 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgram-as-Weights: A Programming Paradigm for Fuzzy Functions
Jul 02, 2026Many everyday programming tasks resist clean rule-based implementation, such as alerting on important log lines, repairing malformed JSON, or ranking search results by intent, and are increasingly outsourced to large language model APIs at the cost of locality, reproducibility, and price. We propose fuzzy-function programming: compiling such a function from a natural-language specification into a compact, locally-executable neural artifact. We instantiate this paradigm with Program-as-Weights (PAW), in which a 4B compiler trained on FuzzyBench, a 10M-example dataset we release, emits parameter-efficient adapters for a frozen, lightweight interpreter. A 0.6B Qwen3 interpreter executing PAW programs matches the performance of direct prompting of Qwen3-32B, while using roughly one fiftieth of the inference memory and running at 30 tokens/s on a MacBook M3. PAW reframes the foundation model from a per-input problem solver into a tool builder: invoked once per function definition, it produces a small reusable artifact whose subsequent calls per function application are cheap and offline.
TestEvo-Bench: An Executable and Live Benchmark for Test and Code Co-Evolution
Jul 02, 2026Software tests and code evolve together: a code change should be followed by new or updated tests that record the new software behavior. Yet existing test generation and update benchmarks often isolate the test from the code change, and rely on static metadata that does not verify whether a test is executable or semantically tied to the code change. This makes it difficult to evaluate whether a test automation agent understands how a code change should propagate into the test suite. We introduce TestEvo-Bench, a benchmark of test and code co-evolution tasks mined from software repositories, with two tracks: in test generation, the agent shall write new tests to capture the new software behavior; in test update, the agent shall adapt failing existing tests to the changed software behavior. Each task is anchored to a real commit history and packaged with environment configuration to support execution-grounded metrics such as pass rate, coverage, and mutation score. TestEvo-Bench is also a live benchmark: each task records the timestamp of the test and code changes, and new tasks are periodically mined by our automated pipeline, so evaluation can be restricted to tasks postdating a model's training cutoff to reduce data leakage risk. The current snapshot contains 746 test generation and 509 test update tasks, curated from 59,950 candidate co-evolution records across 152 open-source Java projects. We experiment with four state-of-the-art agents that combine strong harnesses (Claude Code, Gemini CLI, and SWE-Agent) with strong foundation models (Claude Opus 4.7 and Gemini 3.1 Pro). Results show that they achieve up to 77.5% success rate on test generation and 74.6% on test update. However, success rate is materially lower on the most recent benchmark tasks and drops significantly under limited per-task cost.
Code2LoRA: Hypernetwork-Generated Adapters for Code Language Models under Software Evolution
Jun 04, 2026Code language models need repository-level context to resolve imports, APIs, and project conventions. Existing methods inject this knowledge as long inputs (retrieved through RAG or dependency analysis) or through per-repository fine-tuning and LoRA -- costly at repository scale and brittle to evolving codebases. We introduce Code2LoRA, a hypernetwork framework that generates repository-specific LoRA adapters, effectively injecting repository knowledge with zero inference-time token overhead. Code2LoRA supports two usage scenarios: Code2LoRA-Static converts a single repository snapshot into an adapter, suitable for comprehension of stable codebases; while Code2LoRA-Evo maintains an adapter backed by a GRU hidden state updated per code diff, suitable for active development of evolving codebases. To evaluate Code2LoRA against parameter-efficient fine-tuning baselines, we build RepoPeftBench, a benchmark of 604 Python repositories with two tracks: a static track with 40K training and 12K test assertion-completion tasks, and an evolution track with 215K commit-derived training and 87K commit-derived test tasks. On the static track, Code2LoRA-Static achieves 63.8% cross-repo and 66.2% in-repo exact match, matching the per-repository LoRA upper bound; on the evolution track, Code2LoRA-Evo achieves 60.3% cross-repo exact match (+5.2 pp over a single shared LoRA). Code2LoRA's code can be found at https://anonymous.4open.science/r/code2lora-6857; the model checkpoints and RepoPeftBench datasets can be found at https://huggingface.co/code2lora.
Automated Modernization of Machine Learning Engineering Notebooks for Reproducibility
Feb 06, 2026Interactive computational notebooks (e.g., Jupyter notebooks) are widely used in machine learning engineering (MLE) to program and share end-to-end pipelines, from data preparation to model training and evaluation. However, environment erosion-the rapid evolution of hardware and software ecosystems for machine learning-has rendered many published MLE notebooks non-reproducible in contemporary environments, hindering code reuse and scientific progress. To quantify this gap, we study 12,720 notebooks mined from 79 popular Kaggle competitions: only 35.4% remain reproducible today. Crucially, we find that environment backporting, i.e., downgrading dependencies to match the submission time, does not improve reproducibility but rather introduces additional failure modes. To address environment erosion, we design and implement MLEModernizer, an LLM-driven agentic framework that treats the contemporary environment as a fixed constraint and modernizes notebook code to restore reproducibility. MLEModernizer iteratively executes notebooks, collects execution feedback, and applies targeted fixes in three types: error-repair, runtime-reduction, and score-calibration. Evaluated on 7,402 notebooks that are non-reproducible under the baseline environment, MLEModernizer makes 5,492 (74.2%) reproducible. MLEModernizer enables practitioners to validate, reuse, and maintain MLE artifacts as the hardware and software ecosystems continue to evolve.
TokDrift: When LLM Speaks in Subwords but Code Speaks in Grammar
Oct 16, 2025Large language models (LLMs) for code rely on subword tokenizers, such as byte-pair encoding (BPE), learned from mixed natural language text and programming language code but driven by statistics rather than grammar. As a result, semantically identical code snippets can be tokenized differently depending on superficial factors such as whitespace or identifier naming. To measure the impact of this misalignment, we introduce TokDrift, a framework that applies semantic-preserving rewrite rules to create code variants differing only in tokenization. Across nine code LLMs, including large ones with over 30B parameters, even minor formatting changes can cause substantial shifts in model behavior. Layer-wise analysis shows that the issue originates in early embeddings, where subword segmentation fails to capture grammar token boundaries. Our findings identify misaligned tokenization as a hidden obstacle to reliable code understanding and generation, highlighting the need for grammar-aware tokenization for future code LLMs.
A Tool for Generating Exceptional Behavior Tests With Large Language Models
May 28, 2025Exceptional behavior tests (EBTs) are crucial in software development for verifying that code correctly handles unwanted events and throws appropriate exceptions. However, prior research has shown that developers often prioritize testing "happy paths", e.g., paths without unwanted events over exceptional scenarios. We present exLong, a framework that automatically generates EBTs to address this gap. exLong leverages a large language model (LLM) fine-tuned from CodeLlama and incorporates reasoning about exception-throwing traces, conditional expressions that guard throw statements, and non-exceptional behavior tests that execute similar traces. Our demonstration video illustrates how exLong can effectively assist developers in creating comprehensive EBTs for their project (available at https://youtu.be/Jro8kMgplZk).
Suggesting Code Edits in Interactive Machine Learning Notebooks Using Large Language Models
Jan 16, 2025Machine learning developers frequently use interactive computational notebooks, such as Jupyter notebooks, to host code for data processing and model training. Jupyter notebooks provide a convenient tool for writing machine learning pipelines and interactively observing outputs, however, maintaining Jupyter notebooks, e.g., to add new features or fix bugs, can be challenging due to the length and complexity of the notebooks. Moreover, there is no existing benchmark related to developer edits on Jupyter notebooks. To address this, we present the first dataset of 48,398 Jupyter notebook edits derived from 20,095 revisions of 792 machine learning repositories on GitHub, and perform the first study of the using LLMs to predict code edits in Jupyter notebooks. Our dataset captures granular details of cell-level and line-level modifications, offering a foundation for understanding real-world maintenance patterns in machine learning workflows. We observed that the edits on Jupyter notebooks are highly localized, with changes averaging only 166 lines of code in repositories. While larger models outperform smaller counterparts in code editing, all models have low accuracy on our dataset even after finetuning, demonstrating the complexity of real-world machine learning maintenance tasks. Our findings emphasize the critical role of contextual information in improving model performance and point toward promising avenues for advancing large language models' capabilities in engineering machine learning code.
InterTrans: Leveraging Transitive Intermediate Translations to Enhance LLM-based Code Translation
Nov 05, 2024



Code translation aims to convert a program from one programming language (PL) to another. This long-standing software engineering task is crucial for modernizing legacy systems, ensuring cross-platform compatibility, enhancing performance, and more. However, automating this process remains challenging due to many syntactic and semantic differences between PLs. Recent studies show that even advanced techniques such as large language models (LLMs), especially open-source LLMs, still struggle with the task. Currently, code LLMs are trained with source code from multiple programming languages, thus presenting multilingual capabilities. In this paper, we investigate whether such multilingual capabilities can be harnessed to enhance code translation. To achieve this goal, we introduce InterTrans, an LLM-based automated code translation approach that, in contrast to existing approaches, leverages intermediate translations across PLs to bridge the syntactic and semantic gaps between source and target PLs. InterTrans contains two stages. It first utilizes a novel Tree of Code Translation (ToCT) algorithm to plan transitive intermediate translation sequences between a given source and target PL, then validates them in a specific order. We evaluate InterTrans with three open LLMs on three benchmarks (i.e., CodeNet, HumanEval-X, and TransCoder) involving six PLs. Results show an absolute improvement between 18.3% to 43.3% in Computation Accuracy (CA) for InterTrans over Direct Translation with 10 attempts. The best-performing variant of InterTrans (with Magicoder LLM) achieved an average CA of 87.3%-95.4% on three benchmarks.
Multilingual Code Co-Evolution Using Large Language Models
Jul 27, 2023Many software projects implement APIs and algorithms in multiple programming languages. Maintaining such projects is tiresome, as developers have to ensure that any change (e.g., a bug fix or a new feature) is being propagated, timely and without errors, to implementations in other programming languages. In the world of ever-changing software, using rule-based translation tools (i.e., transpilers) or machine learning models for translating code from one language to another provides limited value. Translating each time the entire codebase from one language to another is not the way developers work. In this paper, we target a novel task: translating code changes from one programming language to another using large language models (LLMs). We design and implement the first LLM, dubbed Codeditor, to tackle this task. Codeditor explicitly models code changes as edit sequences and learns to correlate changes across programming languages. To evaluate Codeditor, we collect a corpus of 6,613 aligned code changes from 8 pairs of open-source software projects implementing similar functionalities in two programming languages (Java and C#). Results show that Codeditor outperforms the state-of-the-art approaches by a large margin on all commonly used automatic metrics. Our work also reveals that Codeditor is complementary to the existing generation-based models, and their combination ensures even greater performance.
Learning Deep Semantics for Test Completion
Mar 07, 2023
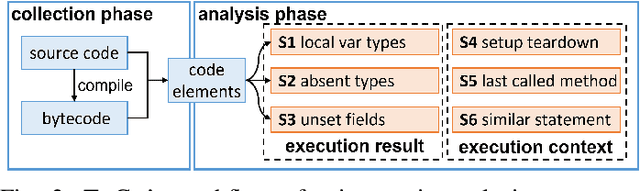
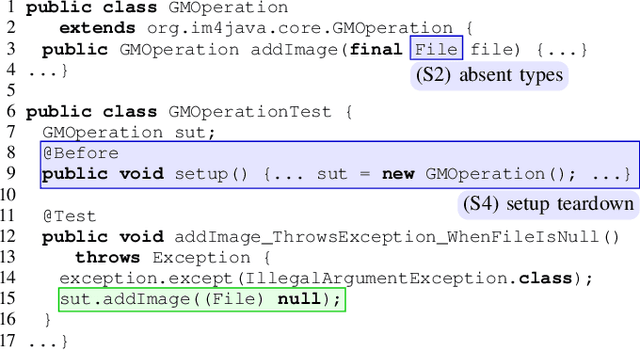
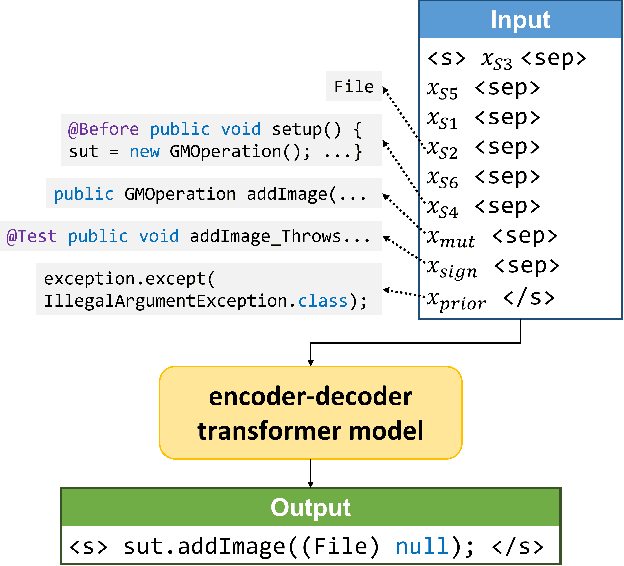
Writing tests is a time-consuming yet essential task during software development. We propose to leverage recent advances in deep learning for text and code generation to assist developers in writing tests. We formalize the novel task of test completion to automatically complete the next statement in a test method based on the context of prior statements and the code under test. We develop TeCo -- a deep learning model using code semantics for test completion. The key insight underlying TeCo is that predicting the next statement in a test method requires reasoning about code execution, which is hard to do with only syntax-level data that existing code completion models use. TeCo extracts and uses six kinds of code semantics data, including the execution result of prior statements and the execution context of the test method. To provide a testbed for this new task, as well as to evaluate TeCo, we collect a corpus of 130,934 test methods from 1,270 open-source Java projects. Our results show that TeCo achieves an exact-match accuracy of 18, which is 29% higher than the best baseline using syntax-level data only. When measuring functional correctness of generated next statement, TeCo can generate runnable code in 29% of the cases compared to 18% obtained by the best baseline. Moreover, TeCo is significantly better than prior work on test oracle generation.