 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Deep Semantics for Test Completion
Mar 07, 2023
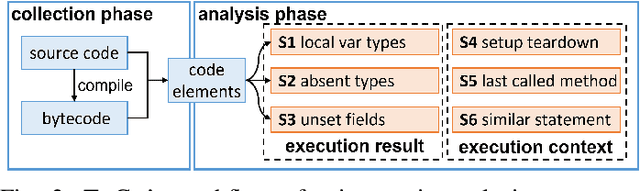
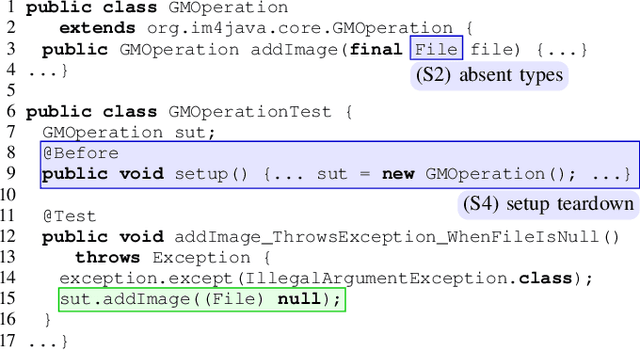
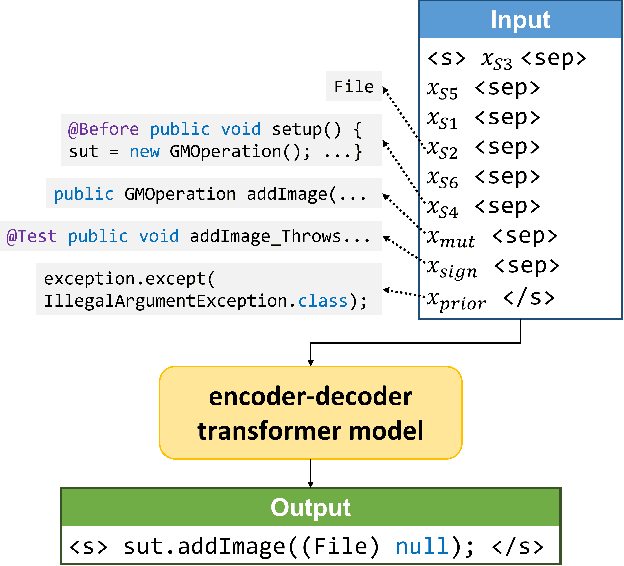
Writing tests is a time-consuming yet essential task during software development. We propose to leverage recent advances in deep learning for text and code generation to assist developers in writing tests. We formalize the novel task of test completion to automatically complete the next statement in a test method based on the context of prior statements and the code under test. We develop TeCo -- a deep learning model using code semantics for test completion. The key insight underlying TeCo is that predicting the next statement in a test method requires reasoning about code execution, which is hard to do with only syntax-level data that existing code completion models use. TeCo extracts and uses six kinds of code semantics data, including the execution result of prior statements and the execution context of the test method. To provide a testbed for this new task, as well as to evaluate TeCo, we collect a corpus of 130,934 test methods from 1,270 open-source Java projects. Our results show that TeCo achieves an exact-match accuracy of 18, which is 29% higher than the best baseline using syntax-level data only. When measuring functional correctness of generated next statement, TeCo can generate runnable code in 29% of the cases compared to 18% obtained by the best baseline. Moreover, TeCo is significantly better than prior work on test oracle generation.
Language-guided Task Adaptation for Imitation Learning
Jan 24, 2023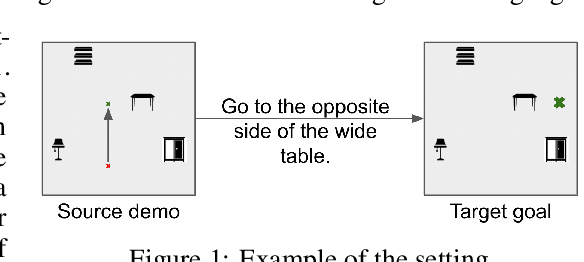



We introduce a novel setting, wherein an agent needs to learn a task from a demonstration of a related task with the difference between the tasks communicated in natural language. The proposed setting allows reusing demonstrations from other tasks, by providing low effort language descriptions, and can also be used to provide feedback to correct agent errors, which are both important desiderata for building intelligent agents that assist humans in daily tasks. To enable progress in this proposed setting, we create two benchmarks -- Room Rearrangement and Room Navigation -- that cover a diverse set of task adaptations. Further, we propose a framework that uses a transformer-based model to reason about the entities in the tasks and their relationships, to learn a policy for the target task
Using Developer Discussions to Guide Fixing Bugs in Software
Nov 11, 2022



Automatically fixing software bugs is a challenging task. While recent work showed that natural language context is useful in guiding bug-fixing models, the approach required prompting developers to provide this context, which was simulated through commit messages written after the bug-fixing code changes were made. We instead propose using bug report discussions, which are available before the task is performed and are also naturally occurring, avoiding the need for any additional information from developers. For this, we augment standard bug-fixing datasets with bug report discussions. Using these newly compiled datasets, we demonstrate that various forms of natural language context derived from such discussions can aid bug-fixing, even leading to improved performance over using commit messages corresponding to the oracle bug-fixing commits.
Zero-shot Video Moment Retrieval With Off-the-Shelf Models
Nov 03, 2022



For the majority of the machine learning community, the expensive nature of collecting high-quality human-annotated data and the inability to efficiently finetune very large state-of-the-art pretrained models on limited compute are major bottlenecks for building models for new tasks. We propose a zero-shot simple approach for one such task, Video Moment Retrieval (VMR), that does not perform any additional finetuning and simply repurposes off-the-shelf models trained on other tasks. Our three-step approach consists of moment proposal, moment-query matching and postprocessing, all using only off-the-shelf models. On the QVHighlights benchmark for VMR, we vastly improve performance of previous zero-shot approaches by at least 2.5x on all metrics and reduce the gap between zero-shot and state-of-the-art supervised by over 74%. Further, we also show that our zero-shot approach beats non-pretrained supervised models on the Recall metrics and comes very close on mAP metrics; and that it also performs better than the best pretrained supervised model on shorter moments. Finally, we ablate and analyze our results and propose interesting future directions.
Entity-Focused Dense Passage Retrieval for Outside-Knowledge Visual Question Answering
Oct 18, 2022
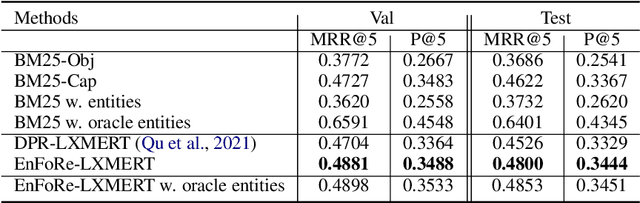
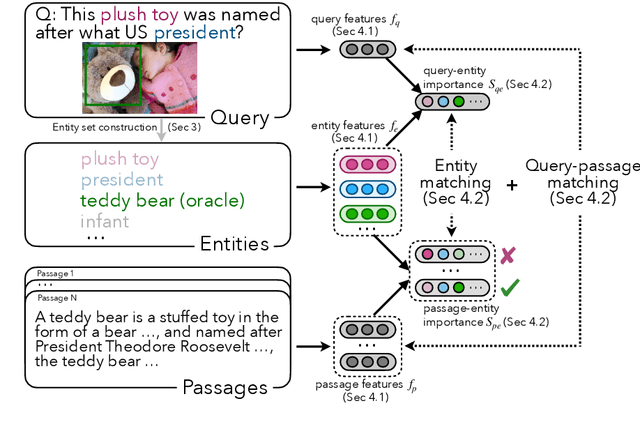

Most Outside-Knowledge Visual Question Answering (OK-VQA) systems employ a two-stage framework that first retrieves external knowledge given the visual question and then predicts the answer based on the retrieved content. However, the retrieved knowledge is often inadequate. Retrievals are frequently too general and fail to cover specific knowledge needed to answer the question. Also, the naturally available supervision (whether the passage contains the correct answer) is weak and does not guarantee question relevancy. To address these issues, we propose an Entity-Focused Retrieval (EnFoRe) model that provides stronger supervision during training and recognizes question-relevant entities to help retrieve more specific knowledge. Experiments show that our EnFoRe model achieves superior retrieval performance on OK-VQA, the currently largest outside-knowledge VQA dataset. We also combine the retrieved knowledge with state-of-the-art VQA models, and achieve a new state-of-the-art performance on OK-VQA.
Using Both Demonstrations and Language Instructions to Efficiently Learn Robotic Tasks
Oct 10, 2022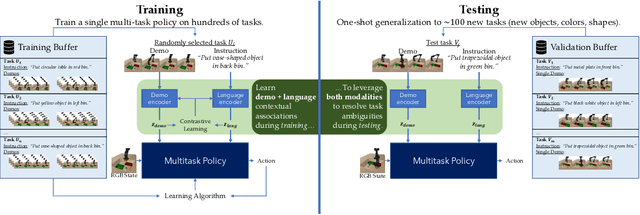
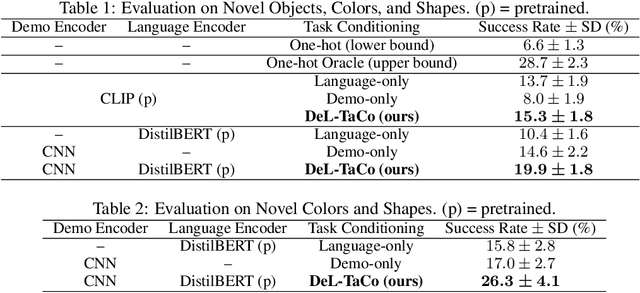
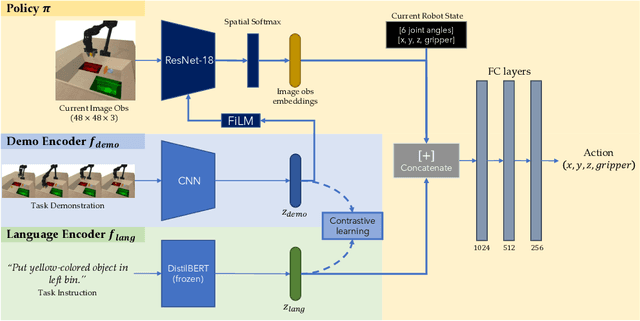
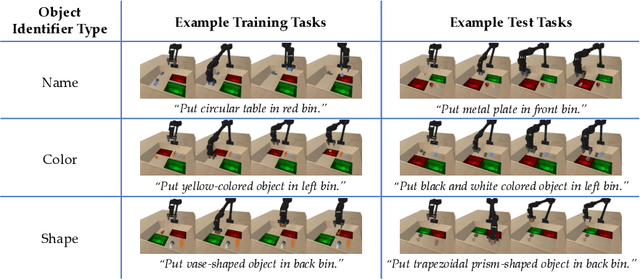
Demonstrations and natural language instructions are two common ways to specify and teach robots novel tasks. However, for many complex tasks, a demonstration or language instruction alone contains ambiguities, preventing tasks from being specified clearly. In such cases, a combination of both a demonstration and an instruction more concisely and effectively conveys the task to the robot than either modality alone. To instantiate this problem setting, we train a single multi-task policy on a few hundred challenging robotic pick-and-place tasks and propose DeL-TaCo (Joint Demo-Language Task Conditioning), a method for conditioning a robotic policy on task embeddings comprised of two components: a visual demonstration and a language instruction. By allowing these two modalities to mutually disambiguate and clarify each other during novel task specification, DeL-TaCo (1) substantially decreases the teacher effort needed to specify a new task and (2) achieves better generalization performance on novel objects and instructions over previous task-conditioning methods. To our knowledge, this is the first work to show that simultaneously conditioning a multi-task robotic manipulation policy on both demonstration and language embeddings improves sample efficiency and generalization over conditioning on either modality alone. See additional materials at https://sites.google.com/view/del-taco-learning
Towards Automated Error Analysis: Learning to Characterize Errors
Jan 14, 2022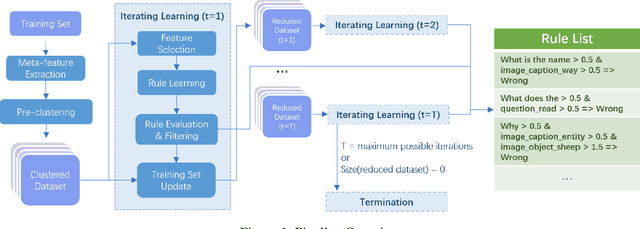

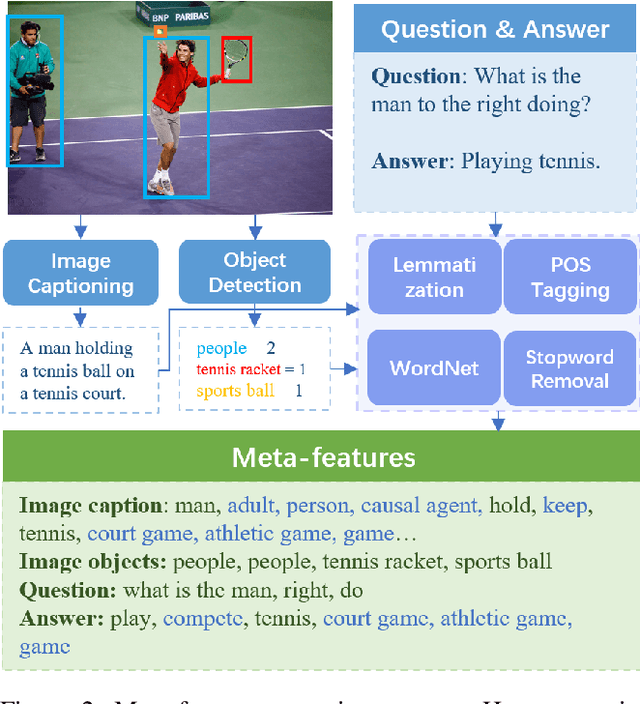

Characterizing the patterns of errors that a system makes helps researchers focus future development on increasing its accuracy and robustness. We propose a novel form of "meta learning" that automatically learns interpretable rules that characterize the types of errors that a system makes, and demonstrate these rules' ability to help understand and improve two NLP systems. Our approach works by collecting error cases on validation data, extracting meta-features describing these samples, and finally learning rules that characterize errors using these features. We apply our approach to VilBERT, for Visual Question Answering, and RoBERTa, for Common Sense Question Answering. Our system learns interpretable rules that provide insights into systemic errors these systems make on the given tasks. Using these insights, we are also able to "close the loop" and modestly improve performance of these systems.
Learning to Describe Solutions for Bug Reports Based on Developer Discussions
Oct 08, 2021
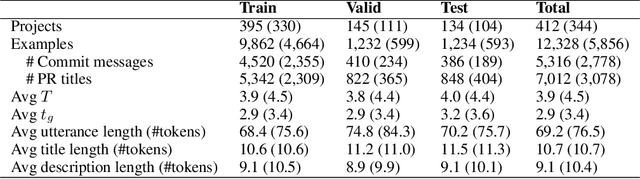

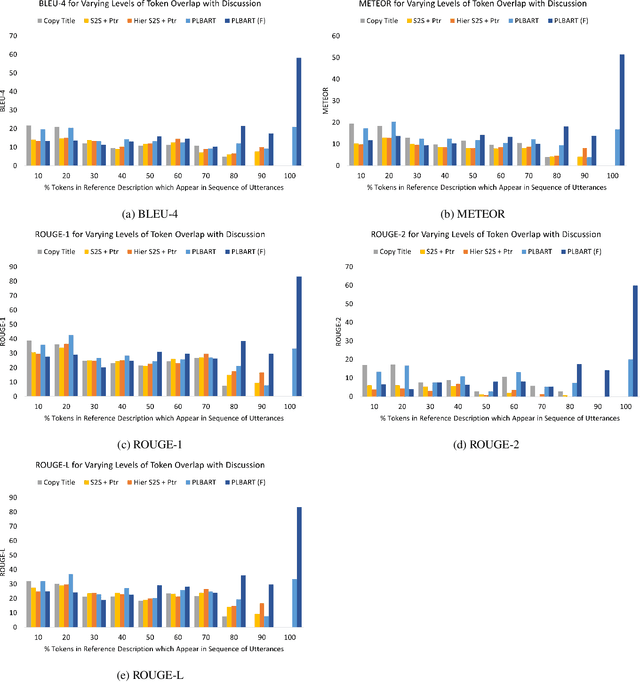
When a software bug is reported, developers engage in a discussion to collaboratively resolve it. While the solution is likely formulated within the discussion, it is often buried in a large amount of text, making it difficult to comprehend, which delays its implementation. To expedite bug resolution, we propose generating a concise natural language description of the solution by synthesizing relevant content within the discussion, which encompasses both natural language and source code. Furthermore, to support generating an informative description during an ongoing discussion, we propose a secondary task of determining when sufficient context about the solution emerges in real-time. We construct a dataset for these tasks with a novel technique for obtaining noisy supervision from repository changes linked to bug reports. We establish baselines for generating solution descriptions, and develop a classifier which makes a prediction following each new utterance on whether or not the necessary context for performing generation is available. Through automated and human evaluation, we find these tasks to form an ideal testbed for complex reasoning in long, bimodal dialogue context.
Evaluation Methodologies for Code Learning Tasks
Aug 22, 2021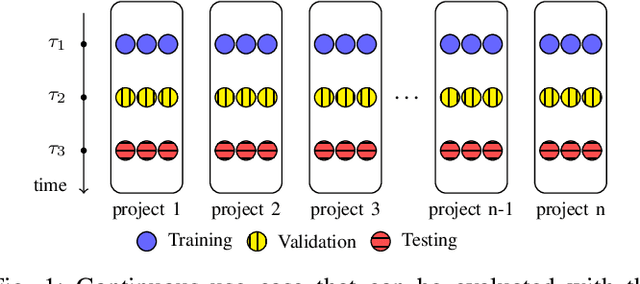
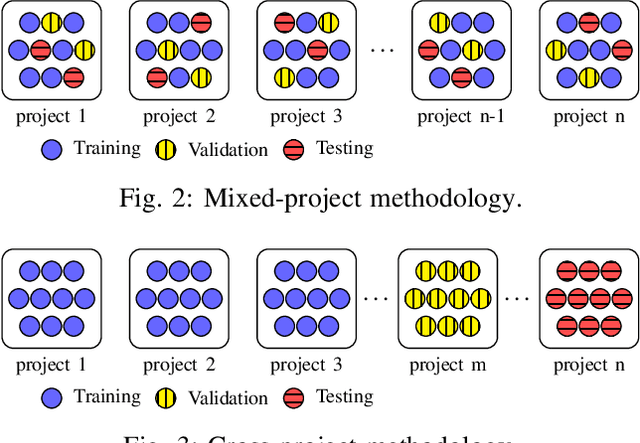
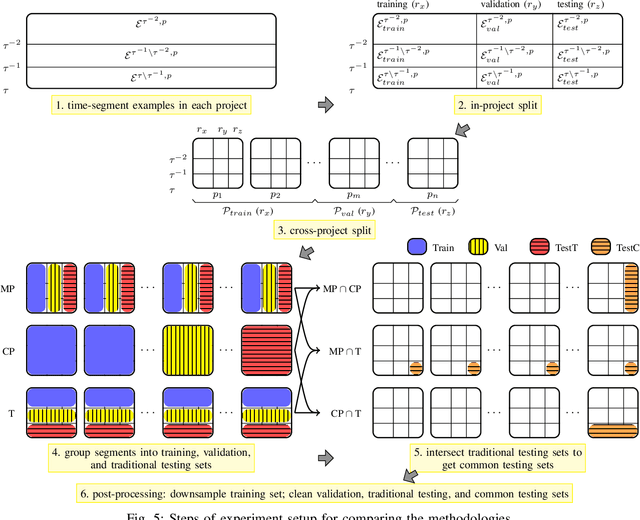
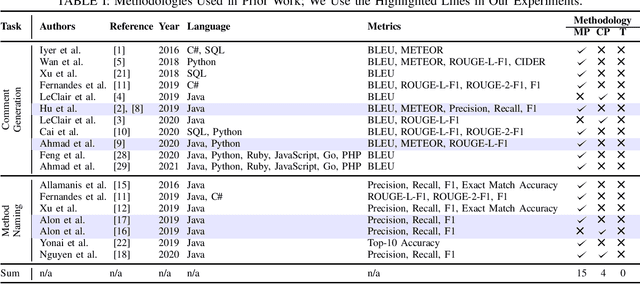
There has been a growing interest in developing machine learning (ML) models for code learning tasks, e.g., comment generation and method naming. Despite substantial increase in the effectiveness of ML models, the evaluation methodologies, i.e., the way people split datasets into training, validation, and testing sets, were not well designed. Specifically, no prior work on the aforementioned topics considered the timestamps of code and comments during evaluation (e.g., examples in the testing set might be from 2010 and examples from the training set might be from 2020). This may lead to evaluations that are inconsistent with the intended use cases of the ML models. In this paper, we formalize a novel time-segmented evaluation methodology, as well as the two methodologies commonly used in the literature: mixed-project and cross-project. We argue that time-segmented methodology is the most realistic. We also describe various use cases of ML models and provide a guideline for using methodologies to evaluate each use case. To assess the impact of methodologies, we collect a dataset of code-comment pairs with timestamps to train and evaluate several recent code learning ML models for the comment generation and method naming tasks. Our results show that different methodologies can lead to conflicting and inconsistent results. We invite the community to adopt the time-segmented evaluation methodology.
Zero-shot Task Adaptation using Natural Language
Jun 05, 2021
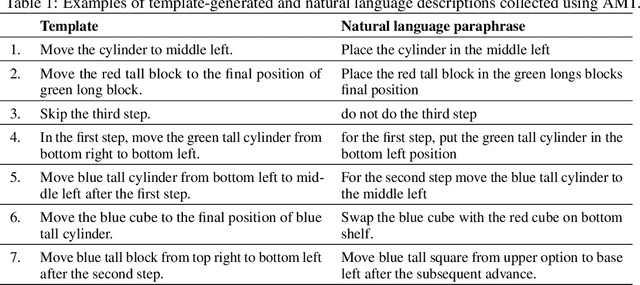
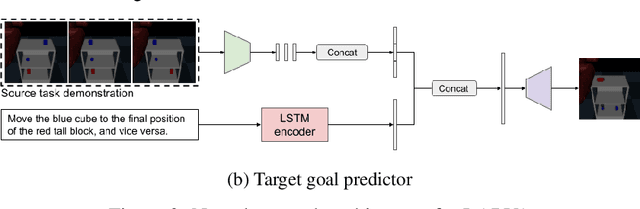
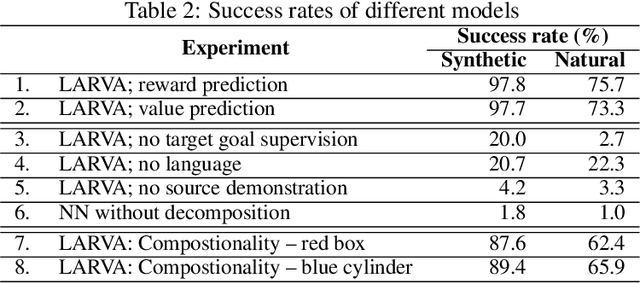
Imitation learning and instruction-following are two common approaches to communicate a user's intent to a learning agent. However, as the complexity of tasks grows, it could be beneficial to use both demonstrations and language to communicate with an agent. In this work, we propose a novel setting where an agent is given both a demonstration and a description, and must combine information from both the modalities. Specifically, given a demonstration for a task (the source task), and a natural language description of the differences between the demonstrated task and a related but different task (the target task), our goal is to train an agent to complete the target task in a zero-shot setting, that is, without any demonstrations for the target task. To this end, we introduce Language-Aided Reward and Value Adaptation (LARVA) which, given a source demonstration and a linguistic description of how the target task differs, learns to output a reward / value function that accurately describes the target task. Our experiments show that on a diverse set of adaptations, our approach is able to complete more than 95% of target tasks when using template-based descriptions, and more than 70% when using free-form natural language.