 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the Frontier of Audiovisual Perception with Large-Scale Multimodal Correspondence Learning
Dec 22, 2025We introduce Perception Encoder Audiovisual, PE-AV, a new family of encoders for audio and video understanding trained with scaled contrastive learning. Built on PE, PE-AV makes several key contributions to extend representations to audio, and natively support joint embeddings across audio-video, audio-text, and video-text modalities. PE-AV's unified cross-modal embeddings enable novel tasks such as speech retrieval, and set a new state of the art across standard audio and video benchmarks. We unlock this by building a strong audiovisual data engine that synthesizes high-quality captions for O(100M) audio-video pairs, enabling large-scale supervision consistent across modalities. Our audio data includes speech, music, and general sound effects-avoiding single-domain limitations common in prior work. We exploit ten pairwise contrastive objectives, showing that scaling cross-modality and caption-type pairs strengthens alignment and improves zero-shot performance. We further develop PE-A-Frame by fine-tuning PE-AV with frame-level contrastive objectives, enabling fine-grained audio-frame-to-text alignment for tasks such as sound event detection.
USAD: Universal Speech and Audio Representation via Distillation
Jun 23, 2025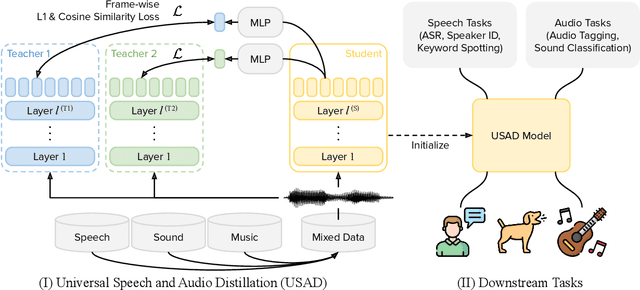
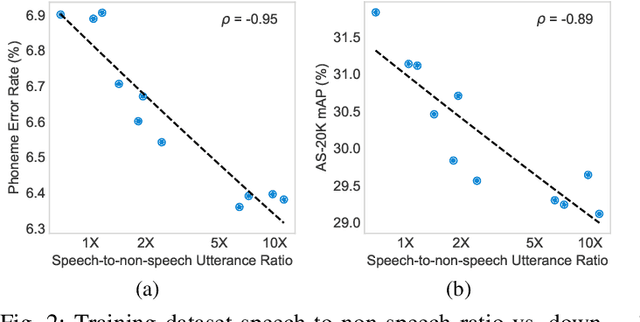
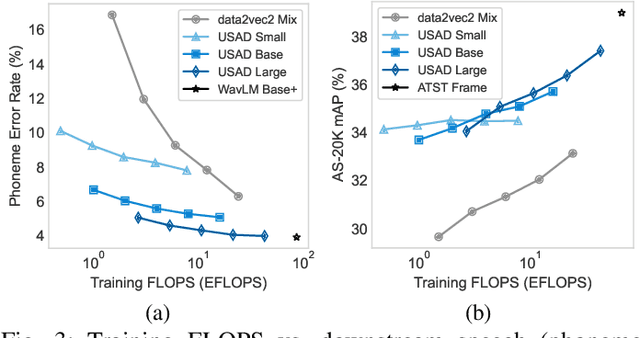
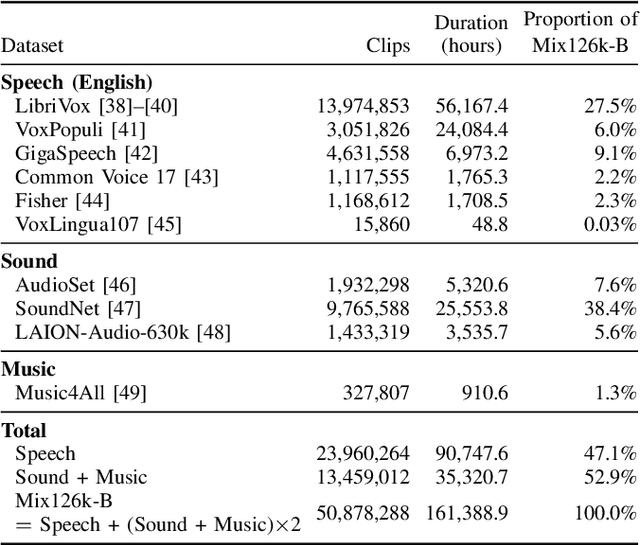
Self-supervised learning (SSL) has revolutionized audio representations, yet models often remain domain-specific, focusing on either speech or non-speech tasks. In this work, we present Universal Speech and Audio Distillation (USAD), a unified approach to audio representation learning that integrates diverse audio types - speech, sound, and music - into a single model. USAD employs efficient layer-to-layer distillation from domain-specific SSL models to train a student on a comprehensive audio dataset. USAD offers competitive performance across various benchmarks and datasets, including frame and instance-level speech processing tasks, audio tagging, and sound classification, achieving near state-of-the-art results with a single encoder on SUPERB and HEAR benchmarks.
DC-Spin: A Speaker-invariant Speech Tokenizer for Spoken Language Models
Oct 31, 2024Spoken language models (SLMs) have gained increasing attention with advancements in text-based, decoder-only language models. SLMs process text and speech, enabling simultaneous speech understanding and generation. This paper presents Double-Codebook Speaker-invariant Clustering (DC-Spin), which aims to improve speech tokenization by bridging audio signals and SLM tokens. DC-Spin extracts speaker-invariant tokens rich in phonetic information and resilient to input variations, enhancing zero-shot SLM tasks and speech resynthesis. We propose a chunk-wise approach to enable streamable DC-Spin without retraining and degradation. Comparisons of tokenization methods (self-supervised and neural audio codecs), model scalability, and downstream task proxies show that tokens easily modeled by an n-gram LM or aligned with phonemes offer strong performance, providing insights for designing speech tokenizers for SLMs.
A Large-Scale Evaluation of Speech Foundation Models
Apr 15, 2024The foundation model paradigm leverages a shared foundation model to achieve state-of-the-art (SOTA) performance for various tasks, requiring minimal downstream-specific modeling and data annotation. This approach has proven crucial in the field of Natural Language Processing (NLP). However, the speech processing community lacks a similar setup to explore the paradigm systematically. In this work, we establish the Speech processing Universal PERformance Benchmark (SUPERB) to study the effectiveness of the paradigm for speech. We propose a unified multi-tasking framework to address speech processing tasks in SUPERB using a frozen foundation model followed by task-specialized, lightweight prediction heads. Combining our results with community submissions, we verify that the foundation model paradigm is promising for speech, and our multi-tasking framework is simple yet effective, as the best-performing foundation model shows competitive generalizability across most SUPERB tasks. For reproducibility and extensibility, we have developed a long-term maintained platform that enables deterministic benchmarking, allows for result sharing via an online leaderboard, and promotes collaboration through a community-driven benchmark database to support new development cycles. Finally, we conduct a series of analyses to offer an in-depth understanding of SUPERB and speech foundation models, including information flows across tasks inside the models, the correctness of the weighted-sum benchmarking protocol and the statistical significance and robustness of the benchmark.
SpeechCLIP+: Self-supervised multi-task representation learning for speech via CLIP and speech-image data
Feb 10, 2024The recently proposed visually grounded speech model SpeechCLIP is an innovative framework that bridges speech and text through images via CLIP without relying on text transcription. On this basis, this paper introduces two extensions to SpeechCLIP. First, we apply the Continuous Integrate-and-Fire (CIF) module to replace a fixed number of CLS tokens in the cascaded architecture. Second, we propose a new hybrid architecture that merges the cascaded and parallel architectures of SpeechCLIP into a multi-task learning framework. Our experimental evaluation is performed on the Flickr8k and SpokenCOCO datasets. The results show that in the speech keyword extraction task, the CIF-based cascaded SpeechCLIP model outperforms the previous cascaded SpeechCLIP model using a fixed number of CLS tokens. Furthermore, through our hybrid architecture, cascaded task learning boosts the performance of the parallel branch in image-speech retrieval tasks.
R-Spin: Efficient Speaker and Noise-invariant Representation Learning with Acoustic Pieces
Nov 15, 2023This paper introduces Robust Spin (R-Spin), a data-efficient self-supervised fine-tuning framework for speaker and noise-invariant speech representations by learning discrete acoustic units with speaker-invariant clustering (Spin). R-Spin resolves Spin's issues and enhances content representations by learning to predict acoustic pieces. R-Spin offers a 12X reduction in computational resources compared to previous state-of-the-art methods while outperforming them in severely distorted speech scenarios. This paper provides detailed analyses to show how discrete units contribute to speech encoder training and improving robustness in diverse acoustic environments.
CoLLD: Contrastive Layer-to-layer Distillation for Compressing Multilingual Pre-trained Speech Encoders
Sep 14, 2023

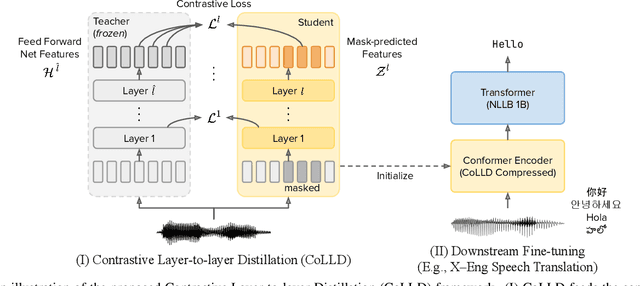

Large-scale self-supervised pre-trained speech encoders outperform conventional approaches in speech recognition and translation tasks. Due to the high cost of developing these large models, building new encoders for new tasks and deploying them to on-device applications are infeasible. Prior studies propose model compression methods to address this issue, but those works focus on smaller models and less realistic tasks. Thus, we propose Contrastive Layer-to-layer Distillation (CoLLD), a novel knowledge distillation method to compress pre-trained speech encoders by leveraging masked prediction and contrastive learning to train student models to copy the behavior of a large teacher model. CoLLD outperforms prior methods and closes the gap between small and large models on multilingual speech-to-text translation and recognition benchmarks.
Self-supervised Fine-tuning for Improved Content Representations by Speaker-invariant Clustering
May 18, 2023Self-supervised speech representation models have succeeded in various tasks, but improving them for content-related problems using unlabeled data is challenging. We propose speaker-invariant clustering (Spin), a novel self-supervised learning method that clusters speech representations and performs swapped prediction between the original and speaker-perturbed utterances. Spin disentangles speaker information and preserves content representations with just 45 minutes of fine-tuning on a single GPU. Spin improves pre-trained networks and outperforms prior methods in speech recognition and acoustic unit discovery.
DinoSR: Self-Distillation and Online Clustering for Self-supervised Speech Representation Learning
May 17, 2023



In this paper, we introduce self-distillation and online clustering for self-supervised speech representation learning (DinoSR) which combines masked language modeling, self-distillation, and online clustering. We show that these concepts complement each other and result in a strong representation learning model for speech. DinoSR first extracts contextualized embeddings from the input audio with a teacher network, then runs an online clustering system on the embeddings to yield a machine-discovered phone inventory, and finally uses the discretized tokens to guide a student network. We show that DinoSR surpasses previous state-of-the-art performance in several downstream tasks, and provide a detailed analysis of the model and the learned discrete units. The source code will be made available after the anonymity period.
M-SpeechCLIP: Leveraging Large-Scale, Pre-Trained Models for Multilingual Speech to Image Retrieval
Nov 02, 2022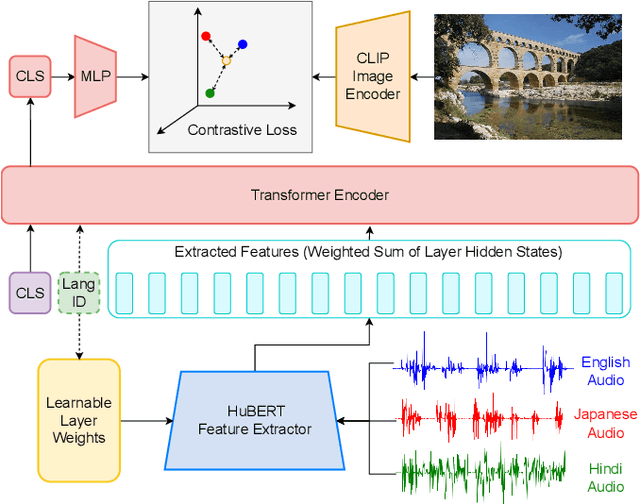
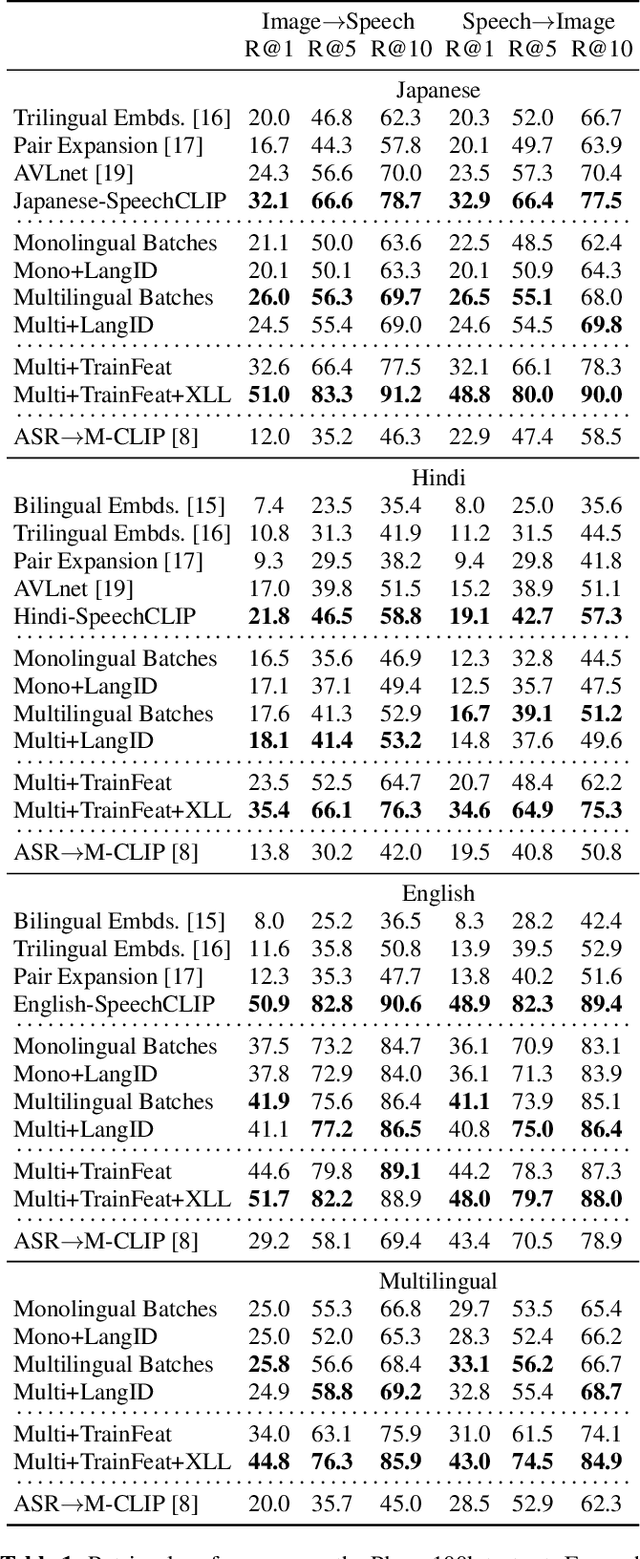
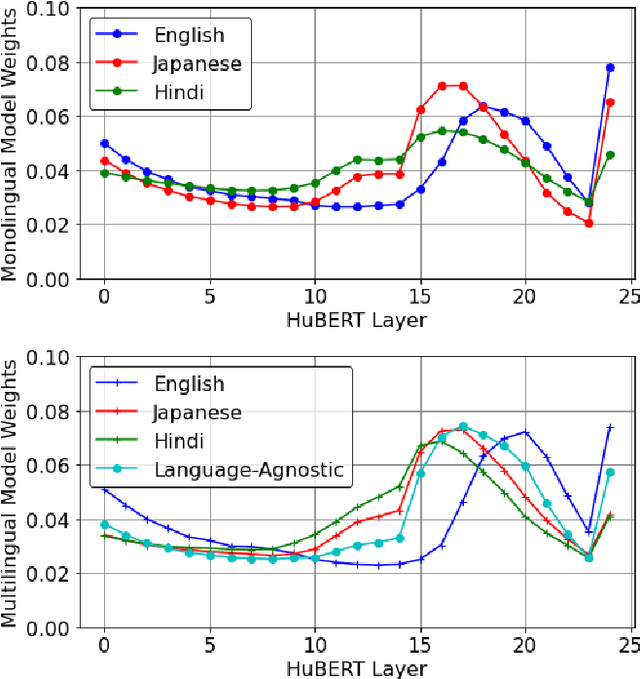
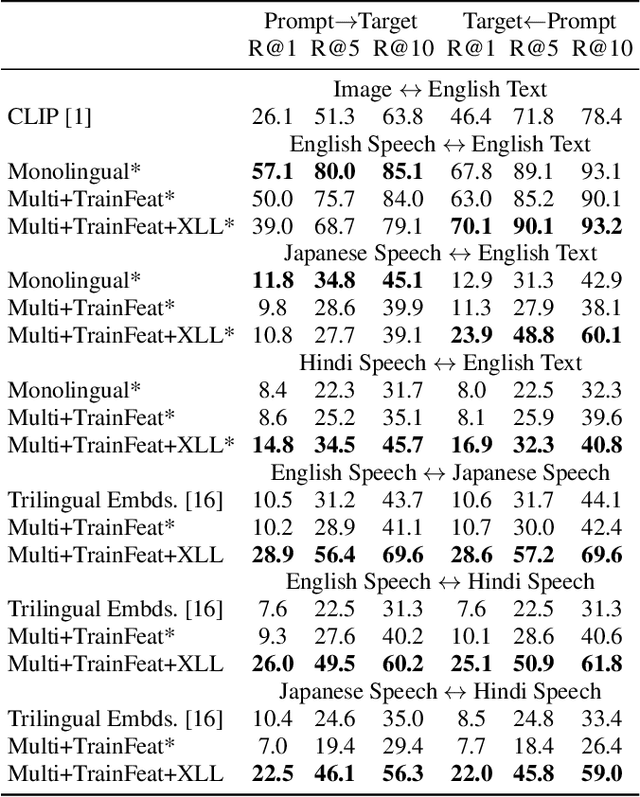
This work investigates the use of large-scale, pre-trained models (CLIP and HuBERT) for multilingual speech-image retrieval. For non-English speech-image retrieval, we outperform the current state-of-the-art performance by a wide margin when training separate models for each language, and show that a single model which processes speech in all three languages still achieves retrieval scores comparable with the prior state-of-the-art. We identify key differences in model behavior and performance between English and non-English settings, presumably attributable to the English-only pre-training of CLIP and HuBERT. Finally, we show that our models can be used for mono- and cross-lingual speech-text retrieval and cross-lingual speech-speech retrieval, despite never having seen any parallel speech-text or speech-speech data during training.