 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Speech Models for Word-Level Stuttered Speech Detection
Sep 16, 2024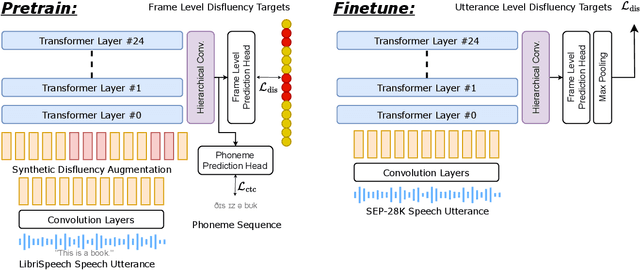
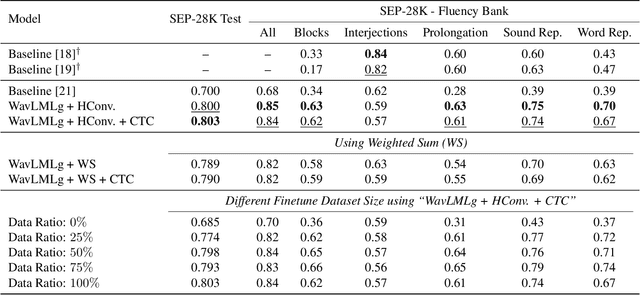
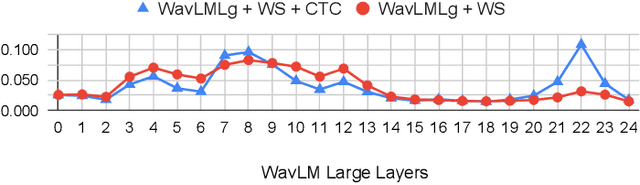
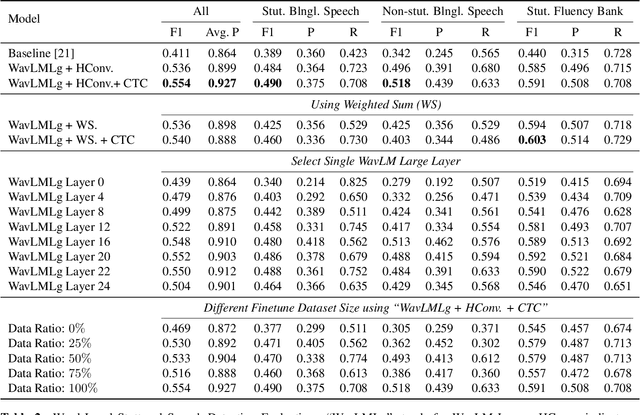
Clinical diagnosis of stuttering requires an assessment by a licensed speech-language pathologist. However, this process is time-consuming and requires clinicians with training and experience in stuttering and fluency disorders. Unfortunately, only a small percentage of speech-language pathologists report being comfortable working with individuals who stutter, which is inadequate to accommodate for the 80 million individuals who stutter worldwide. Developing machine learning models for detecting stuttered speech would enable universal and automated screening for stuttering, enabling speech pathologists to identify and follow up with patients who are most likely to be diagnosed with a stuttering speech disorder. Previous research in this area has predominantly focused on utterance-level detection, which is not sufficient for clinical settings where word-level annotation of stuttering is the norm. In this study, we curated a stuttered speech dataset with word-level annotations and introduced a word-level stuttering speech detection model leveraging self-supervised speech models. Our evaluation demonstrates that our model surpasses previous approaches in word-level stuttering speech detection. Additionally, we conducted an extensive ablation analysis of our method, providing insight into the most important aspects of adapting self-supervised speech models for stuttered speech detection.