 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiff-PCC: Diffusion-based Neural Compression for 3D Point Clouds
Paper and Code
Aug 20, 2024
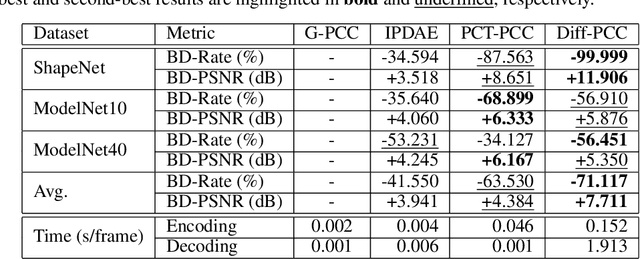


Stable diffusion networks have emerged as a groundbreaking development for their ability to produce realistic and detailed visual content. This characteristic renders them ideal decoders, capable of producing high-quality and aesthetically pleasing reconstructions. In this paper, we introduce the first diffusion-based point cloud compression method, dubbed Diff-PCC, to leverage the expressive power of the diffusion model for generative and aesthetically superior decoding. Different from the conventional autoencoder fashion, a dual-space latent representation is devised in this paper, in which a compressor composed of two independent encoding backbones is considered to extract expressive shape latents from distinct latent spaces. At the decoding side, a diffusion-based generator is devised to produce high-quality reconstructions by considering the shape latents as guidance to stochastically denoise the noisy point clouds. Experiments demonstrate that the proposed Diff-PCC achieves state-of-the-art compression performance (e.g., 7.711 dB BD-PSNR gains against the latest G-PCC standard at ultra-low bitrate) while attaining superior subjective quality. Source code will be made publicly available.