 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParaSpeechCLAP: A Dual-Encoder Speech-Text Model for Rich Stylistic Language-Audio Pretraining
Mar 30, 2026We introduce ParaSpeechCLAP, a dual-encoder contrastive model that maps speech and text style captions into a common embedding space, supporting a wide range of intrinsic (speaker-level) and situational (utterance-level) descriptors (such as pitch, texture and emotion) far beyond the narrow set handled by existing models. We train specialized ParaSpeechCLAP-Intrinsic and ParaSpeechCLAP-Situational models alongside a unified ParaSpeechCLAP-Combined model, finding that specialization yields stronger performance on individual style dimensions while the unified model excels on compositional evaluation. We further show that ParaSpeechCLAP-Intrinsic benefits from an additional classification loss and class-balanced training. We demonstrate our models' performance on style caption retrieval, speech attribute classification and as an inference-time reward model that improves style-prompted TTS without additional training. ParaSpeechCLAP outperforms baselines on most metrics across all three applications. Our models and code are released at https://github.com/ajd12342/paraspeechclap .
VoiceCraft-X: Unifying Multilingual, Voice-Cloning Speech Synthesis and Speech Editing
Nov 15, 2025We introduce VoiceCraft-X, an autoregressive neural codec language model which unifies multilingual speech editing and zero-shot Text-to-Speech (TTS) synthesis across 11 languages: English, Mandarin, Korean, Japanese, Spanish, French, German, Dutch, Italian, Portuguese, and Polish. VoiceCraft-X utilizes the Qwen3 large language model for phoneme-free cross-lingual text processing and a novel token reordering mechanism with time-aligned text and speech tokens to handle both tasks as a single sequence generation problem. The model generates high-quality, natural-sounding speech, seamlessly creating new audio or editing existing recordings within one framework. VoiceCraft-X shows robust performance in diverse linguistic settings, even with limited per-language data, underscoring the power of unified autoregressive approaches for advancing complex, real-world multilingual speech applications. Audio samples are available at https://zhishengzheng.com/voicecraft-x/.
CS-FLEURS: A Massively Multilingual and Code-Switched Speech Dataset
Sep 17, 2025We present CS-FLEURS, a new dataset for developing and evaluating code-switched speech recognition and translation systems beyond high-resourced languages. CS-FLEURS consists of 4 test sets which cover in total 113 unique code-switched language pairs across 52 languages: 1) a 14 X-English language pair set with real voices reading synthetically generated code-switched sentences, 2) a 16 X-English language pair set with generative text-to-speech 3) a 60 {Arabic, Mandarin, Hindi, Spanish}-X language pair set with the generative text-to-speech, and 4) a 45 X-English lower-resourced language pair test set with concatenative text-to-speech. Besides the four test sets, CS-FLEURS also provides a training set with 128 hours of generative text-to-speech data across 16 X-English language pairs. Our hope is that CS-FLEURS helps to broaden the scope of future code-switched speech research. Dataset link: https://huggingface.co/datasets/byan/cs-fleurs.
Rhapsody: A Dataset for Highlight Detection in Podcasts
May 26, 2025Podcasts have become daily companions for half a billion users. Given the enormous amount of podcast content available, highlights provide a valuable signal that helps viewers get the gist of an episode and decide if they want to invest in listening to it in its entirety. However, identifying highlights automatically is challenging due to the unstructured and long-form nature of the content. We introduce Rhapsody, a dataset of 13K podcast episodes paired with segment-level highlight scores derived from YouTube's 'most replayed' feature. We frame the podcast highlight detection as a segment-level binary classification task. We explore various baseline approaches, including zero-shot prompting of language models and lightweight finetuned language models using segment-level classification heads. Our experimental results indicate that even state-of-the-art language models like GPT-4o and Gemini struggle with this task, while models finetuned with in-domain data significantly outperform their zero-shot performance. The finetuned model benefits from leveraging both speech signal features and transcripts. These findings highlight the challenges for fine-grained information access in long-form spoken media.
Scaling Rich Style-Prompted Text-to-Speech Datasets
Mar 06, 2025We introduce Paralinguistic Speech Captions (ParaSpeechCaps), a large-scale dataset that annotates speech utterances with rich style captions. While rich abstract tags (e.g. guttural, nasal, pained) have been explored in small-scale human-annotated datasets, existing large-scale datasets only cover basic tags (e.g. low-pitched, slow, loud). We combine off-the-shelf text and speech embedders, classifiers and an audio language model to automatically scale rich tag annotations for the first time. ParaSpeechCaps covers a total of 59 style tags, including both speaker-level intrinsic tags and utterance-level situational tags. It consists of 342 hours of human-labelled data (PSC-Base) and 2427 hours of automatically annotated data (PSC-Scaled). We finetune Parler-TTS, an open-source style-prompted TTS model, on ParaSpeechCaps, and achieve improved style consistency (+7.9% Consistency MOS) and speech quality (+15.5% Naturalness MOS) over the best performing baseline that combines existing rich style tag datasets. We ablate several of our dataset design choices to lay the foundation for future work in this space. Our dataset, models and code are released at https://github.com/ajd12342/paraspeechcaps .
Dynamic-SUPERB Phase-2: A Collaboratively Expanding Benchmark for Measuring the Capabilities of Spoken Language Models with 180 Tasks
Nov 08, 2024



Multimodal foundation models, such as Gemini and ChatGPT, have revolutionized human-machine interactions by seamlessly integrating various forms of data. Developing a universal spoken language model that comprehends a wide range of natural language instructions is critical for bridging communication gaps and facilitating more intuitive interactions. However, the absence of a comprehensive evaluation benchmark poses a significant challenge. We present Dynamic-SUPERB Phase-2, an open and evolving benchmark for the comprehensive evaluation of instruction-based universal speech models. Building upon the first generation, this second version incorporates 125 new tasks contributed collaboratively by the global research community, expanding the benchmark to a total of 180 tasks, making it the largest benchmark for speech and audio evaluation. While the first generation of Dynamic-SUPERB was limited to classification tasks, Dynamic-SUPERB Phase-2 broadens its evaluation capabilities by introducing a wide array of novel and diverse tasks, including regression and sequence generation, across speech, music, and environmental audio. Evaluation results indicate that none of the models performed well universally. SALMONN-13B excelled in English ASR, while WavLLM demonstrated high accuracy in emotion recognition, but current models still require further innovations to handle a broader range of tasks. We will soon open-source all task data and the evaluation pipeline.
When to Use Efficient Self Attention? Profiling Text, Speech and Image Transformer Variants
Jun 14, 2023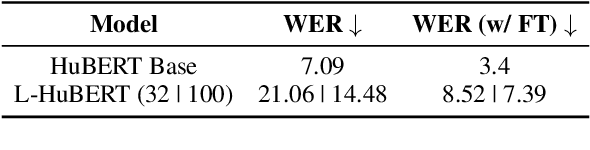



We present the first unified study of the efficiency of self-attention-based Transformer variants spanning text, speech and vision. We identify input length thresholds (tipping points) at which efficient Transformer variants become more efficient than vanilla models, using a variety of efficiency metrics (latency, throughput, and memory). To conduct this analysis for speech, we introduce L-HuBERT, a novel local-attention variant of a self-supervised speech model. We observe that these thresholds are (a) much higher than typical dataset sequence lengths and (b) dependent on the metric and modality, showing that choosing the right model depends on modality, task type (long-form vs. typical context) and resource constraints (time vs. memory). By visualising the breakdown of the computational costs for transformer components, we also show that non-self-attention components exhibit significant computational costs. We release our profiling toolkit at https://github.com/ajd12342/profiling-transformers .
Unit-based Speech-to-Speech Translation Without Parallel Data
May 24, 2023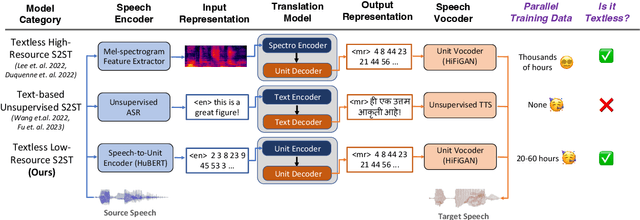
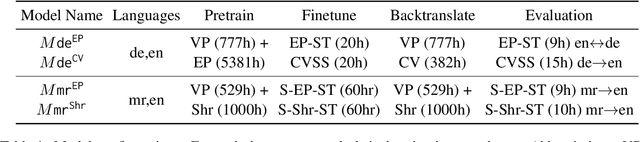
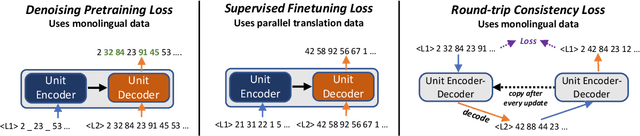
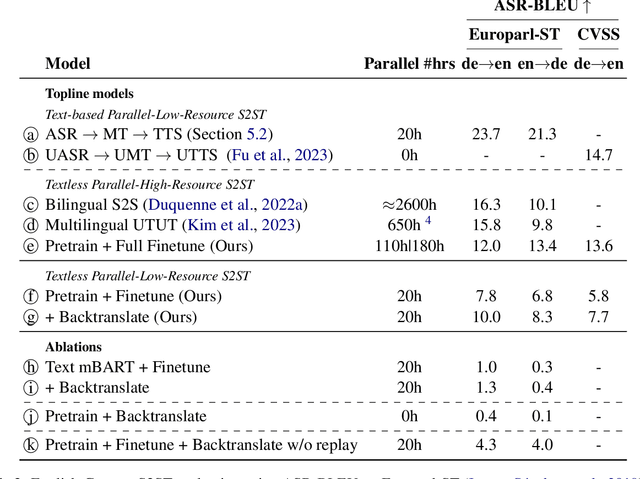
We propose an unsupervised speech-to-speech translation (S2ST) system that does not rely on parallel data between the source and target languages. Our approach maps source and target language speech signals into automatically discovered, discrete units and reformulates the problem as unsupervised unit-to-unit machine translation. We develop a three-step training procedure that involves (a) pre-training an unit-based encoder-decoder language model with a denoising objective (b) training it with word-by-word translated utterance pairs created by aligning monolingual text embedding spaces and (c) running unsupervised backtranslation bootstrapping off of the initial translation model. Our approach avoids mapping the speech signal into text and uses speech-to-unit and unit-to-speech models instead of automatic speech recognition and text to speech models. We evaluate our model on synthetic-speaker Europarl-ST English-German and German-English evaluation sets, finding that unit-based translation is feasible under this constrained scenario, achieving 9.29 ASR-BLEU in German to English and 8.07 in English to German.
Continual Learning for On-Device Speech Recognition using Disentangled Conformers
Dec 13, 2022
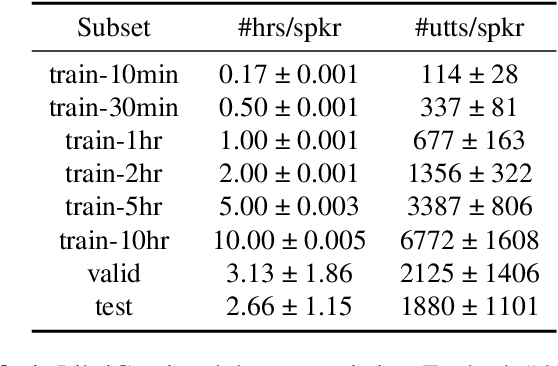
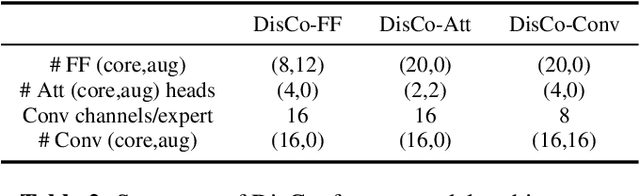
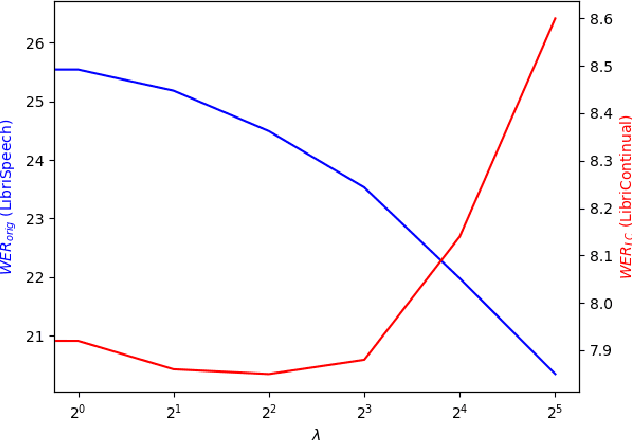
Automatic speech recognition research focuses on training and evaluating on static datasets. Yet, as speech models are increasingly deployed on personal devices, such models encounter user-specific distributional shifts. To simulate this real-world scenario, we introduce LibriContinual, a continual learning benchmark for speaker-specific domain adaptation derived from LibriVox audiobooks, with data corresponding to 118 individual speakers and 6 train splits per speaker of different sizes. Additionally, current speech recognition models and continual learning algorithms are not optimized to be compute-efficient. We adapt a general-purpose training algorithm NetAug for ASR and create a novel Conformer variant called the DisConformer (Disentangled Conformer). This algorithm produces ASR models consisting of a frozen 'core' network for general-purpose use and several tunable 'augment' networks for speaker-specific tuning. Using such models, we propose a novel compute-efficient continual learning algorithm called DisentangledCL. Our experiments show that the DisConformer models significantly outperform baselines on general ASR i.e. LibriSpeech (15.58% rel. WER on test-other). On speaker-specific LibriContinual they significantly outperform trainable-parameter-matched baselines (by 20.65% rel. WER on test) and even match fully finetuned baselines in some settings.
Why is Winoground Hard? Investigating Failures in Visuolinguistic Compositionality
Nov 11, 2022


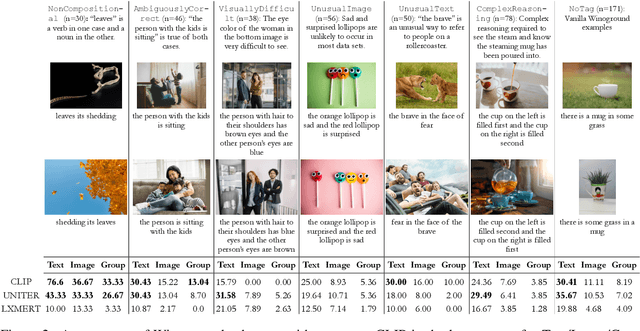
Recent visuolinguistic pre-trained models show promising progress on various end tasks such as image retrieval and video captioning. Yet, they fail miserably on the recently proposed Winoground dataset, which challenges models to match paired images and English captions, with items constructed to overlap lexically but differ in meaning (e.g., "there is a mug in some grass" vs. "there is some grass in a mug"). By annotating the dataset using new fine-grained tags, we show that solving the Winoground task requires not just compositional language understanding, but a host of other abilities like commonsense reasoning or locating small, out-of-focus objects in low-resolution images. In this paper, we identify the dataset's main challenges through a suite of experiments on related tasks (probing task, image retrieval task), data augmentation, and manual inspection of the dataset. Our analysis suggests that a main challenge in visuolinguistic models may lie in fusing visual and textual representations, rather than in compositional language understanding. We release our annotation and code at https://github.com/ajd12342/why-winoground-hard .