 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Counterfactual Environment Model Learning
Jun 10, 2022

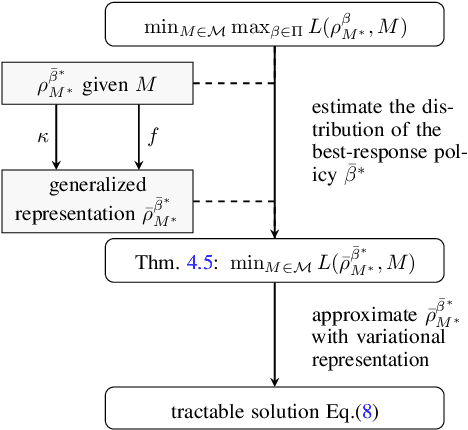

A good model for action-effect prediction, named environment model, is important to achieve sample-efficient decision-making policy learning in many domains like robot control, recommender systems, and patients' treatment selection. We can take unlimited trials with such a model to identify the appropriate actions so that the costs of queries in the real world can be saved. It requires the model to handle unseen data correctly, also called counterfactual data. However, standard data fitting techniques do not automatically achieve such generalization ability and commonly result in unreliable models. In this work, we introduce counterfactual-query risk minimization (CQRM) in model learning for generalizing to a counterfactual dataset queried by a specific target policy. Since the target policies can be various and unknown in policy learning, we propose an adversarial CQRM objective in which the model learns on counterfactual data queried by adversarial policies, and finally derive a tractable solution GALILEO. We also discover that adversarial CQRM is closely related to the adversarial model learning, explaining the effectiveness of the latter. We apply GALILEO in synthetic tasks and a real-world application. The results show that GALILEO makes accurate predictions on counterfactual data and thus significantly improves policies in real-world testing.
A Framework for Multi-stage Bonus Allocation in meal delivery Platform
Feb 22, 2022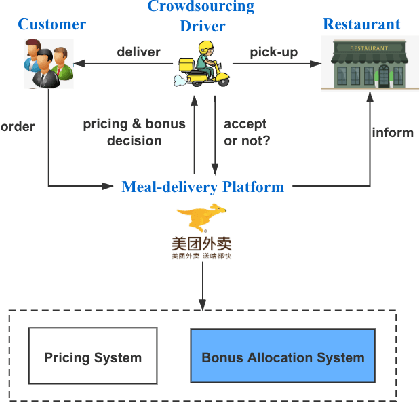

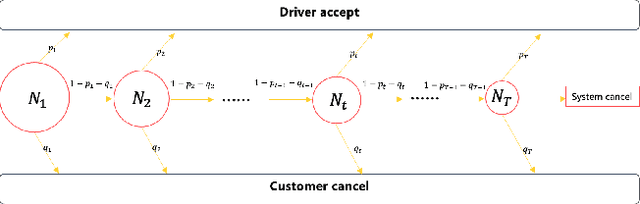
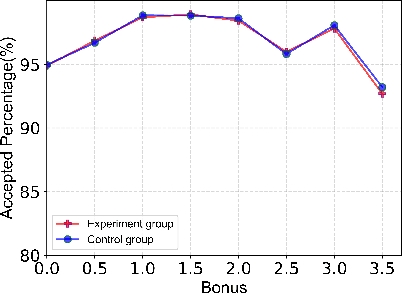
Online meal delivery is undergoing explosive growth, as this service is becoming increasingly popular. A meal delivery platform aims to provide excellent and stable services for customers and restaurants. However, in reality, several hundred thousand orders are canceled per day in the Meituan meal delivery platform since they are not accepted by the crowd soucing drivers. The cancellation of the orders is incredibly detrimental to the customer's repurchase rate and the reputation of the Meituan meal delivery platform. To solve this problem, a certain amount of specific funds is provided by Meituan's business managers to encourage the crowdsourcing drivers to accept more orders. To make better use of the funds, in this work, we propose a framework to deal with the multi-stage bonus allocation problem for a meal delivery platform. The objective of this framework is to maximize the number of accepted orders within a limited bonus budget. This framework consists of a semi-black-box acceptance probability model, a Lagrangian dual-based dynamic programming algorithm, and an online allocation algorithm. The semi-black-box acceptance probability model is employed to forecast the relationship between the bonus allocated to order and its acceptance probability, the Lagrangian dual-based dynamic programming algorithm aims to calculate the empirical Lagrangian multiplier for each allocation stage offline based on the historical data set, and the online allocation algorithm uses the results attained in the offline part to calculate a proper delivery bonus for each order. To verify the effectiveness and efficiency of our framework, both offline experiments on a real-world data set and online A/B tests on the Meituan meal delivery platform are conducted. Our results show that using the proposed framework, the total order cancellations can be decreased by more than 25\% in reality.