 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM-SpeechCLIP: Leveraging Large-Scale, Pre-Trained Models for Multilingual Speech to Image Retrieval
Paper and Code
Nov 02, 2022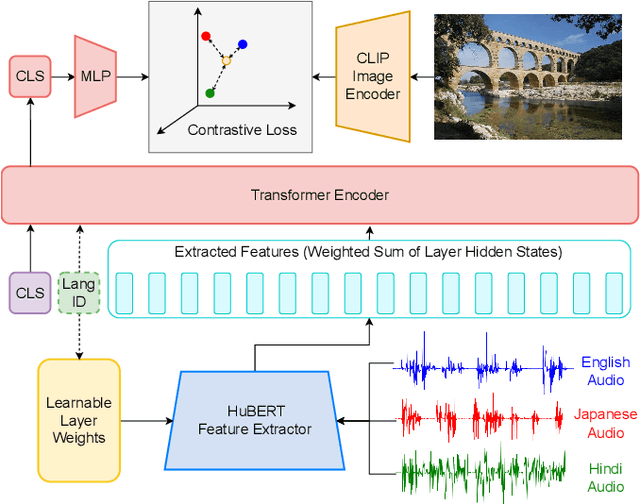
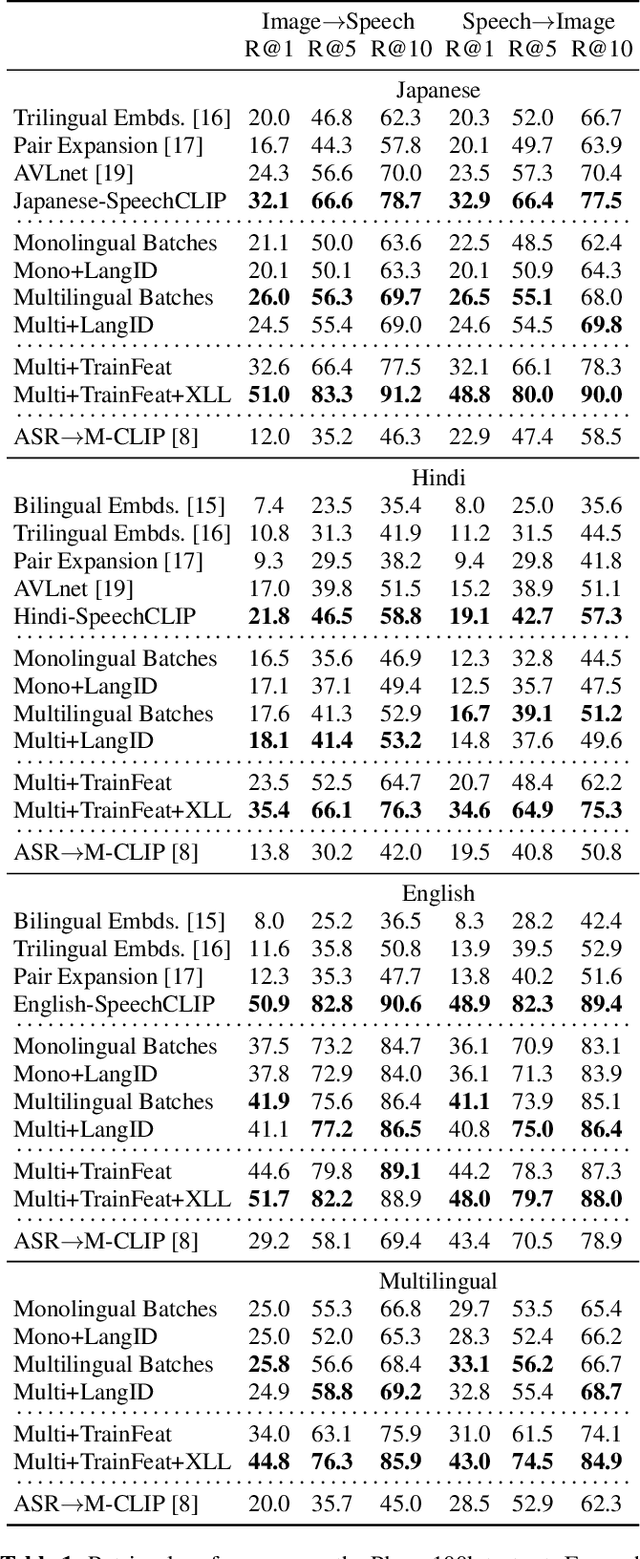
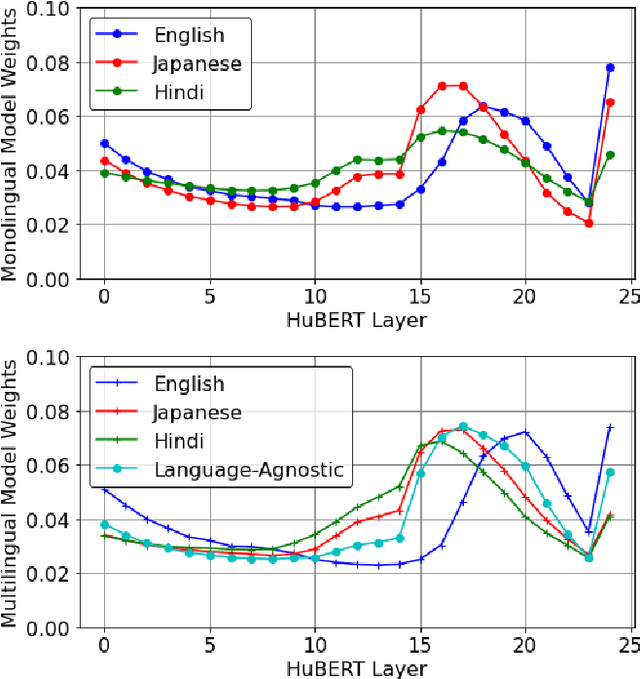
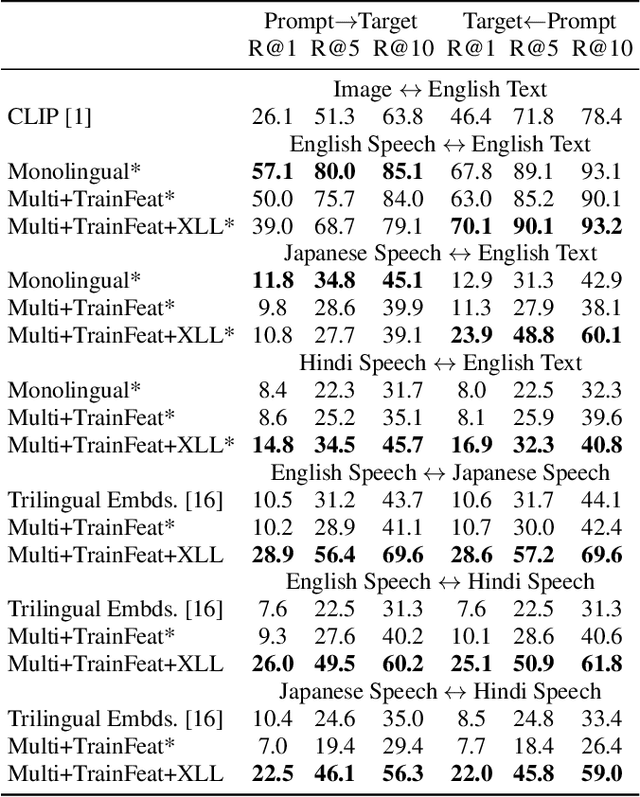
This work investigates the use of large-scale, pre-trained models (CLIP and HuBERT) for multilingual speech-image retrieval. For non-English speech-image retrieval, we outperform the current state-of-the-art performance by a wide margin when training separate models for each language, and show that a single model which processes speech in all three languages still achieves retrieval scores comparable with the prior state-of-the-art. We identify key differences in model behavior and performance between English and non-English settings, presumably attributable to the English-only pre-training of CLIP and HuBERT. Finally, we show that our models can be used for mono- and cross-lingual speech-text retrieval and cross-lingual speech-speech retrieval, despite never having seen any parallel speech-text or speech-speech data during training.