 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBona fide Cross Testing Reveals Weak Spot in Audio Deepfake Detection Systems
Sep 11, 2025Audio deepfake detection (ADD) models are commonly evaluated using datasets that combine multiple synthesizers, with performance reported as a single Equal Error Rate (EER). However, this approach disproportionately weights synthesizers with more samples, underrepresenting others and reducing the overall reliability of EER. Additionally, most ADD datasets lack diversity in bona fide speech, often featuring a single environment and speech style (e.g., clean read speech), limiting their ability to simulate real-world conditions. To address these challenges, we propose bona fide cross-testing, a novel evaluation framework that incorporates diverse bona fide datasets and aggregates EERs for more balanced assessments. Our approach improves robustness and interpretability compared to traditional evaluation methods. We benchmark over 150 synthesizers across nine bona fide speech types and release a new dataset to facilitate further research at https://github.com/cyaaronk/audio_deepfake_eval.
Improving Synthetic Data Training for Contextual Biasing Models with a Keyword-Aware Cost Function
Sep 11, 2025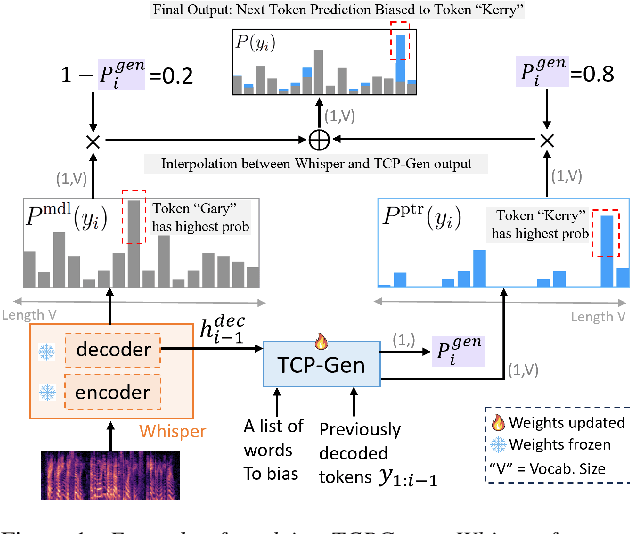
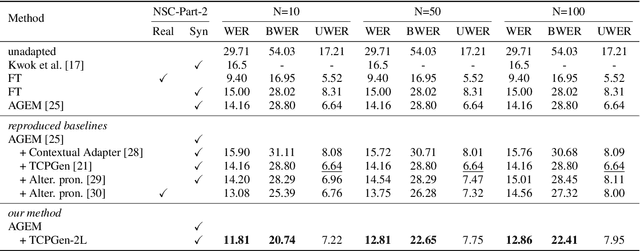
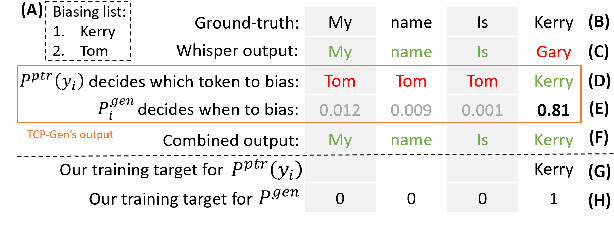
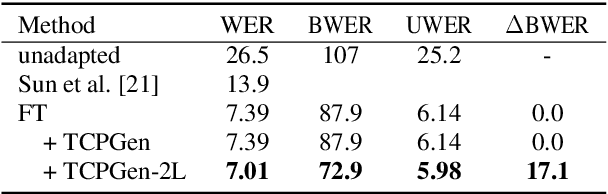
Rare word recognition can be improved by adapting ASR models to synthetic data that includes these words. Further improvements can be achieved through contextual biasing, which trains and adds a biasing module into the model architecture to prioritize rare words. While training the module on synthetic rare word data is more effective than using non-rare-word data, it can lead to overfitting due to artifacts in the synthetic audio. To address this, we enhance the TCPGen-based contextual biasing approach and propose a keyword-aware loss function that additionally focuses on biased words when training biasing modules. This loss includes a masked cross-entropy term for biased word prediction and a binary classification term for detecting biased word positions. These two terms complementarily support the decoding of biased words during inference. By adapting Whisper to 10 hours of synthetic data, our method reduced the word error rate on the NSC Part 2 test set from 29.71% to 11.81%.
Efficient Trie-based Biasing using K-step Prediction for Rare Word Recognition
Sep 11, 2025Contextual biasing improves rare word recognition of ASR models by prioritizing the output of rare words during decoding. A common approach is Trie-based biasing, which gives "bonus scores" to partial hypothesis (e.g. "Bon") that may lead to the generation of the rare word (e.g. "Bonham"). If the full word ("Bonham") isn't ultimately recognized, the system revokes those earlier bonuses. This revocation is limited to beam search and is computationally expensive, particularly for models with large decoders. To overcome these limitations, we propose adapting ASR models to look ahead and predict multiple steps at once. This avoids the revocation step entirely by better estimating whether a partial hypothesis will lead to the generation of the full rare word. By fine-tuning Whisper with only 10 hours of synthetic data, our method reduces the word error rate on the NSC Part 2 test set from 30.86% to 12.19%.
Continual Learning with Embedding Layer Surgery and Task-wise Beam Search using Whisper
Jan 14, 2025Current Multilingual ASR models only support a fraction of the world's languages. Continual Learning (CL) aims to tackle this problem by adding new languages to pre-trained models while avoiding the loss of performance on existing languages, also known as Catastrophic Forgetting (CF). However, existing CL methods overlook the adaptation of the token embedding lookup table at the decoder, despite its significant contribution to CF. We propose Embedding Layer Surgery where separate copies of the token embeddings are created for each new languages, and one of the copies is selected to replace the old languages embeddings when transcribing the corresponding new language. Unfortunately, this approach means LID errors also cause incorrect ASR embedding selection. Our Task-wise Beam Search allows self-correction for such mistakes. By adapting Whisper to 10 hours of data for each of 10 unseen languages from Common Voice, results show that our method reduces the Average WER (AWER) of pre-trained languages from 14.2% to 11.9% compared with Experience Replay, without compromising the AWER of the unseen languages.
Speech Separation using Neural Audio Codecs with Embedding Loss
Nov 27, 2024



Neural audio codecs have revolutionized audio processing by enabling speech tasks to be performed on highly compressed representations. Recent work has shown that speech separation can be achieved within these compressed domains, offering faster training and reduced inference costs. However, current approaches still rely on waveform-based loss functions, necessitating unnecessary decoding steps during training. We propose a novel embedding loss for neural audio codec-based speech separation that operates directly on compressed audio representations, eliminating the need for decoding during training. To validate our approach, we conduct comprehensive evaluations using both objective metrics and perceptual assessment techniques, including intrusive and non-intrusive methods. Our results demonstrate that embedding loss can be used to train codec-based speech separation models with a 2x improvement in training speed and computational cost while achieving better DNSMOS and STOI performance on the WSJ0-2mix dataset across 3 different pre-trained codecs.
Continual Learning Optimizations for Auto-regressive Decoder of Multilingual ASR systems
Jul 04, 2024Continual Learning (CL) involves fine-tuning pre-trained models with new data while maintaining the performance on the pre-trained data. This is particularly relevant for expanding multilingual ASR (MASR) capabilities. However, existing CL methods, mainly designed for computer vision and reinforcement learning tasks, often yield sub-optimal results when directly applied to MASR. We hypothesise that this is because CL of the auto-regressive decoder in the MASR model is difficult. To verify this, we propose four optimizations on the decoder. They include decoder-layer gradient surgery, freezing unused token embeddings, suppressing output of newly added tokens, and learning rate re-scaling. Our experiments on adapting Whisper to 10 unseen languages from the Common Voice dataset demonstrate that these optimizations reduce the Average Word Error Rate (AWER) of pretrained languages from 14.2% to 12.4% compared with Experience Replay, without compromising the AWER of new languages.