 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObtaining Optimal Spiking Neural Network in Sequence Learning via CRNN-SNN Conversion
Aug 18, 2024



Spiking neural networks (SNNs) are becoming a promising alternative to conventional artificial neural networks (ANNs) due to their rich neural dynamics and the implementation of energy-efficient neuromorphic chips. However, the non-differential binary communication mechanism makes SNN hard to converge to an ANN-level accuracy. When SNN encounters sequence learning, the situation becomes worse due to the difficulties in modeling long-range dependencies. To overcome these difficulties, researchers developed variants of LIF neurons and different surrogate gradients but still failed to obtain good results when the sequence became longer (e.g., $>$500). Unlike them, we obtain an optimal SNN in sequence learning by directly mapping parameters from a quantized CRNN. We design two sub-pipelines to support the end-to-end conversion of different structures in neural networks, which is called CNN-Morph (CNN $\rightarrow$ QCNN $\rightarrow$ BIFSNN) and RNN-Morph (RNN $\rightarrow$ QRNN $\rightarrow$ RBIFSNN). Using conversion pipelines and the s-analog encoding method, the conversion error of our framework is zero. Furthermore, we give the theoretical and experimental demonstration of the lossless CRNN-SNN conversion. Our results show the effectiveness of our method over short and long timescales tasks compared with the state-of-the-art learning- and conversion-based methods. We reach the highest accuracy of 99.16% (0.46 $\uparrow$) on S-MNIST, 94.95% (3.95 $\uparrow$) on PS-MNIST (sequence length of 784) respectively, and the lowest loss of 0.057 (0.013 $\downarrow$) within 8 time-steps in collision avoidance dataset.
Scaling Virtual World with Delta-Engine
Aug 11, 2024In this paper, we focus on \emph{virtual world}, a cyberspace where people can live in. An ideal virtual world shares great similarity with our real world. One of the crucial aspects is its evolving nature, reflected by the individuals' capacity to grow and thereby influence the objective world. Such dynamics is unpredictable and beyond the reach of existing systems. For this, we propose a special engine called \emph{Delta-Engine} to drive this virtual world. $\Delta$ associates the world's evolution to the engine's expansion. A delta-engine consists of a base engine and a neural proxy. Given an observation, the proxy generates new code based on the base engine through the process of \emph{incremental prediction}. This paper presents a full-stack introduction to the delta-engine. The key feature of the delta-engine is its scalability to unknown elements within the world, Technically, it derives from the prefect co-work of the neural proxy and the base engine, and the alignment with high-quality data. We an engine-oriented fine-tuning method that embeds the base engine into the proxy. We then discuss a human-AI collaborative design process to produce novel and interesting data efficiently. Eventually, we propose three evaluation principles to comprehensively assess the performance of a delta engine: naive evaluation, incremental evaluation, and adversarial evaluation. Our code, data, and models are open-sourced at \url{https://github.com/gingasan/delta-engine}.
BKDSNN: Enhancing the Performance of Learning-based Spiking Neural Networks Training with Blurred Knowledge Distillation
Jul 12, 2024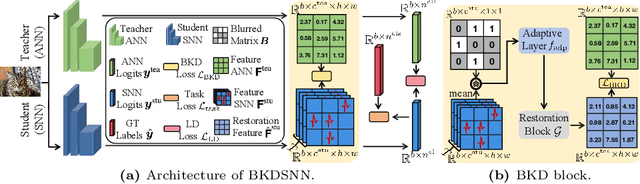

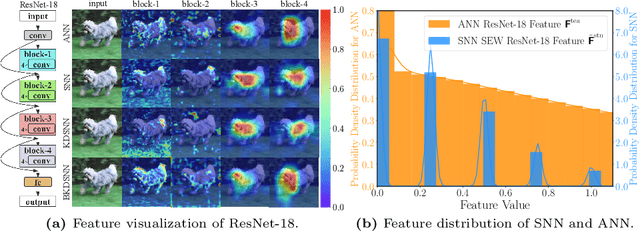
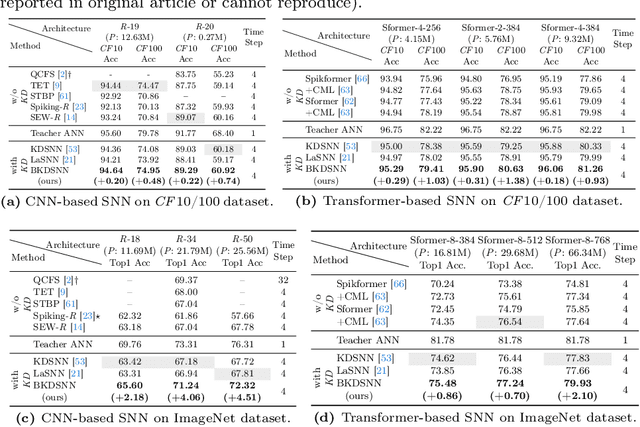
Spiking neural networks (SNNs), which mimic biological neural system to convey information via discrete spikes, are well known as brain-inspired models with excellent computing efficiency. By utilizing the surrogate gradient estimation for discrete spikes, learning-based SNN training methods that can achieve ultra-low inference latency (number of time-step) emerge recently. Nevertheless, due to the difficulty in deriving precise gradient estimation for discrete spikes using learning-based method, a distinct accuracy gap persists between SNN and its artificial neural networks (ANNs) counterpart. To address the aforementioned issue, we propose a blurred knowledge distillation (BKD) technique, which leverages random blurred SNN feature to restore and imitate the ANN feature. Note that, our BKD is applied upon the feature map right before the last layer of SNN, which can also mix with prior logits-based knowledge distillation for maximized accuracy boost. To our best knowledge, in the category of learning-based methods, our work achieves state-of-the-art performance for training SNNs on both static and neuromorphic datasets. On ImageNet dataset, BKDSNN outperforms prior best results by 4.51% and 0.93% with the network topology of CNN and Transformer respectively.
SpikeZIP-TF: Conversion is All You Need for Transformer-based SNN
Jun 05, 2024



Spiking neural network (SNN) has attracted great attention due to its characteristic of high efficiency and accuracy. Currently, the ANN-to-SNN conversion methods can obtain ANN on-par accuracy SNN with ultra-low latency (8 time-steps) in CNN structure on computer vision (CV) tasks. However, as Transformer-based networks have achieved prevailing precision on both CV and natural language processing (NLP), the Transformer-based SNNs are still encounting the lower accuracy w.r.t the ANN counterparts. In this work, we introduce a novel ANN-to-SNN conversion method called SpikeZIP-TF, where ANN and SNN are exactly equivalent, thus incurring no accuracy degradation. SpikeZIP-TF achieves 83.82% accuracy on CV dataset (ImageNet) and 93.79% accuracy on NLP dataset (SST-2), which are higher than SOTA Transformer-based SNNs. The code is available in GitHub: https://github.com/Intelligent-Computing-Research-Group/SpikeZIP_transformer
Improvements on Recommender System based on Mathematical Principles
Apr 26, 2023In this article, we will research the Recommender System's implementation about how it works and the algorithms used. We will explain the Recommender System's algorithms based on mathematical principles, and find feasible methods for improvements. The algorithms based on probability have its significance in Recommender System, we will describe how they help to increase the accuracy and speed of the algorithms. Both the weakness and the strength of two different mathematical distance used to describe the similarity will be detailed illustrated in this article.
Delving into Transformer for Incremental Semantic Segmentation
Nov 18, 2022



Incremental semantic segmentation(ISS) is an emerging task where old model is updated by incrementally adding new classes. At present, methods based on convolutional neural networks are dominant in ISS. However, studies have shown that such methods have difficulty in learning new tasks while maintaining good performance on old ones (catastrophic forgetting). In contrast, a Transformer based method has a natural advantage in curbing catastrophic forgetting due to its ability to model both long-term and short-term tasks. In this work, we explore the reasons why Transformer based architecture are more suitable for ISS, and accordingly propose propose TISS, a Transformer based method for Incremental Semantic Segmentation. In addition, to better alleviate catastrophic forgetting while preserving transferability on ISS, we introduce two patch-wise contrastive losses to imitate similar features and enhance feature diversity respectively, which can further improve the performance of TISS. Under extensive experimental settings with Pascal-VOC 2012 and ADE20K datasets, our method significantly outperforms state-of-the-art incremental semantic segmentation methods.
Towards Domain Generalization in Object Detection
Mar 27, 2022
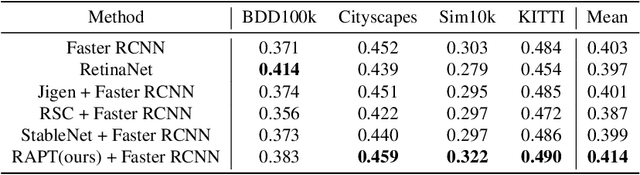
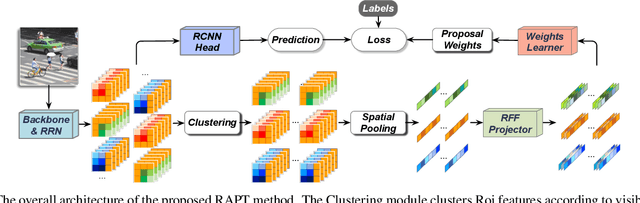
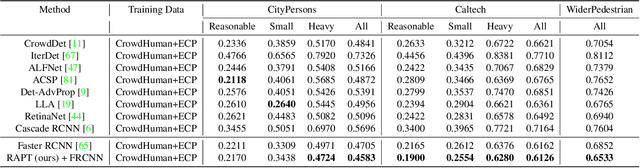
Despite the striking performance achieved by modern detectors when training and test data are sampled from the same or similar distribution, the generalization ability of detectors under unknown distribution shifts remains hardly studied. Recently several works discussed the detectors' adaptation ability to a specific target domain which are not readily applicable in real-world applications since detectors may encounter various environments or situations while pre-collecting all of them before training is inconceivable. In this paper, we study the critical problem, domain generalization in object detection (DGOD), where detectors are trained with source domains and evaluated on unknown target domains. To thoroughly evaluate detectors under unknown distribution shifts, we formulate the DGOD problem and propose a comprehensive evaluation benchmark to fill the vacancy. Moreover, we propose a novel method named Region Aware Proposal reweighTing (RAPT) to eliminate dependence within RoI features. Extensive experiments demonstrate that current DG methods fail to address the DGOD problem and our method outperforms other state-of-the-art counterparts.