 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBriLLM: Brain-inspired Large Language Model
Mar 14, 2025



This paper reports the first brain-inspired large language model (BriLLM). This is a non-Transformer, non-GPT, non-traditional machine learning input-output controlled generative language model. The model is based on the Signal Fully-connected flowing (SiFu) definition on the directed graph in terms of the neural network, and has the interpretability of all nodes on the graph of the whole model, instead of the traditional machine learning model that only has limited interpretability at the input and output ends. In the language model scenario, the token is defined as a node in the graph. A randomly shaped or user-defined signal flow flows between nodes on the principle of "least resistance" along paths. The next token or node to be predicted or generated is the target of the signal flow. As a language model, BriLLM theoretically supports infinitely long $n$-gram models when the model size is independent of the input and predicted length of the model. The model's working signal flow provides the possibility of recall activation and innate multi-modal support similar to the cognitive patterns of the human brain. At present, we released the first BriLLM version in Chinese, with 4000 tokens, 32-dimensional node width, 16-token long sequence prediction ability, and language model prediction performance comparable to GPT-1. More computing power will help us explore the infinite possibilities depicted above.
Towards Enhanced Immersion and Agency for LLM-based Interactive Drama
Feb 25, 2025



LLM-based Interactive Drama is a novel AI-based dialogue scenario, where the user (i.e. the player) plays the role of a character in the story, has conversations with characters played by LLM agents, and experiences an unfolding story. This paper begins with understanding interactive drama from two aspects: Immersion, the player's feeling of being present in the story, and Agency, the player's ability to influence the story world. Both are crucial to creating an enjoyable interactive experience, while they have been underexplored in previous work. To enhance these two aspects, we first propose Playwriting-guided Generation, a novel method that helps LLMs craft dramatic stories with substantially improved structures and narrative quality. Additionally, we introduce Plot-based Reflection for LLM agents to refine their reactions to align with the player's intentions. Our evaluation relies on human judgment to assess the gains of our methods in terms of immersion and agency.
Instruction-Driven Game Engine: A Poker Case Study
Oct 17, 2024The Instruction-Driven Game Engine (IDGE) project aims to democratize game development by enabling a large language model (LLM) to follow free-form game descriptions and generate game-play processes. The IDGE allows users to create games simply by natural language instructions, which significantly lowers the barrier for game development. We approach the learning process for IDGEs as a Next State Prediction task, wherein the model autoregressively predicts the game states given player actions. The computation of game states must be precise; otherwise, slight errors could corrupt the game-play experience. This is challenging because of the gap between stability and diversity. To address this, we train the IDGE in a curriculum manner that progressively increases its exposure to complex scenarios. Our initial progress lies in developing an IDGE for Poker, which not only supports a wide range of poker variants but also allows for highly individualized new poker games through natural language inputs. This work lays the groundwork for future advancements in transforming how games are created and played.
A Coin Has Two Sides: A Novel Detector-Corrector Framework for Chinese Spelling Correction
Sep 06, 2024
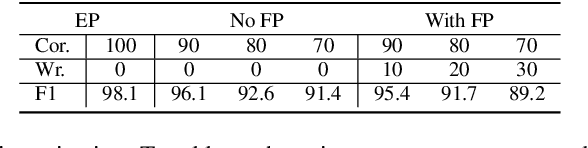


Chinese Spelling Correction (CSC) stands as a foundational Natural Language Processing (NLP) task, which primarily focuses on the correction of erroneous characters in Chinese texts. Certain existing methodologies opt to disentangle the error correction process, employing an additional error detector to pinpoint error positions. However, owing to the inherent performance limitations of error detector, precision and recall are like two sides of the coin which can not be both facing up simultaneously. Furthermore, it is also worth investigating how the error position information can be judiciously applied to assist the error correction. In this paper, we introduce a novel approach based on error detector-corrector framework. Our detector is designed to yield two error detection results, each characterized by high precision and recall. Given that the occurrence of errors is context-dependent and detection outcomes may be less precise, we incorporate the error detection results into the CSC task using an innovative feature fusion strategy and a selective masking strategy. Empirical experiments conducted on mainstream CSC datasets substantiate the efficacy of our proposed method.
Self-Directed Turing Test for Large Language Models
Aug 19, 2024



The Turing test examines whether AIs can exhibit human-like behaviour in natural language conversations. Traditional Turing tests adopt a rigid dialogue format where each participant sends only one message each time and require continuous human involvement to direct the entire interaction with the test subject. This fails to reflect a natural conversational style and hinders the evaluation of Large Language Models (LLMs) in complex and prolonged dialogues. This paper proposes the Self-Directed Turing Test, which extends the original test with a burst dialogue format, allowing more dynamic exchanges by multiple consecutive messages. It further efficiently reduces human workload by having the LLM self-direct the majority of the test process, iteratively generating dialogues that simulate its interaction with humans. With the pseudo-dialogue history, the model then engages in a shorter dialogue with a human, which is paired with a human-human conversation on the same topic to be judged using questionnaires. We introduce the X-Turn Pass-Rate metric to assess the human likeness of LLMs across varying durations. While LLMs like GPT-4 initially perform well, achieving pass rates of 51.9% and 38.9% during 3 turns and 10 turns of dialogues respectively, their performance drops as the dialogue progresses, which underscores the difficulty in maintaining consistency in the long term.
Game Development as Human-LLM Interaction
Aug 18, 2024Game development is a highly specialized task that relies on a complex game engine powered by complex programming languages, preventing many gaming enthusiasts from handling it. This paper introduces the Interaction-driven Game Engine (IGE) powered by LLM, which allows everyone to develop a custom game using natural language through Human-LLM interaction. To enable an LLM to function as an IGE, we instruct it to perform the following processes in each turn: (1) $P_{script}$ : configure the game script segment based on the user's input; (2) $P_{code}$ : generate the corresponding code snippet based on the game script segment; (3) $P_{utter}$ : interact with the user, including guidance and feedback. We propose a data synthesis pipeline based on the LLM to generate game script-code pairs and interactions from a few manually crafted seed data. We propose a three-stage progressive training strategy to transfer the dialogue-based LLM to our IGE smoothly. We construct an IGE for poker games as a case study and comprehensively evaluate it from two perspectives: interaction quality and code correctness. The code and data are available at \url{https://github.com/alterego238/IGE}.
Scaling Virtual World with Delta-Engine
Aug 11, 2024In this paper, we focus on \emph{virtual world}, a cyberspace where people can live in. An ideal virtual world shares great similarity with our real world. One of the crucial aspects is its evolving nature, reflected by the individuals' capacity to grow and thereby influence the objective world. Such dynamics is unpredictable and beyond the reach of existing systems. For this, we propose a special engine called \emph{Delta-Engine} to drive this virtual world. $\Delta$ associates the world's evolution to the engine's expansion. A delta-engine consists of a base engine and a neural proxy. Given an observation, the proxy generates new code based on the base engine through the process of \emph{incremental prediction}. This paper presents a full-stack introduction to the delta-engine. The key feature of the delta-engine is its scalability to unknown elements within the world, Technically, it derives from the prefect co-work of the neural proxy and the base engine, and the alignment with high-quality data. We an engine-oriented fine-tuning method that embeds the base engine into the proxy. We then discuss a human-AI collaborative design process to produce novel and interesting data efficiently. Eventually, we propose three evaluation principles to comprehensively assess the performance of a delta engine: naive evaluation, incremental evaluation, and adversarial evaluation. Our code, data, and models are open-sourced at \url{https://github.com/gingasan/delta-engine}.
From Role-Play to Drama-Interaction: An LLM Solution
May 23, 2024



Drama is a form of storytelling inspired by human creativity, proceeding with a predefined storyline, carrying emotions and thoughts. This paper introduces \emph{LLM-based interactive drama}, which endows traditional drama with an unprecedented immersion, where a person is allowed to walk into it and interact with the characters and scenes. We define this new artistic genre by 6 essential elements-plot, character, thought, diction, spectacle and interaction-and study the entire pipeline to forge a backbone \emph{drama LLM} to drive the playing process, which is challenged by limited drama resources, uncontrollable narrative development, and complicated instruction following. We propose \emph{Narrative Chain} to offer finer control over the narrative progression during interaction with players; \emph{Auto-Drama} to synthesize drama scripts given arbitrary stories; \emph{Sparse Instruction Tuning} to allow the model to follow sophisticated instructions. We manually craft 3 scripts, \emph{Detective Conan}, \emph{Harry Potter}, \emph{Romeo and Juliet}, and design a 5-dimension principle to evaluate the drama LLM comprehensively.
Instruction-Driven Game Engines on Large Language Models
Apr 03, 2024The Instruction-Driven Game Engine (IDGE) project aims to democratize game development by enabling a large language model (LLM) to follow free-form game rules and autonomously generate game-play processes. The IDGE allows users to create games by issuing simple natural language instructions, which significantly lowers the barrier for game development. We approach the learning process for IDGEs as a Next State Prediction task, wherein the model autoregressively predicts in-game states given player actions. It is a challenging task because the computation of in-game states must be precise; otherwise, slight errors could disrupt the game-play. To address this, we train the IDGE in a curriculum manner that progressively increases the model's exposure to complex scenarios. Our initial progress lies in developing an IDGE for Poker, a universally cherished card game. The engine we've designed not only supports a wide range of poker variants but also allows for high customization of rules through natural language inputs. Furthermore, it also favors rapid prototyping of new games from minimal samples, proposing an innovative paradigm in game development that relies on minimal prompt and data engineering. This work lays the groundwork for future advancements in instruction-driven game creation, potentially transforming how games are designed and played.
Unveiling Vulnerability of Self-Attention
Feb 26, 2024Pre-trained language models (PLMs) are shown to be vulnerable to minor word changes, which poses a big threat to real-world systems. While previous studies directly focus on manipulating word inputs, they are limited by their means of generating adversarial samples, lacking generalization to versatile real-world attack. This paper studies the basic structure of transformer-based PLMs, the self-attention (SA) mechanism. (1) We propose a powerful perturbation technique \textit{HackAttend}, which perturbs the attention scores within the SA matrices via meticulously crafted attention masks. We show that state-of-the-art PLMs fall into heavy vulnerability that minor attention perturbations $(1\%)$ can produce a very high attack success rate $(98\%)$. Our paper expands the conventional text attack of word perturbations to more general structural perturbations. (2) We introduce \textit{S-Attend}, a novel smoothing technique that effectively makes SA robust via structural perturbations. We empirically demonstrate that this simple yet effective technique achieves robust performance on par with adversarial training when facing various text attackers. Code is publicly available at \url{github.com/liongkj/HackAttend}.