 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentUM: Unleashing the Potential of Interleaved Cross-Modal Reasoning via a Latent-Space Unified Model
Apr 02, 2026Unified models (UMs) hold promise for their ability to understand and generate content across heterogeneous modalities. Compared to merely generating visual content, the use of UMs for interleaved cross-modal reasoning is more promising and valuable, e.g., for solving understanding problems that require dense visual thinking, improving visual generation through self-reflection, or modeling visual dynamics of the physical world guided by stepwise action interventions. However, existing UMs necessitate pixel decoding as a bridge due to their disjoint visual representations for understanding and generation, which is both ineffective and inefficient. In this paper, we introduce LatentUM, a novel unified model that represents all modalities within a shared semantic latent space, eliminating the need for pixel-space mediation between visual understanding and generation. This design naturally enables flexible interleaved cross-modal reasoning and generation. Beyond improved computational efficiency, the shared representation substantially alleviates codec bias and strengthens cross-modal alignment, allowing LatentUM to achieve state-of-the-art performance on the Visual Spatial Planning benchmark, push the limits of visual generation through self-reflection, and support world modeling by predicting future visual states within the shared semantic latent space.
Think-Then-Generate: Reasoning-Aware Text-to-Image Diffusion with LLM Encoders
Jan 15, 2026Recent progress in text-to-image (T2I) diffusion models (DMs) has enabled high-quality visual synthesis from diverse textual prompts. Yet, most existing T2I DMs, even those equipped with large language model (LLM)-based text encoders, remain text-pixel mappers -- they employ LLMs merely as text encoders, without leveraging their inherent reasoning capabilities to infer what should be visually depicted given the textual prompt. To move beyond such literal generation, we propose the think-then-generate (T2G) paradigm, where the LLM-based text encoder is encouraged to reason about and rewrite raw user prompts; the states of the rewritten prompts then serve as diffusion conditioning. To achieve this, we first activate the think-then-rewrite pattern of the LLM encoder with a lightweight supervised fine-tuning process. Subsequently, the LLM encoder and diffusion backbone are co-optimized to ensure faithful reasoning about the context and accurate rendering of the semantics via Dual-GRPO. In particular, the text encoder is reinforced using image-grounded rewards to infer and recall world knowledge, while the diffusion backbone is pushed to produce semantically consistent and visually coherent images. Experiments show substantial improvements in factual consistency, semantic alignment, and visual realism across reasoning-based image generation and editing benchmarks, achieving 0.79 on WISE score, nearly on par with GPT-4. Our results constitute a promising step toward next-generation unified models with reasoning, expression, and demonstration capacities.
d3LLM: Ultra-Fast Diffusion LLM using Pseudo-Trajectory Distillation
Jan 12, 2026Diffusion large language models (dLLMs) offer capabilities beyond those of autoregressive (AR) LLMs, such as parallel decoding and random-order generation. However, realizing these benefits in practice is non-trivial, as dLLMs inherently face an accuracy-parallelism trade-off. Despite increasing interest, existing methods typically focus on only one-side of the coin, targeting either efficiency or performance. To address this limitation, we propose d3LLM (Pseudo-Distilled Diffusion Large Language Model), striking a balance between accuracy and parallelism: (i) during training, we introduce pseudo-trajectory distillation to teach the model which tokens can be decoded confidently at early steps, thereby improving parallelism; (ii) during inference, we employ entropy-based multi-block decoding with a KV-cache refresh mechanism to achieve high parallelism while maintaining accuracy. To better evaluate dLLMs, we also introduce AUP (Accuracy Under Parallelism), a new metric that jointly measures accuracy and parallelism. Experiments demonstrate that our d3LLM achieves up to 10$\times$ speedup over vanilla LLaDA/Dream and 5$\times$ speedup over AR models without much accuracy drop. Our code is available at https://github.com/hao-ai-lab/d3LLM.
LiveTalk: Real-Time Multimodal Interactive Video Diffusion via Improved On-Policy Distillation
Dec 29, 2025Real-time video generation via diffusion is essential for building general-purpose multimodal interactive AI systems. However, the simultaneous denoising of all video frames with bidirectional attention via an iterative process in diffusion models prevents real-time interaction. While existing distillation methods can make the model autoregressive and reduce sampling steps to mitigate this, they focus primarily on text-to-video generation, leaving the human-AI interaction unnatural and less efficient. This paper targets real-time interactive video diffusion conditioned on a multimodal context, including text, image, and audio, to bridge the gap. Given the observation that the leading on-policy distillation approach Self Forcing encounters challenges (visual artifacts like flickering, black frames, and quality degradation) with multimodal conditioning, we investigate an improved distillation recipe with emphasis on the quality of condition inputs as well as the initialization and schedule for the on-policy optimization. On benchmarks for multimodal-conditioned (audio, image, and text) avatar video generation including HDTF, AVSpeech, and CelebV-HQ, our distilled model matches the visual quality of the full-step, bidirectional baselines of similar or larger size with 20x less inference cost and latency. Further, we integrate our model with audio language models and long-form video inference technique Anchor-Heavy Identity Sinks to build LiveTalk, a real-time multimodal interactive avatar system. System-level evaluation on our curated multi-turn interaction benchmark shows LiveTalk outperforms state-of-the-art models (Sora2, Veo3) in multi-turn video coherence and content quality, while reducing response latency from 1 to 2 minutes to real-time generation, enabling seamless human-AI multimodal interaction.
LoPA: Scaling dLLM Inference via Lookahead Parallel Decoding
Dec 22, 2025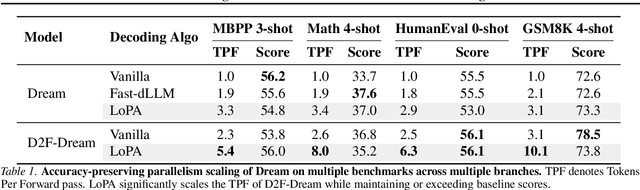
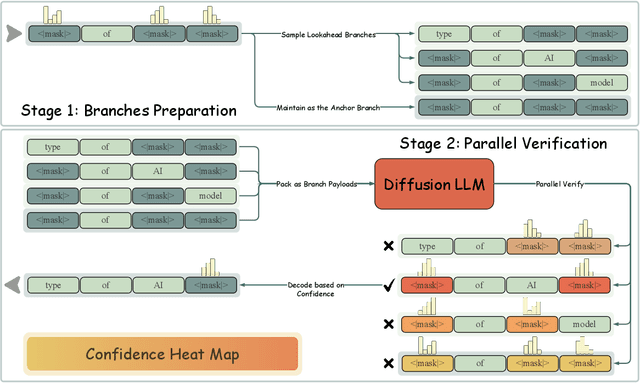
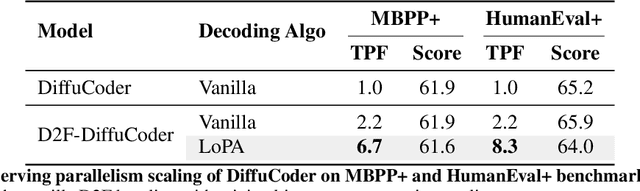
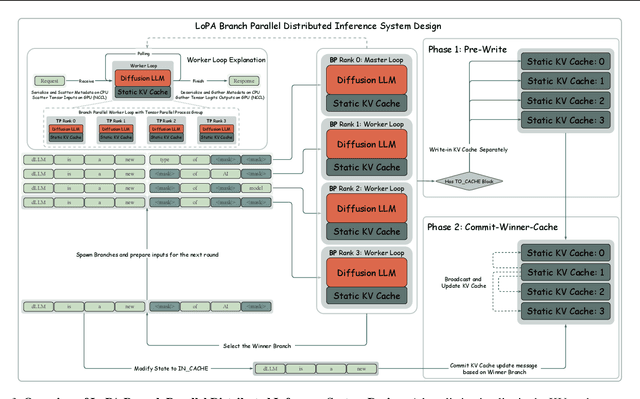
Diffusion Large Language Models (dLLMs) have demonstrated significant potential for high-speed inference. However, current confidence-driven decoding strategies are constrained by limited parallelism, typically achieving only 1--3 tokens per forward pass (TPF). In this work, we identify that the degree of parallelism during dLLM inference is highly sensitive to the Token Filling Order (TFO). Then, we introduce Lookahead PArallel Decoding LoPA, a training-free, plug-and-play algorithm, to identify a superior TFO and hence accelerate inference. LoPA concurrently explores distinct candidate TFOs via parallel branches, and selects the one with the highest potential for future parallelism based on branch confidence. We apply LoPA to the state-of-the-art D2F model and observe a substantial enhancement in decoding efficiency. Notably, LoPA increases the TPF of D2F-Dream to 10.1 on the GSM8K while maintaining performance superior to the Dream baseline. Furthermore, to facilitate this unprecedented degree of parallelism, we develop a specialized multi-device inference system featuring Branch Parallelism (BP), which achieves a single-sample throughput of 1073.9 tokens per second under multi-GPU deployment. The code is available at https://github.com/zhijie-group/LoPA.
DEER: Draft with Diffusion, Verify with Autoregressive Models
Dec 17, 2025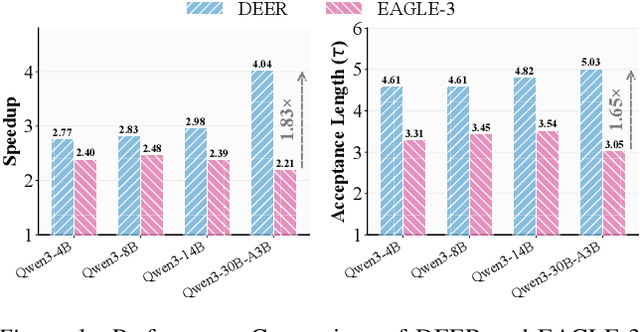
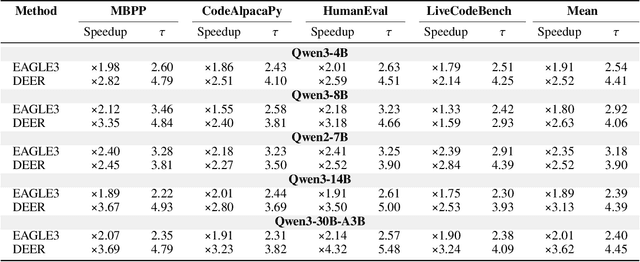
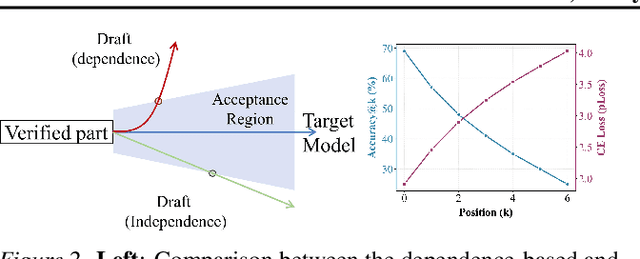
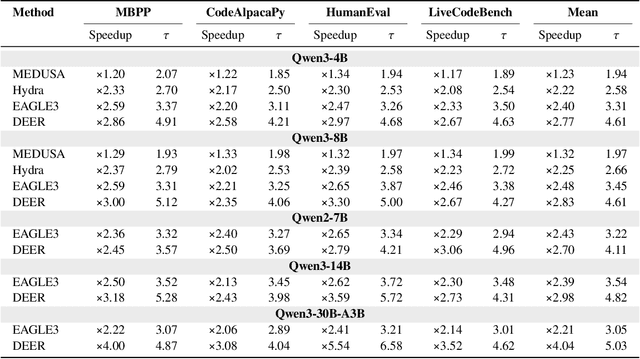
Efficiency, as a critical practical challenge for LLM-driven agentic and reasoning systems, is increasingly constrained by the inherent latency of autoregressive (AR) decoding. Speculative decoding mitigates this cost through a draft-verify scheme, yet existing approaches rely on AR draft models (a.k.a., drafters), which introduce two fundamental issues: (1) step-wise uncertainty accumulation leads to a progressive collapse of trust between the target model and the drafter, and (2) inherently sequential decoding of AR drafters. Together, these factors cause limited speedups. In this paper, we show that a diffusion large language model (dLLM) drafters can naturally overcome these issues through its fundamentally different probabilistic modeling and efficient parallel decoding strategy. Building on this insight, we introduce DEER, an efficient speculative decoding framework that drafts with diffusion and verifies with AR models. To enable high-quality drafting, DEER employs a two-stage training pipeline to align the dLLM-based drafters with the target AR model, and further adopts single-step decoding to generate long draft segments. Experiments show DEER reaches draft acceptance lengths of up to 32 tokens, far surpassing the 10 tokens achieved by EAGLE-3. Moreover, on HumanEval with Qwen3-30B-A3B, DEER attains a 5.54x speedup, while EAGLE-3 achieves only 2.41x. Code, model, demo, etc, will be available at https://czc726.github.io/DEER/
Fast and Accurate Causal Parallel Decoding using Jacobi Forcing
Dec 16, 2025Multi-token generation has emerged as a promising paradigm for accelerating transformer-based large model inference. Recent efforts primarily explore diffusion Large Language Models (dLLMs) for parallel decoding to reduce inference latency. To achieve AR-level generation quality, many techniques adapt AR models into dLLMs to enable parallel decoding. However, they suffer from limited speedup compared to AR models due to a pretrain-to-posttrain mismatch. Specifically, the masked data distribution in post-training deviates significantly from the real-world data distribution seen during pretraining, and dLLMs rely on bidirectional attention, which conflicts with the causal prior learned during pretraining and hinders the integration of exact KV cache reuse. To address this, we introduce Jacobi Forcing, a progressive distillation paradigm where models are trained on their own generated parallel decoding trajectories, smoothly shifting AR models into efficient parallel decoders while preserving their pretrained causal inference property. The models trained under this paradigm, Jacobi Forcing Model, achieves 3.8x wall-clock speedup on coding and math benchmarks with minimal loss in performance. Based on Jacobi Forcing Models' trajectory characteristics, we introduce multi-block decoding with rejection recycling, which enables up to 4.5x higher token acceptance count per iteration and nearly 4.0x wall-clock speedup, effectively trading additional compute for lower inference latency. Our code is available at https://github.com/hao-ai-lab/JacobiForcing.
OFFSIDE: Benchmarking Unlearning Misinformation in Multimodal Large Language Models
Oct 26, 2025Advances in Multimodal Large Language Models (MLLMs) intensify concerns about data privacy, making Machine Unlearning (MU), the selective removal of learned information, a critical necessity. However, existing MU benchmarks for MLLMs are limited by a lack of image diversity, potential inaccuracies, and insufficient evaluation scenarios, which fail to capture the complexity of real-world applications. To facilitate the development of MLLMs unlearning and alleviate the aforementioned limitations, we introduce OFFSIDE, a novel benchmark for evaluating misinformation unlearning in MLLMs based on football transfer rumors. This manually curated dataset contains 15.68K records for 80 players, providing a comprehensive framework with four test sets to assess forgetting efficacy, generalization, utility, and robustness. OFFSIDE supports advanced settings like selective unlearning and corrective relearning, and crucially, unimodal unlearning (forgetting only text data). Our extensive evaluation of multiple baselines reveals key findings: (1) Unimodal methods (erasing text-based knowledge) fail on multimodal rumors; (2) Unlearning efficacy is largely driven by catastrophic forgetting; (3) All methods struggle with "visual rumors" (rumors appear in the image); (4) The unlearned rumors can be easily recovered and (5) All methods are vulnerable to prompt attacks. These results expose significant vulnerabilities in current approaches, highlighting the need for more robust multimodal unlearning solutions. The code is available at \href{https://github.com/zh121800/OFFSIDE}{https://github.com/zh121800/OFFSIDE}.
Label Smoothing Improves Gradient Ascent in LLM Unlearning
Oct 25, 2025LLM unlearning has emerged as a promising approach, aiming to enable models to forget hazardous/undesired knowledge at low cost while preserving as much model utility as possible. Among existing techniques, the most straightforward method is performing Gradient Ascent (GA) w.r.t. the forget data, thereby forcing the model to unlearn the forget dataset. However, GA suffers from severe instability, as it drives updates in a divergent direction, often resulting in drastically degraded model utility. To address this issue, we propose Smoothed Gradient Ascent (SGA). SGA combines the forget data with multiple constructed normal data through a tunable smoothing rate. Intuitively, this extends GA from learning solely on the forget data to jointly learning across both forget and normal data, enabling more stable unlearning while better preserving model utility. Theoretically, we provide the theoretical guidance on the selection of the optimal smoothing rate. Empirically, we evaluate SGA on three benchmarks: TOFU, Harry Potter, and MUSE-NEWS. Experimental results demonstrate that SGA consistently outperforms the original Gradient Ascent (GA) method across all metrics and achieves top-2 performance among all baseline methods on several key metrics.
LM-mixup: Text Data Augmentation via Language Model based Mixup
Oct 23, 2025Instruction tuning is crucial for aligning Large Language Models (LLMs), yet the quality of instruction-following data varies significantly. While high-quality data is paramount, it is often scarce; conversely, abundant low-quality data is frequently discarded, leading to substantial information loss. Existing data augmentation methods struggle to augment this low-quality data effectively, and the evaluation of such techniques remains poorly defined. To address this, we formally define the task of Instruction Distillation: distilling multiple low-quality and redundant inputs into high-quality and coherent instruction-output pairs. Specifically, we introduce a comprehensive data construction pipeline to create MIXTURE, a 144K-sample dataset pairing low-quality or semantically redundant imperfect instruction clusters with their high-quality distillations. We then introduce LM-Mixup, by first performing supervised fine-tuning on MIXTURE and then optimizing it with reinforcement learning. This process uses three complementary reward signals: quality, semantic alignment, and format compliance, via Group Relative Policy Optimization (GRPO). We demonstrate that LM-Mixup effectively augments imperfect datasets: fine-tuning LLMs on its distilled data, which accounts for only about 3% of the entire dataset, not only surpasses full-dataset training but also competes with state-of-the-art high-quality data selection methods across multiple benchmarks. Our work establishes that low-quality data is a valuable resource when properly distilled and augmented with LM-Mixup, significantly enhancing the efficiency and performance of instruction-tuned LLMs.