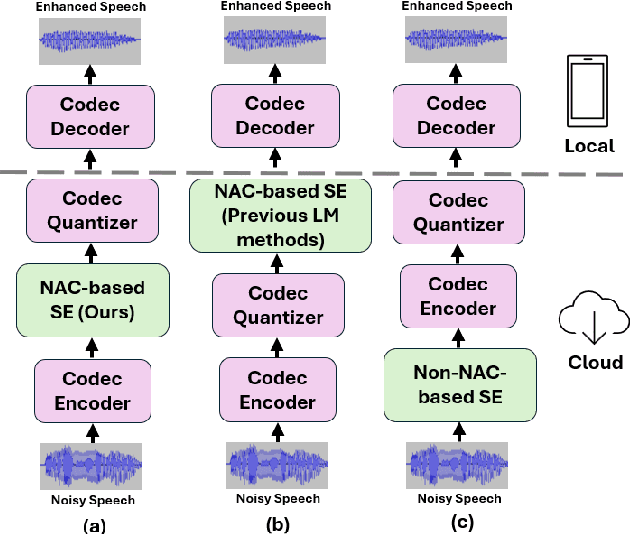
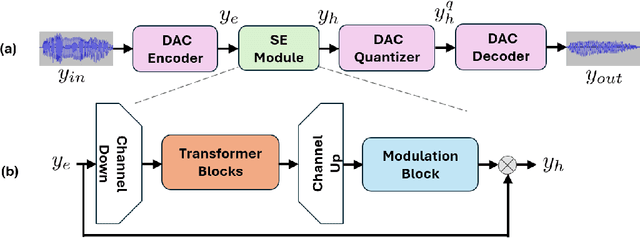

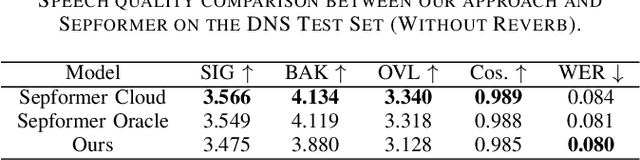
Recent advancements in Neural Audio Codec (NAC) models have inspired their use in various speech processing tasks, including speech enhancement (SE). In this work, we propose a novel, efficient SE approach by leveraging the pre-quantization output of a pretrained NAC encoder. Unlike prior NAC-based SE methods, which process discrete speech tokens using Language Models (LMs), we perform SE within the continuous embedding space of the pretrained NAC, which is highly compressed along the time dimension for efficient representation. Our lightweight SE model, optimized through an embedding-level loss, delivers results comparable to SE baselines trained on larger datasets, with a significantly lower real-time factor of 0.005. Additionally, our method achieves a low GMAC of 3.94, reducing complexity 18-fold compared to Sepformer in a simulated cloud-based audio transmission environment. This work highlights a new, efficient NAC-based SE solution, particularly suitable for cloud applications where NAC is used to compress audio before transmission. Copyright 20XX IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works.
Continual Learning with Embedding Layer Surgery and Task-wise Beam Search using Whisper
Jan 14, 2025Current Multilingual ASR models only support a fraction of the world's languages. Continual Learning (CL) aims to tackle this problem by adding new languages to pre-trained models while avoiding the loss of performance on existing languages, also known as Catastrophic Forgetting (CF). However, existing CL methods overlook the adaptation of the token embedding lookup table at the decoder, despite its significant contribution to CF. We propose Embedding Layer Surgery where separate copies of the token embeddings are created for each new languages, and one of the copies is selected to replace the old languages embeddings when transcribing the corresponding new language. Unfortunately, this approach means LID errors also cause incorrect ASR embedding selection. Our Task-wise Beam Search allows self-correction for such mistakes. By adapting Whisper to 10 hours of data for each of 10 unseen languages from Common Voice, results show that our method reduces the Average WER (AWER) of pre-trained languages from 14.2% to 11.9% compared with Experience Replay, without compromising the AWER of the unseen languages.
VERSA: A Versatile Evaluation Toolkit for Speech, Audio, and Music
Dec 23, 2024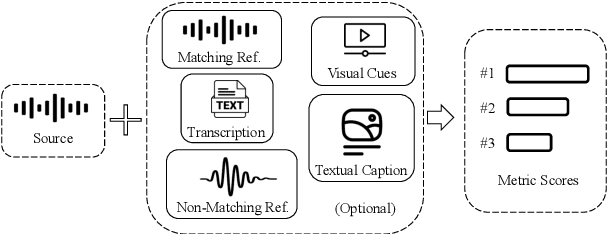
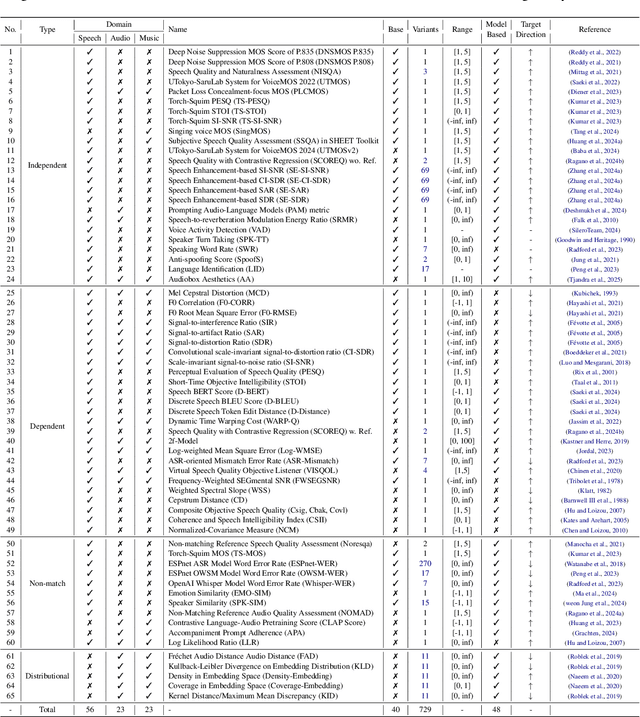

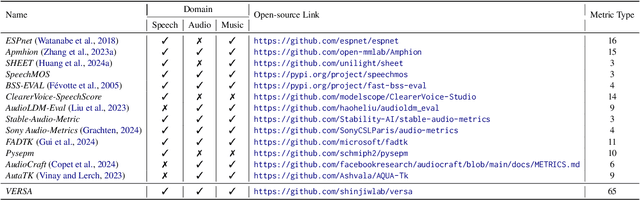
In this work, we introduce VERSA, a unified and standardized evaluation toolkit designed for various speech, audio, and music signals. The toolkit features a Pythonic interface with flexible configuration and dependency control, making it user-friendly and efficient. With full installation, VERSA offers 63 metrics with 711 metric variations based on different configurations. These metrics encompass evaluations utilizing diverse external resources, including matching and non-matching reference audio, text transcriptions, and text captions. As a lightweight yet comprehensive toolkit, VERSA is versatile to support the evaluation of a wide range of downstream scenarios. To demonstrate its capabilities, this work highlights example use cases for VERSA, including audio coding, speech synthesis, speech enhancement, singing synthesis, and music generation. The toolkit is available at https://github.com/shinjiwlab/versa.
Speech Separation using Neural Audio Codecs with Embedding Loss
Nov 27, 2024



Neural audio codecs have revolutionized audio processing by enabling speech tasks to be performed on highly compressed representations. Recent work has shown that speech separation can be achieved within these compressed domains, offering faster training and reduced inference costs. However, current approaches still rely on waveform-based loss functions, necessitating unnecessary decoding steps during training. We propose a novel embedding loss for neural audio codec-based speech separation that operates directly on compressed audio representations, eliminating the need for decoding during training. To validate our approach, we conduct comprehensive evaluations using both objective metrics and perceptual assessment techniques, including intrusive and non-intrusive methods. Our results demonstrate that embedding loss can be used to train codec-based speech separation models with a 2x improvement in training speed and computational cost while achieving better DNSMOS and STOI performance on the WSJ0-2mix dataset across 3 different pre-trained codecs.
Dynamic-SUPERB Phase-2: A Collaboratively Expanding Benchmark for Measuring the Capabilities of Spoken Language Models with 180 Tasks
Nov 08, 2024



Multimodal foundation models, such as Gemini and ChatGPT, have revolutionized human-machine interactions by seamlessly integrating various forms of data. Developing a universal spoken language model that comprehends a wide range of natural language instructions is critical for bridging communication gaps and facilitating more intuitive interactions. However, the absence of a comprehensive evaluation benchmark poses a significant challenge. We present Dynamic-SUPERB Phase-2, an open and evolving benchmark for the comprehensive evaluation of instruction-based universal speech models. Building upon the first generation, this second version incorporates 125 new tasks contributed collaboratively by the global research community, expanding the benchmark to a total of 180 tasks, making it the largest benchmark for speech and audio evaluation. While the first generation of Dynamic-SUPERB was limited to classification tasks, Dynamic-SUPERB Phase-2 broadens its evaluation capabilities by introducing a wide array of novel and diverse tasks, including regression and sequence generation, across speech, music, and environmental audio. Evaluation results indicate that none of the models performed well universally. SALMONN-13B excelled in English ASR, while WavLLM demonstrated high accuracy in emotion recognition, but current models still require further innovations to handle a broader range of tasks. We will soon open-source all task data and the evaluation pipeline.
Emotional Dimension Control in Language Model-Based Text-to-Speech: Spanning a Broad Spectrum of Human Emotions
Sep 25, 2024Current emotional text-to-speech (TTS) systems face challenges in mimicking a broad spectrum of human emotions due to the inherent complexity of emotions and limitations in emotional speech datasets and models. This paper proposes a TTS framework that facilitates control over pleasure, arousal, and dominance, and can synthesize a diversity of emotional styles without requiring any emotional speech data during TTS training. We train an emotional attribute predictor using only categorical labels from speech data, aligning with psychological research and incorporating anchored dimensionality reduction on self-supervised learning (SSL) features. The TTS framework converts text inputs into phonetic tokens via an autoregressive language model and uses pseudo-emotional dimensions to guide the parallel prediction of fine-grained acoustic details. Experiments conducted on the LibriTTS dataset demonstrate that our framework can synthesize speech with enhanced naturalness and a variety of emotional styles by effectively controlling emotional dimensions, even without the inclusion of any emotional speech during TTS training.
ESPnet-Codec: Comprehensive Training and Evaluation of Neural Codecs for Audio, Music, and Speech
Sep 24, 2024Neural codecs have become crucial to recent speech and audio generation research. In addition to signal compression capabilities, discrete codecs have also been found to enhance downstream training efficiency and compatibility with autoregressive language models. However, as extensive downstream applications are investigated, challenges have arisen in ensuring fair comparisons across diverse applications. To address these issues, we present a new open-source platform ESPnet-Codec, which is built on ESPnet and focuses on neural codec training and evaluation. ESPnet-Codec offers various recipes in audio, music, and speech for training and evaluation using several widely adopted codec models. Together with ESPnet-Codec, we present VERSA, a standalone evaluation toolkit, which provides a comprehensive evaluation of codec performance over 20 audio evaluation metrics. Notably, we demonstrate that ESPnet-Codec can be integrated into six ESPnet tasks, supporting diverse applications.