 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtt2CPC: Attention-Guided Lossy Attribute Compression of Point Clouds
Paper and Code
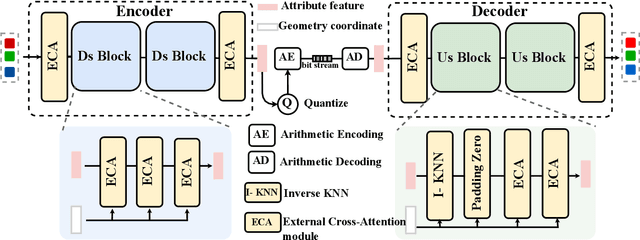

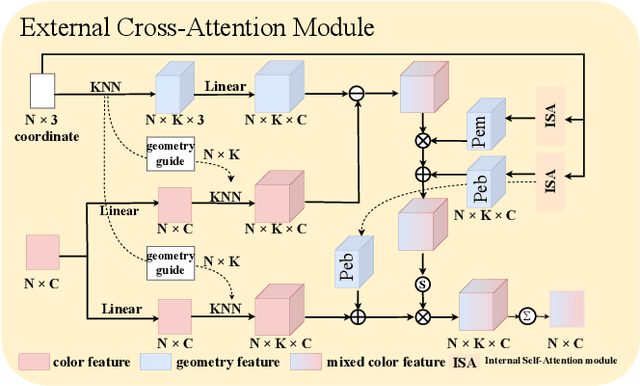
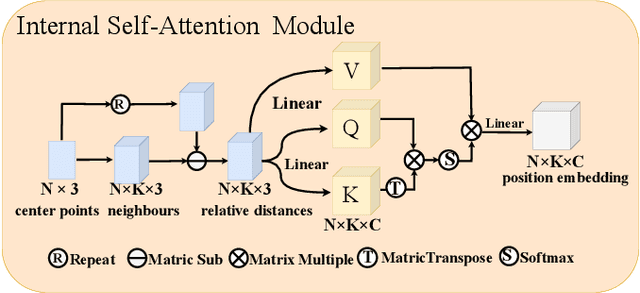
With the great progress of 3D sensing and acquisition technology, the volume of point cloud data has grown dramatically, which urges the development of efficient point cloud compression methods. In this paper, we focus on the task of learned lossy point cloud attribute compression (PCAC). We propose an efficient attention-based method for lossy compression of point cloud attributes leveraging on an autoencoder architecture. Specifically, at the encoding side, we conduct multiple downsampling to best exploit the local attribute patterns, in which effective External Cross Attention (ECA) is devised to hierarchically aggregate features by intergrating attributes and geometry contexts. At the decoding side, the attributes of the point cloud are progressively reconstructed based on the multi-scale representation and the zero-padding upsampling tactic. To the best of our knowledge, this is the first approach to introduce attention mechanism to point-based lossy PCAC task. We verify the compression efficiency of our model on various sequences, including human body frames, sparse objects, and large-scale point cloud scenes. Experiments show that our method achieves an average improvement of 1.15 dB and 2.13 dB in BD-PSNR of Y channel and YUV channel, respectively, when comparing with the state-of-the-art point-based method Deep-PCAC. Codes of this paper are available at https://github.com/I2-Multimedia-Lab/Att2CPC.