 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tool for Generating Exceptional Behavior Tests With Large Language Models
May 28, 2025Exceptional behavior tests (EBTs) are crucial in software development for verifying that code correctly handles unwanted events and throws appropriate exceptions. However, prior research has shown that developers often prioritize testing "happy paths", e.g., paths without unwanted events over exceptional scenarios. We present exLong, a framework that automatically generates EBTs to address this gap. exLong leverages a large language model (LLM) fine-tuned from CodeLlama and incorporates reasoning about exception-throwing traces, conditional expressions that guard throw statements, and non-exceptional behavior tests that execute similar traces. Our demonstration video illustrates how exLong can effectively assist developers in creating comprehensive EBTs for their project (available at https://youtu.be/Jro8kMgplZk).
Multilingual Code Co-Evolution Using Large Language Models
Jul 27, 2023Many software projects implement APIs and algorithms in multiple programming languages. Maintaining such projects is tiresome, as developers have to ensure that any change (e.g., a bug fix or a new feature) is being propagated, timely and without errors, to implementations in other programming languages. In the world of ever-changing software, using rule-based translation tools (i.e., transpilers) or machine learning models for translating code from one language to another provides limited value. Translating each time the entire codebase from one language to another is not the way developers work. In this paper, we target a novel task: translating code changes from one programming language to another using large language models (LLMs). We design and implement the first LLM, dubbed Codeditor, to tackle this task. Codeditor explicitly models code changes as edit sequences and learns to correlate changes across programming languages. To evaluate Codeditor, we collect a corpus of 6,613 aligned code changes from 8 pairs of open-source software projects implementing similar functionalities in two programming languages (Java and C#). Results show that Codeditor outperforms the state-of-the-art approaches by a large margin on all commonly used automatic metrics. Our work also reveals that Codeditor is complementary to the existing generation-based models, and their combination ensures even greater performance.
Learning Deep Semantics for Test Completion
Mar 07, 2023
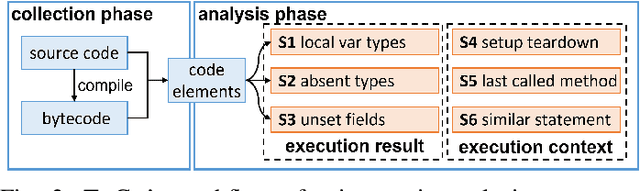
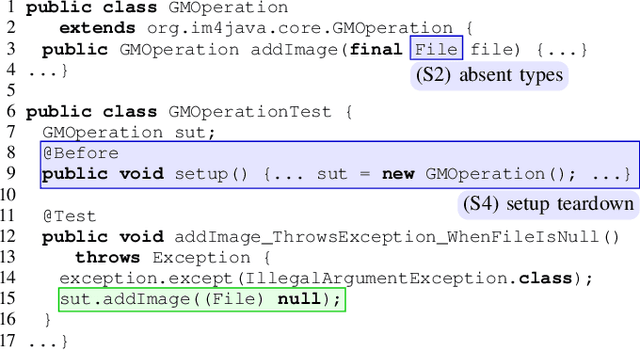
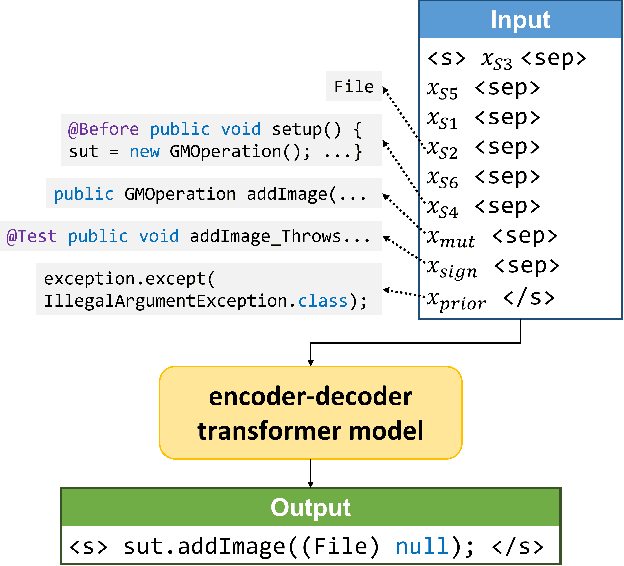
Writing tests is a time-consuming yet essential task during software development. We propose to leverage recent advances in deep learning for text and code generation to assist developers in writing tests. We formalize the novel task of test completion to automatically complete the next statement in a test method based on the context of prior statements and the code under test. We develop TeCo -- a deep learning model using code semantics for test completion. The key insight underlying TeCo is that predicting the next statement in a test method requires reasoning about code execution, which is hard to do with only syntax-level data that existing code completion models use. TeCo extracts and uses six kinds of code semantics data, including the execution result of prior statements and the execution context of the test method. To provide a testbed for this new task, as well as to evaluate TeCo, we collect a corpus of 130,934 test methods from 1,270 open-source Java projects. Our results show that TeCo achieves an exact-match accuracy of 18, which is 29% higher than the best baseline using syntax-level data only. When measuring functional correctness of generated next statement, TeCo can generate runnable code in 29% of the cases compared to 18% obtained by the best baseline. Moreover, TeCo is significantly better than prior work on test oracle generation.
Using Developer Discussions to Guide Fixing Bugs in Software
Nov 11, 2022



Automatically fixing software bugs is a challenging task. While recent work showed that natural language context is useful in guiding bug-fixing models, the approach required prompting developers to provide this context, which was simulated through commit messages written after the bug-fixing code changes were made. We instead propose using bug report discussions, which are available before the task is performed and are also naturally occurring, avoiding the need for any additional information from developers. For this, we augment standard bug-fixing datasets with bug report discussions. Using these newly compiled datasets, we demonstrate that various forms of natural language context derived from such discussions can aid bug-fixing, even leading to improved performance over using commit messages corresponding to the oracle bug-fixing commits.
CoditT5: Pretraining for Source Code and Natural Language Editing
Aug 10, 2022

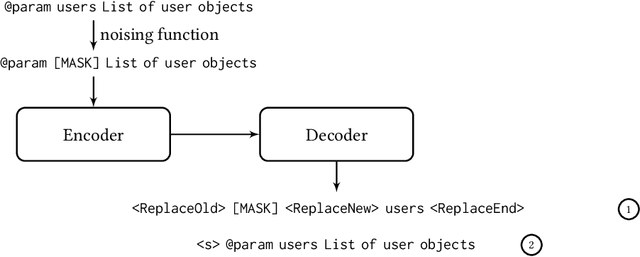
Pretrained language models have been shown to be effective in many software-related generation tasks; however, they are not well-suited for editing tasks as they are not designed to reason about edits. To address this, we propose a novel pretraining objective which explicitly models edits and use it to build CoditT5, a large language model for software-related editing tasks that is pretrained on large amounts of source code and natural language comments. We fine-tune it on various downstream editing tasks, including comment updating, bug fixing, and automated code review. By outperforming pure generation-based models, we demonstrate the generalizability of our approach and its suitability for editing tasks. We also show how a pure generation model and our edit-based model can complement one another through simple reranking strategies, with which we achieve state-of-the-art performance for the three downstream editing tasks.
Learning to Describe Solutions for Bug Reports Based on Developer Discussions
Oct 08, 2021
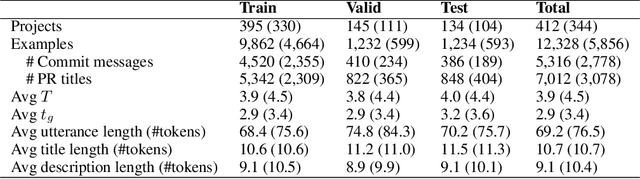

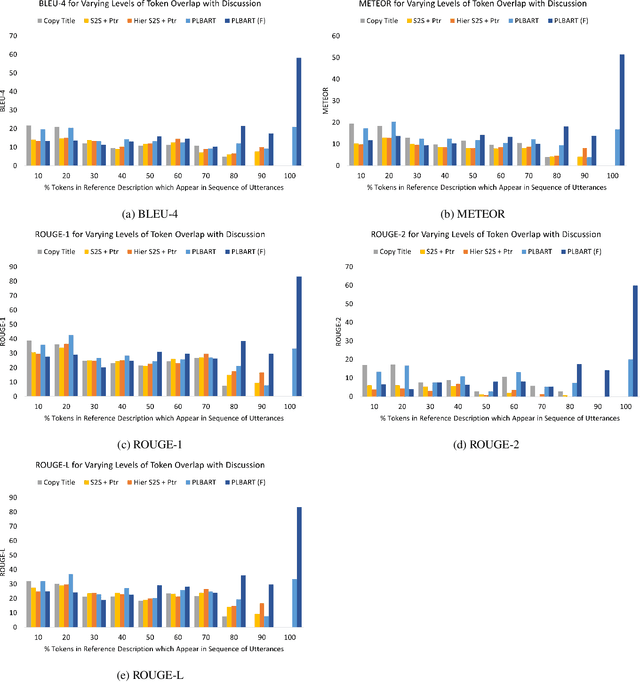
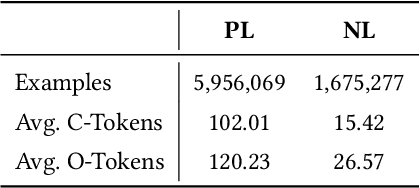
When a software bug is reported, developers engage in a discussion to collaboratively resolve it. While the solution is likely formulated within the discussion, it is often buried in a large amount of text, making it difficult to comprehend, which delays its implementation. To expedite bug resolution, we propose generating a concise natural language description of the solution by synthesizing relevant content within the discussion, which encompasses both natural language and source code. Furthermore, to support generating an informative description during an ongoing discussion, we propose a secondary task of determining when sufficient context about the solution emerges in real-time. We construct a dataset for these tasks with a novel technique for obtaining noisy supervision from repository changes linked to bug reports. We establish baselines for generating solution descriptions, and develop a classifier which makes a prediction following each new utterance on whether or not the necessary context for performing generation is available. Through automated and human evaluation, we find these tasks to form an ideal testbed for complex reasoning in long, bimodal dialogue context.
Evaluation Methodologies for Code Learning Tasks
Aug 22, 2021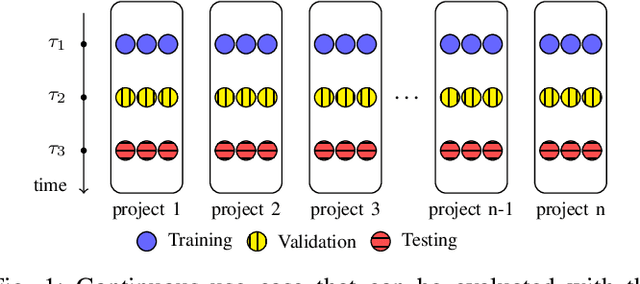
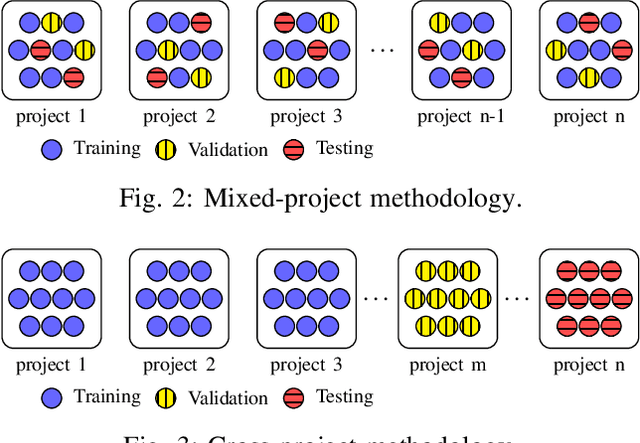
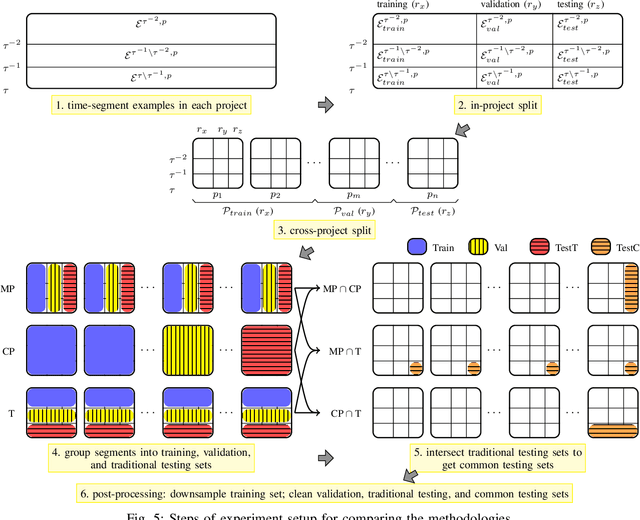
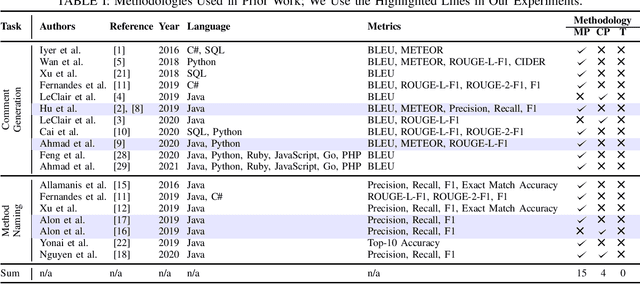
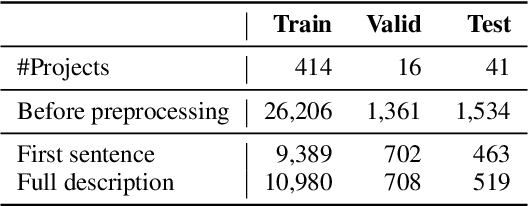
There has been a growing interest in developing machine learning (ML) models for code learning tasks, e.g., comment generation and method naming. Despite substantial increase in the effectiveness of ML models, the evaluation methodologies, i.e., the way people split datasets into training, validation, and testing sets, were not well designed. Specifically, no prior work on the aforementioned topics considered the timestamps of code and comments during evaluation (e.g., examples in the testing set might be from 2010 and examples from the training set might be from 2020). This may lead to evaluations that are inconsistent with the intended use cases of the ML models. In this paper, we formalize a novel time-segmented evaluation methodology, as well as the two methodologies commonly used in the literature: mixed-project and cross-project. We argue that time-segmented methodology is the most realistic. We also describe various use cases of ML models and provide a guideline for using methodologies to evaluate each use case. To assess the impact of methodologies, we collect a dataset of code-comment pairs with timestamps to train and evaluate several recent code learning ML models for the comment generation and method naming tasks. Our results show that different methodologies can lead to conflicting and inconsistent results. We invite the community to adopt the time-segmented evaluation methodology.
Learning to Generate Code Comments from Class Hierarchies
Apr 17, 2021


Descriptive code comments are essential for supporting code comprehension and maintenance. We propose the task of automatically generating comments for overriding methods. We formulate a novel framework which accommodates the unique contextual and linguistic reasoning that is required for performing this task. Our approach features: (1) incorporating context from the class hierarchy; (2) conditioning on learned, latent representations of specificity to generate comments that capture the more specialized behavior of the overriding method; and (3) unlikelihood training to discourage predictions which do not conform to invariant characteristics of the comment corresponding to the overridden method. Our experiments show that the proposed approach is able to generate comments for overriding methods of higher quality compared to prevailing comment generation techniques.
Roosterize: Suggesting Lemma Names for Coq Verification Projects Using Deep Learning
Mar 01, 2021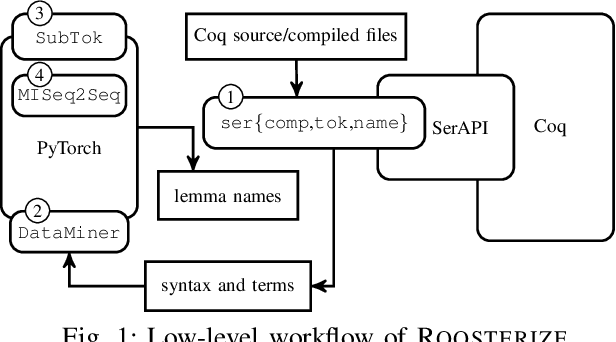
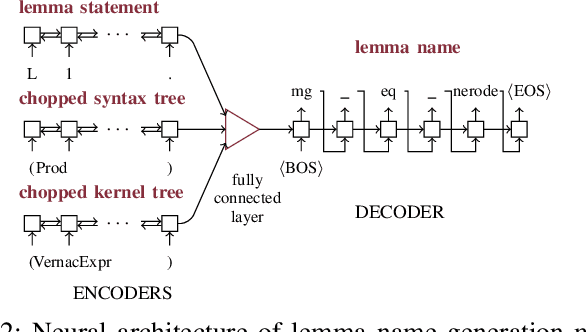
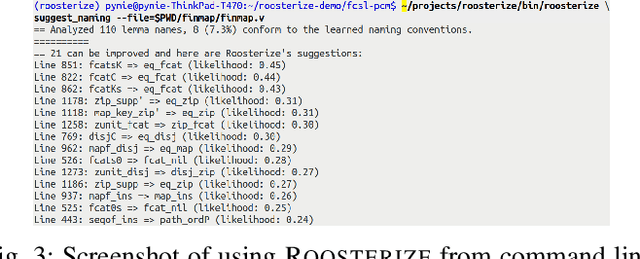
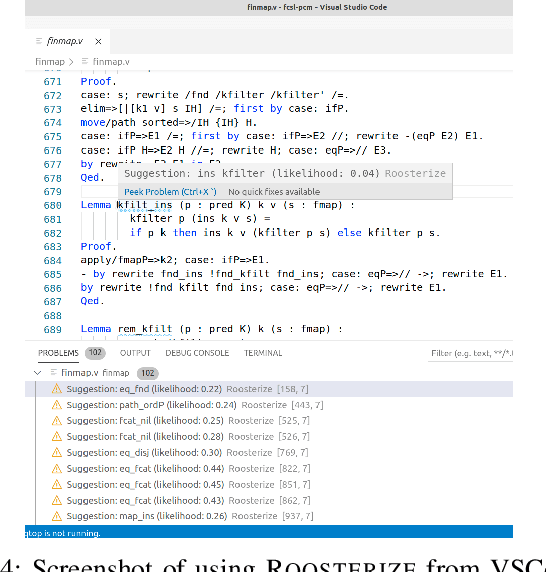
Naming conventions are an important concern in large verification projects using proof assistants, such as Coq. In particular, lemma names are used by proof engineers to effectively understand and modify Coq code. However, providing accurate and informative lemma names is a complex task, which is currently often carried out manually. Even when lemma naming is automated using rule-based tools, generated names may fail to adhere to important conventions not specified explicitly. We demonstrate a toolchain, dubbed Roosterize, which automatically suggests lemma names in Coq projects. Roosterize leverages a neural network model trained on existing Coq code, thus avoiding manual specification of naming conventions. To allow proof engineers to conveniently access suggestions from Roosterize during Coq project development, we integrated the toolchain into the popular Visual Studio Code editor. Our evaluation shows that Roosterize substantially outperforms strong baselines for suggesting lemma names and is useful in practice. The demo video for Roosterize can be viewed at: https://youtu.be/HZ5ac7Q14rc.
Deep Just-In-Time Inconsistency Detection Between Comments and Source Code
Oct 04, 2020
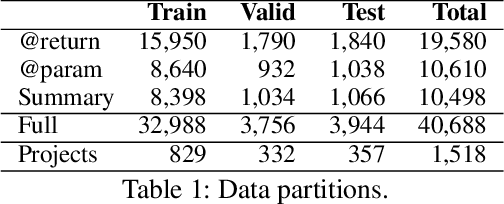
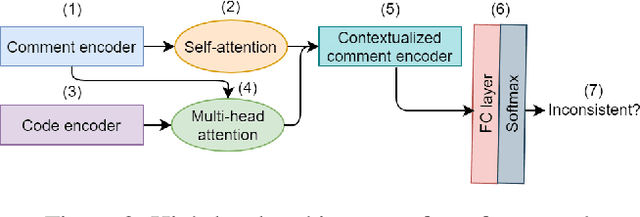
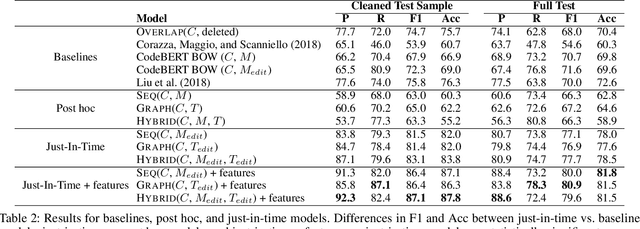
Natural language comments convey key aspects of source code such as implementation, usage, and pre- and post-conditions. Failure to update comments accordingly when the corresponding code is modified introduces inconsistencies, which is known to lead to confusion and software bugs. In this paper, we aim to detect whether a comment becomes inconsistent as a result of changes to the corresponding body of code, in order to catch potential inconsistencies just-in-time, i.e., before they are committed to a version control system. To achieve this, we develop a deep-learning approach that learns to correlate a comment with code changes. By evaluating on a large corpus of comment/code pairs spanning various comment types, we show that our model outperforms multiple baselines by significant margins. For extrinsic evaluation, we show the usefulness of our approach by combining it with a comment update model to build a more comprehensive automatic comment maintenance system which can both detect and resolve inconsistent comments based on code changes.