 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELSA: An ELastic SNN Inference Architecture for Efficient Neuromorphic Computing
May 20, 2026Spiking neural networks (SNNs) exploit event-driven and addition-only computation to substantially improve efficiency for intelligent computation. A key temporal property of SNNs, elastic inference, allows outputs to emerge progressively, enabling responses to salient inputs much earlier than full evaluation. However, existing SNN-specific accelerators cannot capitalize on this property. Layer-by-layer designs emit outputs only after all layers are complete, while time-step-by-time-step designs rely on coarse-grained, layer-wise pipelines that require synchronizing all spines/tokens within a layer. This barrier prevents results from being forwarded immediately, delaying the earliest possible response and forfeiting the benefits of elastic inference. To address these challenges, we propose ELSA, a near-SRAM dataflow architecture that realizes true elastic inference through a fine-grained spine/token-wise pipeline and hardware optimizations tailored to SNNs. ELSA forwards each spine/token immediately upon production, forming a continuous streaming pipeline that substantially reduces the latency to the first response. To enhance this lightweight execution, ELSA introduces a bundled address event representation protocol to lower communication traffic of network-on-chip (NoC), and leverages mini-batch spiking Gustavson-product to cut memory access and exploit inherent sparsity. Combined with mapping and scheduling optimizations, ELSA achieves efficient, event-driven computation without compromising accuracy. Experiments show that SNNs can outperform quantized artificial neural networks (QANNs) while maintaining on-par accuracy. For a 4-bit ResNet-50, ELSA achieves 3.4$\times$ speedup and 13.6$\times$ higher energy efficiency over the SOTA QANN accelerator (ANT), and 2.9$\times$ speedup and 22.1$\times$ energy efficiency gains over the SOTA SNN accelerator (PAICORE).
Determinism in the Undetermined: Deterministic Output in Charge-Conserving Continuous-Time Neuromorphic Systems with Temporal Stochasticity
Mar 16, 2026Achieving deterministic computation results in asynchronous neuromorphic systems remains a fundamental challenge due to the inherent temporal stochasticity of continuous-time hardware. To address this, we develop a unified continuous-time framework for spiking neural networks (SNNs) that couples the Law of Charge Conservation with minimal neuron-level constraints. This integration ensures that the terminal state depends solely on the aggregate input charge, providing a unique cumulated output invariant to temporal stochasticity. We prove that this mapping is strictly invariant to spike timing in acyclic networks, whereas recurrent connectivity can introduce temporal sensitivity. Furthermore, we establish an exact representational correspondence between these charge-conserving SNNs and quantized artificial neural networks, bridging the gap between static deep learning and event-driven dynamics without approximation errors. These results establish a rigorous theoretical basis for designing continuous-time neuromorphic systems that harness the efficiency of asynchronous processing while maintaining algorithmic determinism.
Differential Dynamic Causal Nets: Model Construction, Identification and Group Comparisons
Jan 29, 2026Pathophysiolpgical modelling of brain systems from microscale to macroscale remains difficult in group comparisons partly because of the infeasibility of modelling the interactions of thousands of neurons at the scales involved. Here, to address the challenge, we present a novel approach to construct differential causal networks directly from electroencephalogram (EEG) data. The proposed network is based on conditionally coupled neuronal circuits which describe the average behaviour of interacting neuron populations that contribute to observed EEG data. In the network, each node represents a parameterised local neural system while directed edges stand for node-wise connections with transmission parameters. The network is hierarchically structured in the sense that node and edge parameters are varying in subjects but follow a mixed-effects model. A novel evolutionary optimisation algorithm for parameter inference in the proposed method is developed using a loss function derived from Chen-Fliess expansions of stochastic differential equations. The method is demonstrated by application to the fitting of coupled Jansen-Rit local models. The performance of the proposed method is evaluated on both synthetic and real EEG data. In the real EEG data analysis, we track changes in the parameters that characterise dynamic causality within brains that demonstrate epileptic activity. We show evidence of network functional disruptions, due to imbalance of excitatory-inhibitory interneurons and altered epileptic brain connectivity, before and during seizure periods.
Efficient LiDAR Reflectance Compression via Scanning Serialization
May 14, 2025Reflectance attributes in LiDAR point clouds provide essential information for downstream tasks but remain underexplored in neural compression methods. To address this, we introduce SerLiC, a serialization-based neural compression framework to fully exploit the intrinsic characteristics of LiDAR reflectance. SerLiC first transforms 3D LiDAR point clouds into 1D sequences via scan-order serialization, offering a device-centric perspective for reflectance analysis. Each point is then tokenized into a contextual representation comprising its sensor scanning index, radial distance, and prior reflectance, for effective dependencies exploration. For efficient sequential modeling, Mamba is incorporated with a dual parallelization scheme, enabling simultaneous autoregressive dependency capture and fast processing. Extensive experiments demonstrate that SerLiC attains over 2x volume reduction against the original reflectance data, outperforming the state-of-the-art method by up to 22% reduction of compressed bits while using only 2% of its parameters. Moreover, a lightweight version of SerLiC achieves > 10 fps (frames per second) with just 111K parameters, which is attractive for real-world applications.
RENO: Real-Time Neural Compression for 3D LiDAR Point Clouds
Mar 16, 2025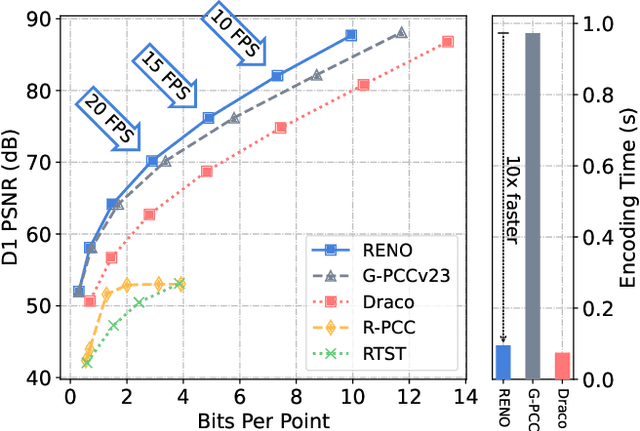
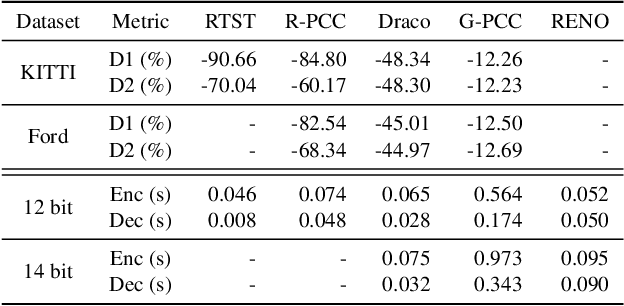
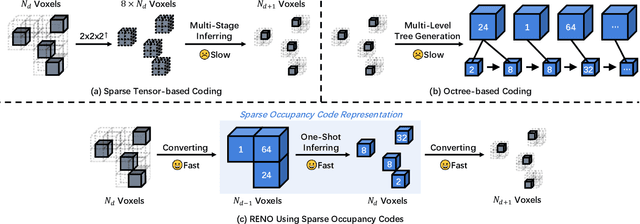
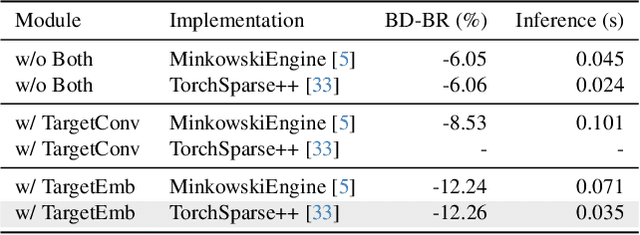
Despite the substantial advancements demonstrated by learning-based neural models in the LiDAR Point Cloud Compression (LPCC) task, realizing real-time compression - an indispensable criterion for numerous industrial applications - remains a formidable challenge. This paper proposes RENO, the first real-time neural codec for 3D LiDAR point clouds, achieving superior performance with a lightweight model. RENO skips the octree construction and directly builds upon the multiscale sparse tensor representation. Instead of the multi-stage inferring, RENO devises sparse occupancy codes, which exploit cross-scale correlation and derive voxels' occupancy in a one-shot manner, greatly saving processing time. Experimental results demonstrate that the proposed RENO achieves real-time coding speed, 10 fps at 14-bit depth on a desktop platform (e.g., one RTX 3090 GPU) for both encoding and decoding processes, while providing 12.25% and 48.34% bit-rate savings compared to G-PCCv23 and Draco, respectively, at a similar quality. RENO model size is merely 1MB, making it attractive for practical applications. The source code is available at https://github.com/NJUVISION/RENO.
Att2CPC: Attention-Guided Lossy Attribute Compression of Point Clouds
Oct 23, 2024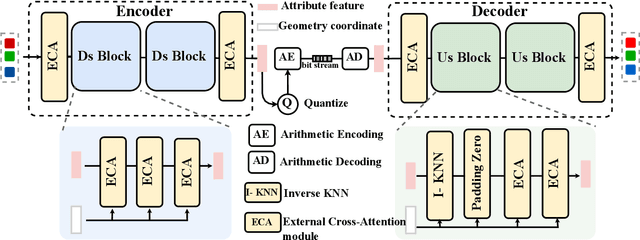

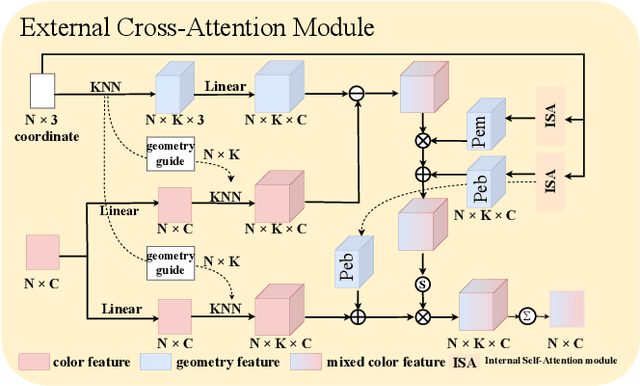
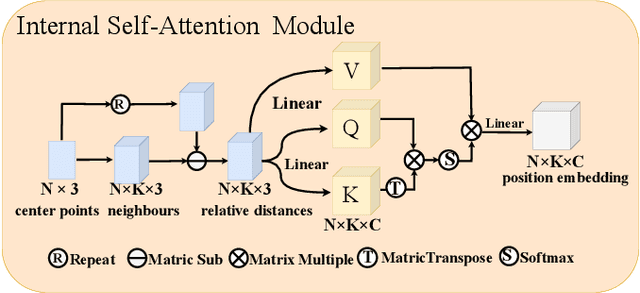
With the great progress of 3D sensing and acquisition technology, the volume of point cloud data has grown dramatically, which urges the development of efficient point cloud compression methods. In this paper, we focus on the task of learned lossy point cloud attribute compression (PCAC). We propose an efficient attention-based method for lossy compression of point cloud attributes leveraging on an autoencoder architecture. Specifically, at the encoding side, we conduct multiple downsampling to best exploit the local attribute patterns, in which effective External Cross Attention (ECA) is devised to hierarchically aggregate features by intergrating attributes and geometry contexts. At the decoding side, the attributes of the point cloud are progressively reconstructed based on the multi-scale representation and the zero-padding upsampling tactic. To the best of our knowledge, this is the first approach to introduce attention mechanism to point-based lossy PCAC task. We verify the compression efficiency of our model on various sequences, including human body frames, sparse objects, and large-scale point cloud scenes. Experiments show that our method achieves an average improvement of 1.15 dB and 2.13 dB in BD-PSNR of Y channel and YUV channel, respectively, when comparing with the state-of-the-art point-based method Deep-PCAC. Codes of this paper are available at https://github.com/I2-Multimedia-Lab/Att2CPC.
Diff-PCC: Diffusion-based Neural Compression for 3D Point Clouds
Aug 20, 2024
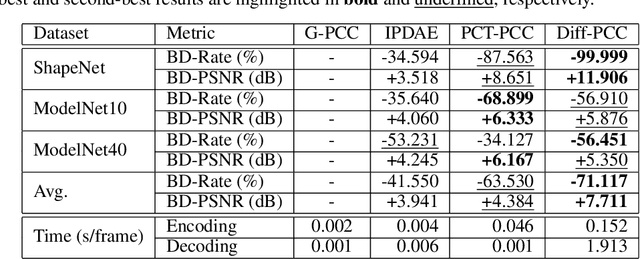


Stable diffusion networks have emerged as a groundbreaking development for their ability to produce realistic and detailed visual content. This characteristic renders them ideal decoders, capable of producing high-quality and aesthetically pleasing reconstructions. In this paper, we introduce the first diffusion-based point cloud compression method, dubbed Diff-PCC, to leverage the expressive power of the diffusion model for generative and aesthetically superior decoding. Different from the conventional autoencoder fashion, a dual-space latent representation is devised in this paper, in which a compressor composed of two independent encoding backbones is considered to extract expressive shape latents from distinct latent spaces. At the decoding side, a diffusion-based generator is devised to produce high-quality reconstructions by considering the shape latents as guidance to stochastically denoise the noisy point clouds. Experiments demonstrate that the proposed Diff-PCC achieves state-of-the-art compression performance (e.g., 7.711 dB BD-PSNR gains against the latest G-PCC standard at ultra-low bitrate) while attaining superior subjective quality. Source code will be made publicly available.
Obtaining Optimal Spiking Neural Network in Sequence Learning via CRNN-SNN Conversion
Aug 18, 2024



Spiking neural networks (SNNs) are becoming a promising alternative to conventional artificial neural networks (ANNs) due to their rich neural dynamics and the implementation of energy-efficient neuromorphic chips. However, the non-differential binary communication mechanism makes SNN hard to converge to an ANN-level accuracy. When SNN encounters sequence learning, the situation becomes worse due to the difficulties in modeling long-range dependencies. To overcome these difficulties, researchers developed variants of LIF neurons and different surrogate gradients but still failed to obtain good results when the sequence became longer (e.g., $>$500). Unlike them, we obtain an optimal SNN in sequence learning by directly mapping parameters from a quantized CRNN. We design two sub-pipelines to support the end-to-end conversion of different structures in neural networks, which is called CNN-Morph (CNN $\rightarrow$ QCNN $\rightarrow$ BIFSNN) and RNN-Morph (RNN $\rightarrow$ QRNN $\rightarrow$ RBIFSNN). Using conversion pipelines and the s-analog encoding method, the conversion error of our framework is zero. Furthermore, we give the theoretical and experimental demonstration of the lossless CRNN-SNN conversion. Our results show the effectiveness of our method over short and long timescales tasks compared with the state-of-the-art learning- and conversion-based methods. We reach the highest accuracy of 99.16% (0.46 $\uparrow$) on S-MNIST, 94.95% (3.95 $\uparrow$) on PS-MNIST (sequence length of 784) respectively, and the lowest loss of 0.057 (0.013 $\downarrow$) within 8 time-steps in collision avoidance dataset.
Global Attention-Guided Dual-Domain Point Cloud Feature Learning for Classification and Segmentation
Jul 12, 2024



Previous studies have demonstrated the effectiveness of point-based neural models on the point cloud analysis task. However, there remains a crucial issue on producing the efficient input embedding for raw point coordinates. Moreover, another issue lies in the limited efficiency of neighboring aggregations, which is a critical component in the network stem. In this paper, we propose a Global Attention-guided Dual-domain Feature Learning network (GAD) to address the above-mentioned issues. We first devise the Contextual Position-enhanced Transformer (CPT) module, which is armed with an improved global attention mechanism, to produce a global-aware input embedding that serves as the guidance to subsequent aggregations. Then, the Dual-domain K-nearest neighbor Feature Fusion (DKFF) is cascaded to conduct effective feature aggregation through novel dual-domain feature learning which appreciates both local geometric relations and long-distance semantic connections. Extensive experiments on multiple point cloud analysis tasks (e.g., classification, part segmentation, and scene semantic segmentation) demonstrate the superior performance of the proposed method and the efficacy of the devised modules.
BKDSNN: Enhancing the Performance of Learning-based Spiking Neural Networks Training with Blurred Knowledge Distillation
Jul 12, 2024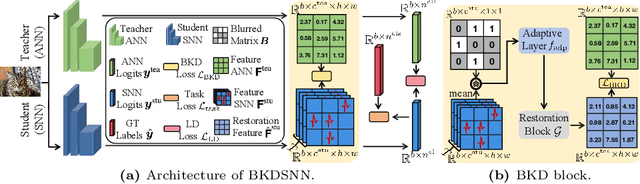

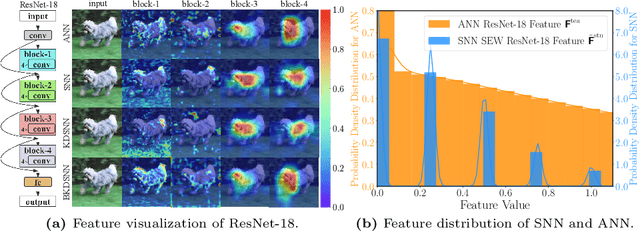
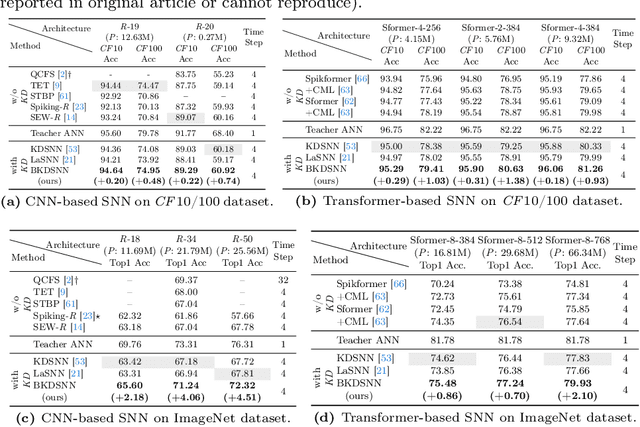
Spiking neural networks (SNNs), which mimic biological neural system to convey information via discrete spikes, are well known as brain-inspired models with excellent computing efficiency. By utilizing the surrogate gradient estimation for discrete spikes, learning-based SNN training methods that can achieve ultra-low inference latency (number of time-step) emerge recently. Nevertheless, due to the difficulty in deriving precise gradient estimation for discrete spikes using learning-based method, a distinct accuracy gap persists between SNN and its artificial neural networks (ANNs) counterpart. To address the aforementioned issue, we propose a blurred knowledge distillation (BKD) technique, which leverages random blurred SNN feature to restore and imitate the ANN feature. Note that, our BKD is applied upon the feature map right before the last layer of SNN, which can also mix with prior logits-based knowledge distillation for maximized accuracy boost. To our best knowledge, in the category of learning-based methods, our work achieves state-of-the-art performance for training SNNs on both static and neuromorphic datasets. On ImageNet dataset, BKDSNN outperforms prior best results by 4.51% and 0.93% with the network topology of CNN and Transformer respectively.