 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoosterize: Suggesting Lemma Names for Coq Verification Projects Using Deep Learning
Mar 01, 2021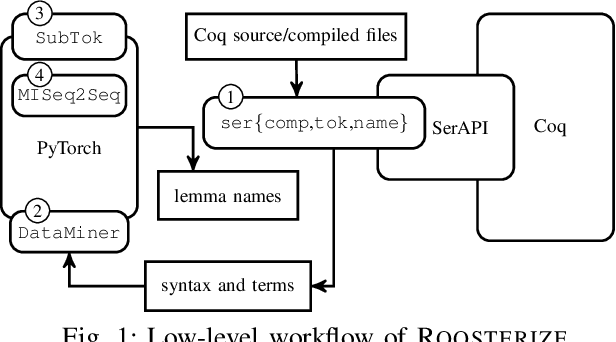
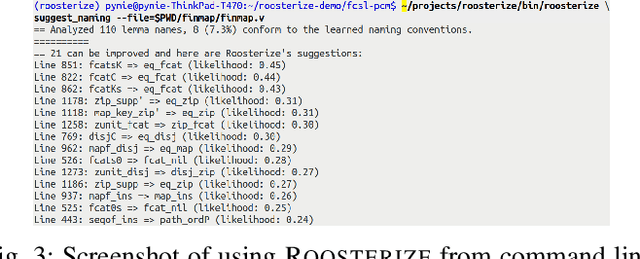
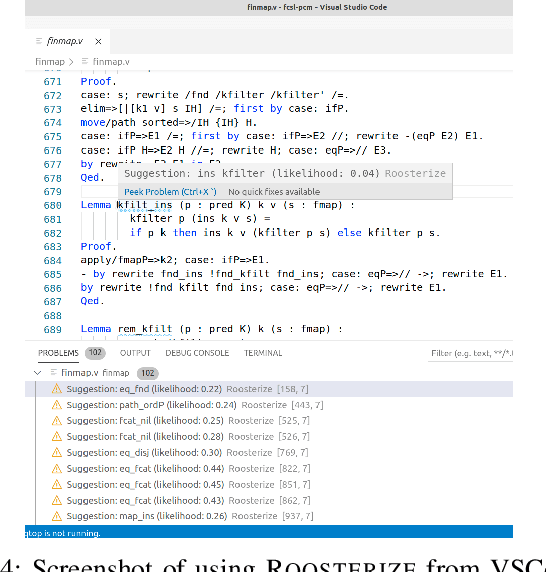
Naming conventions are an important concern in large verification projects using proof assistants, such as Coq. In particular, lemma names are used by proof engineers to effectively understand and modify Coq code. However, providing accurate and informative lemma names is a complex task, which is currently often carried out manually. Even when lemma naming is automated using rule-based tools, generated names may fail to adhere to important conventions not specified explicitly. We demonstrate a toolchain, dubbed Roosterize, which automatically suggests lemma names in Coq projects. Roosterize leverages a neural network model trained on existing Coq code, thus avoiding manual specification of naming conventions. To allow proof engineers to conveniently access suggestions from Roosterize during Coq project development, we integrated the toolchain into the popular Visual Studio Code editor. Our evaluation shows that Roosterize substantially outperforms strong baselines for suggesting lemma names and is useful in practice. The demo video for Roosterize can be viewed at: https://youtu.be/HZ5ac7Q14rc.
Learning to Format Coq Code Using Language Models
Jun 18, 2020
Should the final right bracket in a record declaration be on a separate line? Should arguments to the rewrite tactic be separated by a single space? Coq code tends to be written in distinct manners by different people and teams. The expressiveness, flexibility, and extensibility of Coq's languages and notations means that Coq projects have a wide variety of recognizable coding styles, sometimes explicitly documented as conventions on naming and formatting. In particular, even inexperienced users can distinguish vernacular using the standard library and plain Ltac from idiomatic vernacular using the Mathematical Components (MathComp) library and SSReflect. While coding conventions are important for comprehension and maintenance, they are costly to document and enforce. Rule-based formatters, such as Coq's beautifier, have limited flexibility and only capture small fractions of desired conventions in large verification projects. We believe that application of language models - a class of Natural Language Processing (NLP) techniques for capturing regularities in corpora - can provide a solution to this conundrum. More specifically, we believe that an approach based on automatically learning conventions from existing Coq code, and then suggesting idiomatic code to users in the proper context, can be superior to manual approaches and static analysis tools - both in terms of effort and results. As a first step, we here outline initial models to learn and suggest space formatting in Coq files, with a preliminary implementation for Coq 8.10, and evaluated on a corpus based on MathComp 1.9.0 which comprises 164k lines of Coq code from four core projects.
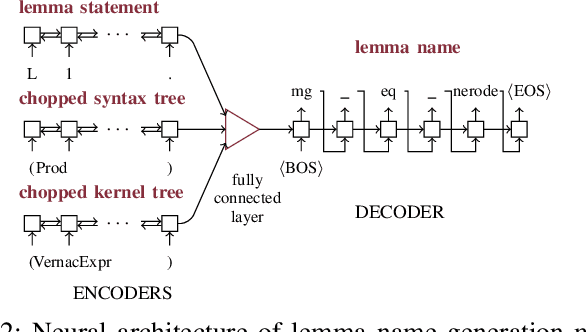
Deep Generation of Coq Lemma Names Using Elaborated Terms
Apr 22, 2020
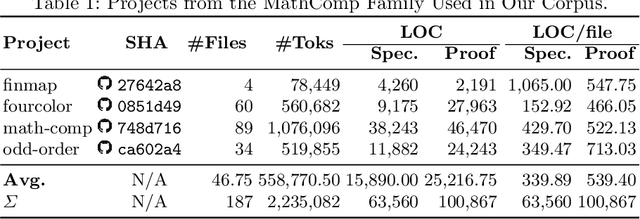

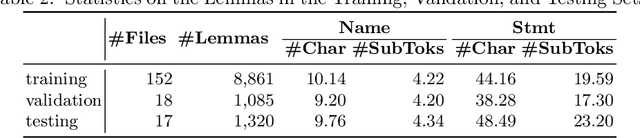
Coding conventions for naming, spacing, and other essentially stylistic properties are necessary for developers to effectively understand, review, and modify source code in large software projects. Consistent conventions in verification projects based on proof assistants, such as Coq, increase in importance as projects grow in size and scope. While conventions can be documented and enforced manually at high cost, emerging approaches automatically learn and suggest idiomatic names in Java-like languages by applying statistical language models on large code corpora. However, due to its powerful language extension facilities and fusion of type checking and computation, Coq is a challenging target for automated learning techniques. We present novel generation models for learning and suggesting lemma names for Coq projects. Our models, based on multi-input neural networks, are the first to leverage syntactic and semantic information from Coq's lexer (tokens in lemma statements), parser (syntax trees), and kernel (elaborated terms) for naming; the key insight is that learning from elaborated terms can substantially boost model performance. We implemented our models in a toolchain, dubbed Roosterize, and applied it on a large corpus of code derived from the Mathematical Components family of projects, known for its stringent coding conventions. Our results show that Roosterize substantially outperforms baselines for suggesting lemma names, highlighting the importance of using multi-input models and elaborated terms.