 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Model and Layer Fusion for Speech Foundation Models
Nov 11, 2025



Speech Foundation Models have gained significant attention recently. Prior works have shown that the fusion of representations from multiple layers of the same model or the fusion of multiple models can improve performance on downstream tasks. We unify these two fusion strategies by proposing an interface module that enables fusion across multiple upstream speech models while integrating information across their layers. We conduct extensive experiments on different self-supervised and supervised models across various speech tasks, including ASR and paralinguistic analysis, and demonstrate that our method outperforms prior fusion approaches. We further analyze its scalability concerning model size and count, highlighting the importance of selecting appropriate upstream models. Our results show that the proposed interface provides an additional performance boost when given a suitable upstream model selection, making it a promising approach for utilizing Speech Foundation Models.
Dynamic-SUPERB Phase-2: A Collaboratively Expanding Benchmark for Measuring the Capabilities of Spoken Language Models with 180 Tasks
Nov 08, 2024



Multimodal foundation models, such as Gemini and ChatGPT, have revolutionized human-machine interactions by seamlessly integrating various forms of data. Developing a universal spoken language model that comprehends a wide range of natural language instructions is critical for bridging communication gaps and facilitating more intuitive interactions. However, the absence of a comprehensive evaluation benchmark poses a significant challenge. We present Dynamic-SUPERB Phase-2, an open and evolving benchmark for the comprehensive evaluation of instruction-based universal speech models. Building upon the first generation, this second version incorporates 125 new tasks contributed collaboratively by the global research community, expanding the benchmark to a total of 180 tasks, making it the largest benchmark for speech and audio evaluation. While the first generation of Dynamic-SUPERB was limited to classification tasks, Dynamic-SUPERB Phase-2 broadens its evaluation capabilities by introducing a wide array of novel and diverse tasks, including regression and sequence generation, across speech, music, and environmental audio. Evaluation results indicate that none of the models performed well universally. SALMONN-13B excelled in English ASR, while WavLLM demonstrated high accuracy in emotion recognition, but current models still require further innovations to handle a broader range of tasks. We will soon open-source all task data and the evaluation pipeline.
Self-supervised Speech Models for Word-Level Stuttered Speech Detection
Sep 16, 2024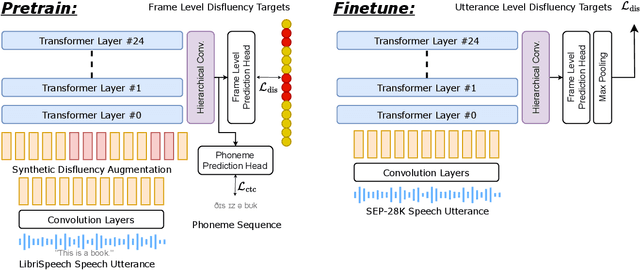
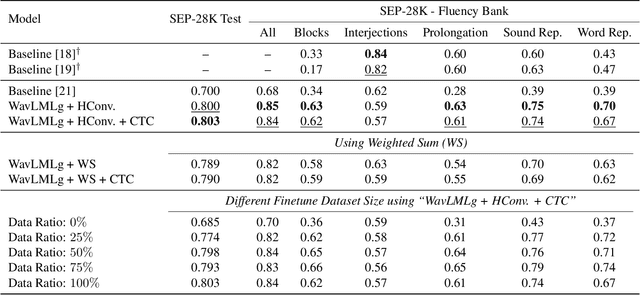
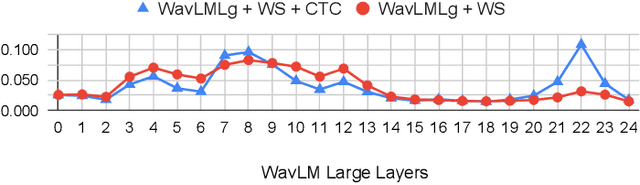
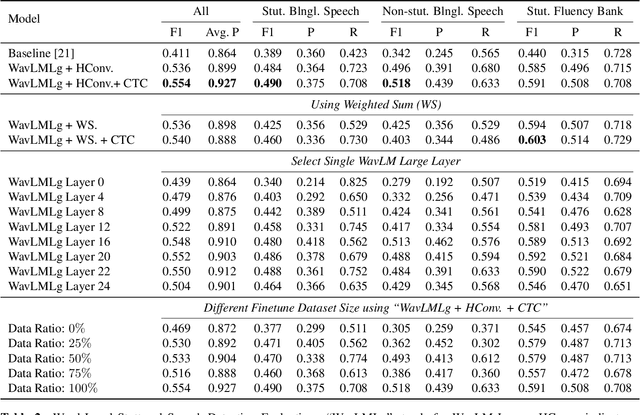
Clinical diagnosis of stuttering requires an assessment by a licensed speech-language pathologist. However, this process is time-consuming and requires clinicians with training and experience in stuttering and fluency disorders. Unfortunately, only a small percentage of speech-language pathologists report being comfortable working with individuals who stutter, which is inadequate to accommodate for the 80 million individuals who stutter worldwide. Developing machine learning models for detecting stuttered speech would enable universal and automated screening for stuttering, enabling speech pathologists to identify and follow up with patients who are most likely to be diagnosed with a stuttering speech disorder. Previous research in this area has predominantly focused on utterance-level detection, which is not sufficient for clinical settings where word-level annotation of stuttering is the norm. In this study, we curated a stuttered speech dataset with word-level annotations and introduced a word-level stuttering speech detection model leveraging self-supervised speech models. Our evaluation demonstrates that our model surpasses previous approaches in word-level stuttering speech detection. Additionally, we conducted an extensive ablation analysis of our method, providing insight into the most important aspects of adapting self-supervised speech models for stuttered speech detection.
Interface Design for Self-Supervised Speech Models
Jun 18, 2024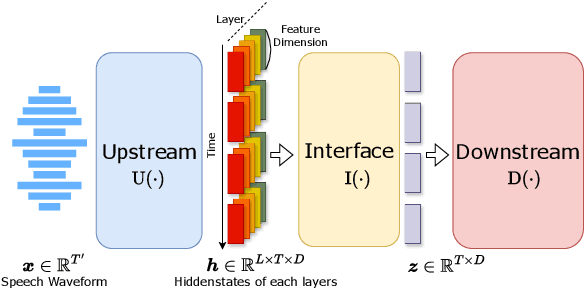
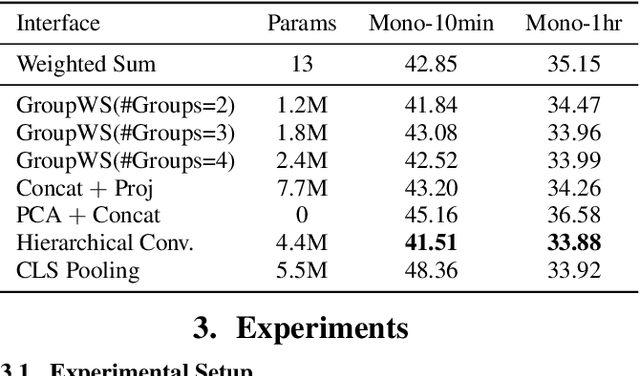
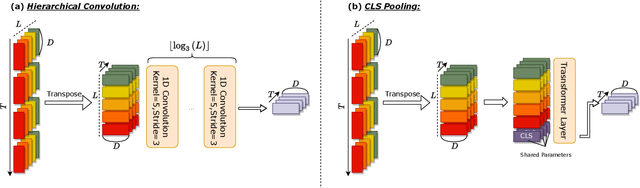
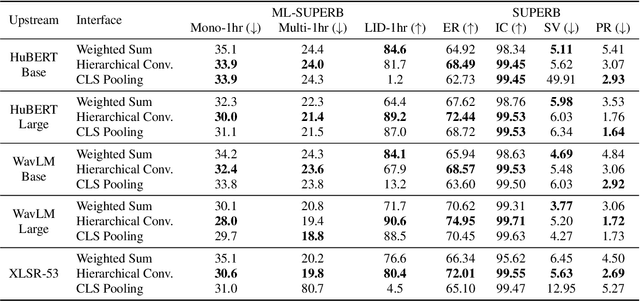
Self-supervised speech (SSL) models have recently become widely adopted for many downstream speech processing tasks. The general usage pattern is to employ SSL models as feature extractors, and then train a downstream prediction head to solve a specific task. However, different layers of SSL models have been shown to capture different types of information, and the methods of combining them are not well studied. To this end, we extend the general framework for SSL model utilization by proposing the interface that connects the upstream and downstream. Under this view, the dominant technique of combining features via a layerwise weighted sum can be regarded as a specific interface. We propose several alternative interface designs and demonstrate that the weighted sum interface is suboptimal for many tasks. In particular, we show that a convolutional interface whose depth scales logarithmically with the depth of the upstream model consistently outperforms many other interface designs.
SpeechCLIP+: Self-supervised multi-task representation learning for speech via CLIP and speech-image data
Feb 10, 2024The recently proposed visually grounded speech model SpeechCLIP is an innovative framework that bridges speech and text through images via CLIP without relying on text transcription. On this basis, this paper introduces two extensions to SpeechCLIP. First, we apply the Continuous Integrate-and-Fire (CIF) module to replace a fixed number of CLS tokens in the cascaded architecture. Second, we propose a new hybrid architecture that merges the cascaded and parallel architectures of SpeechCLIP into a multi-task learning framework. Our experimental evaluation is performed on the Flickr8k and SpokenCOCO datasets. The results show that in the speech keyword extraction task, the CIF-based cascaded SpeechCLIP model outperforms the previous cascaded SpeechCLIP model using a fixed number of CLS tokens. Furthermore, through our hybrid architecture, cascaded task learning boosts the performance of the parallel branch in image-speech retrieval tasks.
Integrating Self-supervised Speech Model with Pseudo Word-level Targets from Visually-grounded Speech Model
Feb 08, 2024Recent advances in self-supervised speech models have shown significant improvement in many downstream tasks. However, these models predominantly centered on frame-level training objectives, which can fall short in spoken language understanding tasks that require semantic comprehension. Existing works often rely on additional speech-text data as intermediate targets, which is costly in the real-world setting. To address this challenge, we propose Pseudo-Word HuBERT (PW-HuBERT), a framework that integrates pseudo word-level targets into the training process, where the targets are derived from a visually-ground speech model, notably eliminating the need for speech-text paired data. Our experimental results on four spoken language understanding (SLU) benchmarks suggest the superiority of our model in capturing semantic information.
AV-SUPERB: A Multi-Task Evaluation Benchmark for Audio-Visual Representation Models
Sep 19, 2023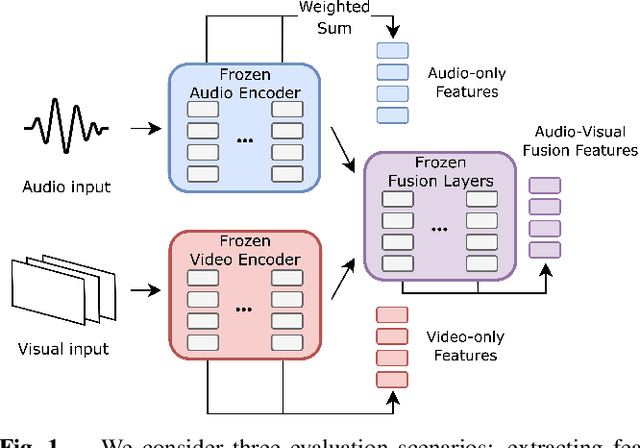
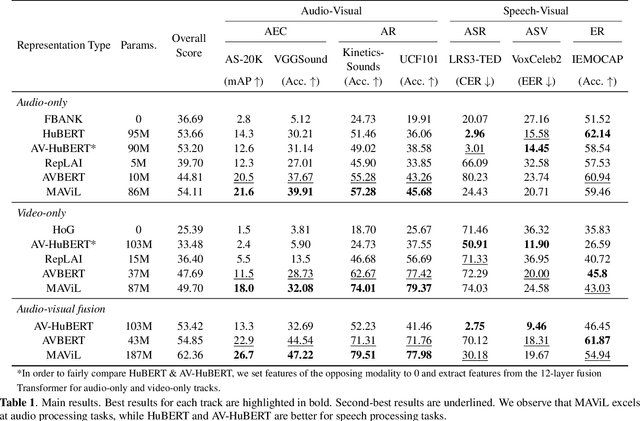
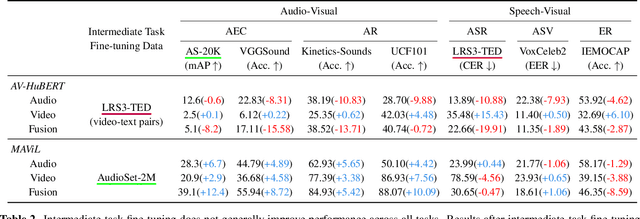
Audio-visual representation learning aims to develop systems with human-like perception by utilizing correlation between auditory and visual information. However, current models often focus on a limited set of tasks, and generalization abilities of learned representations are unclear. To this end, we propose the AV-SUPERB benchmark that enables general-purpose evaluation of unimodal audio/visual and bimodal fusion representations on 7 datasets covering 5 audio-visual tasks in speech and audio processing. We evaluate 5 recent self-supervised models and show that none of these models generalize to all tasks, emphasizing the need for future study on improving universal model performance. In addition, we show that representations may be improved with intermediate-task fine-tuning and audio event classification with AudioSet serves as a strong intermediate task. We release our benchmark with evaluation code and a model submission platform to encourage further research in audio-visual learning.
M-SpeechCLIP: Leveraging Large-Scale, Pre-Trained Models for Multilingual Speech to Image Retrieval
Nov 02, 2022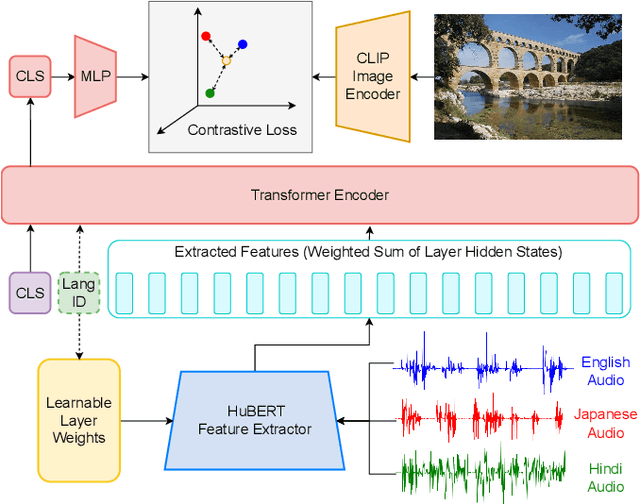
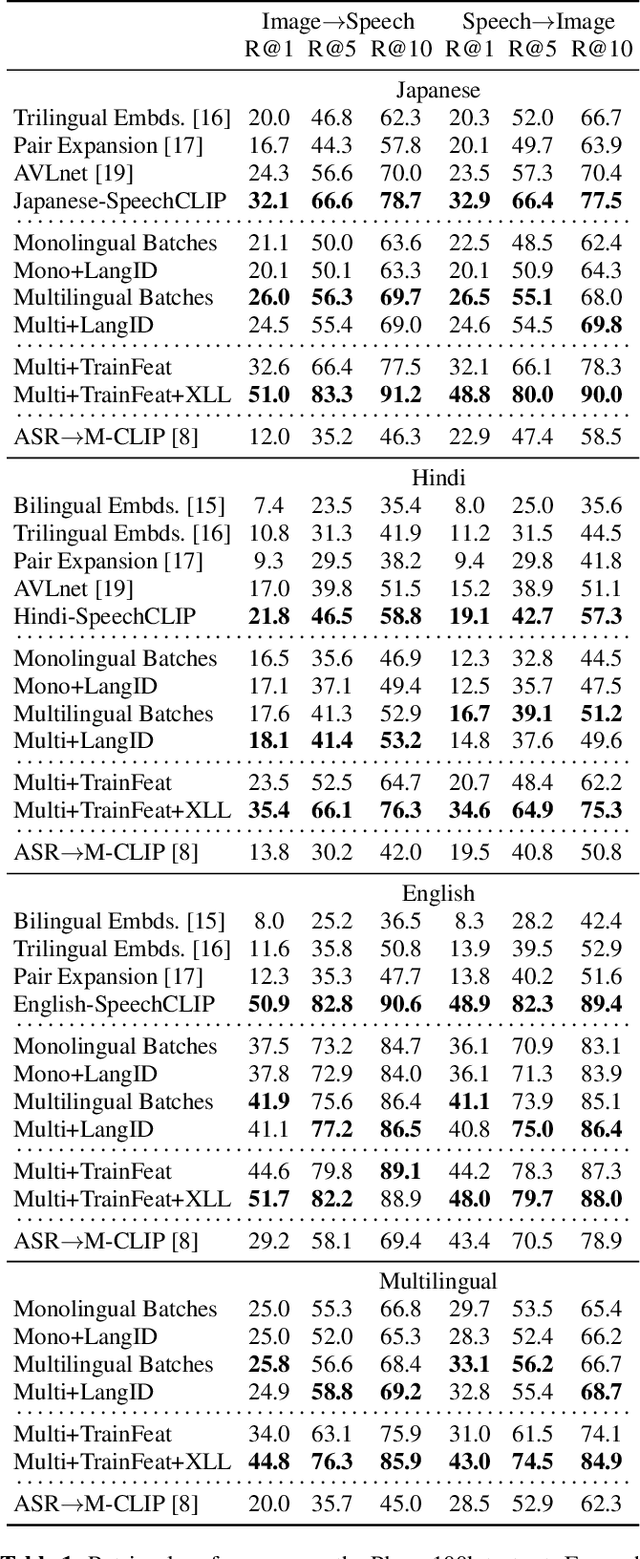
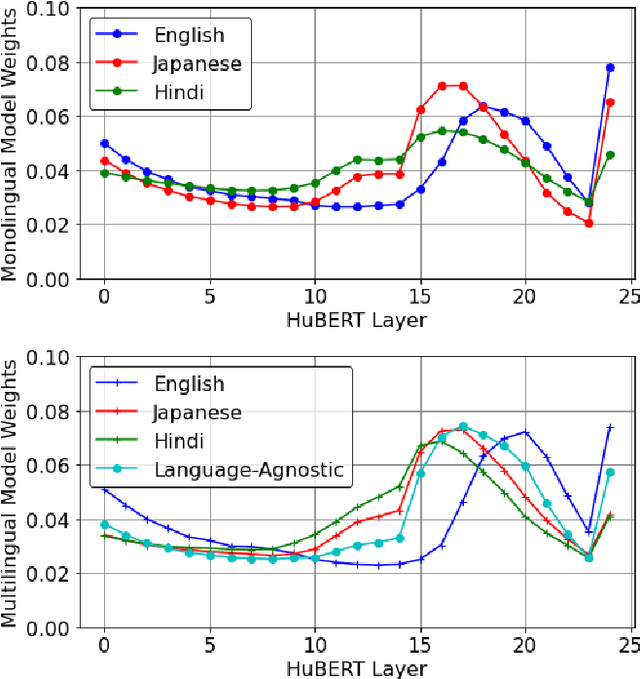
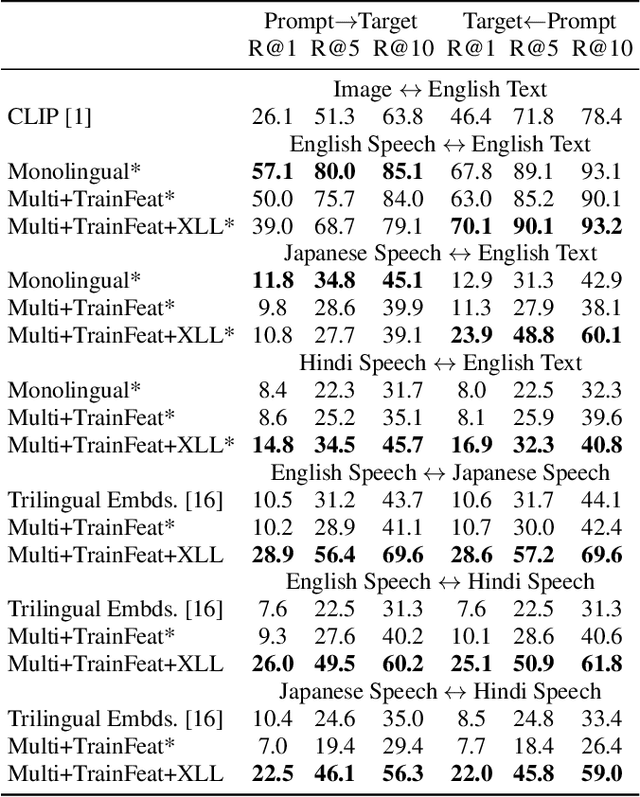
This work investigates the use of large-scale, pre-trained models (CLIP and HuBERT) for multilingual speech-image retrieval. For non-English speech-image retrieval, we outperform the current state-of-the-art performance by a wide margin when training separate models for each language, and show that a single model which processes speech in all three languages still achieves retrieval scores comparable with the prior state-of-the-art. We identify key differences in model behavior and performance between English and non-English settings, presumably attributable to the English-only pre-training of CLIP and HuBERT. Finally, we show that our models can be used for mono- and cross-lingual speech-text retrieval and cross-lingual speech-speech retrieval, despite never having seen any parallel speech-text or speech-speech data during training.
SpeechCLIP: Integrating Speech with Pre-Trained Vision and Language Model
Oct 03, 2022



Data-driven speech processing models usually perform well with a large amount of text supervision, but collecting transcribed speech data is costly. Therefore, we propose SpeechCLIP, a novel framework bridging speech and text through images to enhance speech models without transcriptions. We leverage state-of-the-art pre-trained HuBERT and CLIP, aligning them via paired images and spoken captions with minimal fine-tuning. SpeechCLIP outperforms prior state-of-the-art on image-speech retrieval and performs zero-shot speech-text retrieval without direct supervision from transcriptions. Moreover, SpeechCLIP can directly retrieve semantically related keywords from speech.
Theme Transformer: Symbolic Music Generation with Theme-Conditioned Transformer
Nov 07, 2021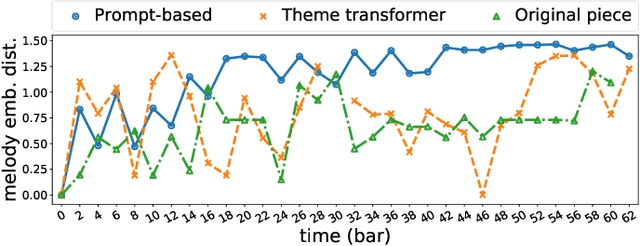
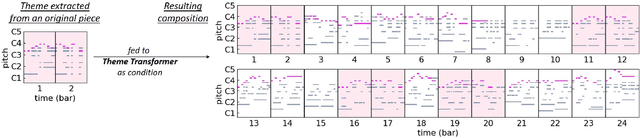
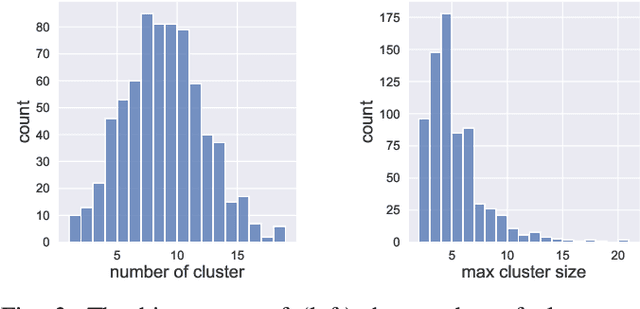
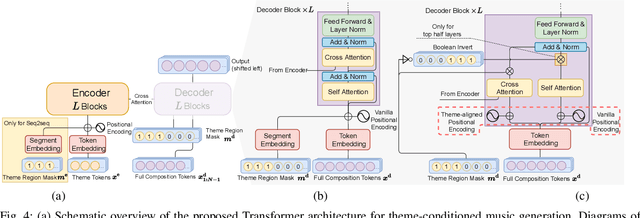
Attention-based Transformer models have been increasingly employed for automatic music generation. To condition the generation process of such a model with a user-specified sequence, a popular approach is to take that conditioning sequence as a priming sequence and ask a Transformer decoder to generate a continuation. However, this prompt-based conditioning cannot guarantee that the conditioning sequence would develop or even simply repeat itself in the generated continuation. In this paper, we propose an alternative conditioning approach, called theme-based conditioning, that explicitly trains the Transformer to treat the conditioning sequence as a thematic material that has to manifest itself multiple times in its generation result. This is achieved with two main technical contributions. First, we propose a deep learning-based approach that uses contrastive representation learning and clustering to automatically retrieve thematic materials from music pieces in the training data. Second, we propose a novel gated parallel attention module to be used in a sequence-to-sequence (seq2seq) encoder/decoder architecture to more effectively account for a given conditioning thematic material in the generation process of the Transformer decoder. We report on objective and subjective evaluations of variants of the proposed Theme Transformer and the conventional prompt-based baseline, showing that our best model can generate, to some extent, polyphonic pop piano music with repetition and plausible variations of a given condition.