 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenWorldLib: A Unified Codebase and Definition of Advanced World Models
Apr 06, 2026World models have garnered significant attention as a promising research direction in artificial intelligence, yet a clear and unified definition remains lacking. In this paper, we introduce OpenWorldLib, a comprehensive and standardized inference framework for Advanced World Models. Drawing on the evolution of world models, we propose a clear definition: a world model is a model or framework centered on perception, equipped with interaction and long-term memory capabilities, for understanding and predicting the complex world. We further systematically categorize the essential capabilities of world models. Based on this definition, OpenWorldLib integrates models across different tasks within a unified framework, enabling efficient reuse and collaborative inference. Finally, we present additional reflections and analyses on potential future directions for world model research. Code link: https://github.com/OpenDCAI/OpenWorldLib
MedScope: Incentivizing "Think with Videos" for Clinical Reasoning via Coarse-to-Fine Tool Calling
Feb 11, 2026Long-form clinical videos are central to visual evidence-based decision-making, with growing importance for applications such as surgical robotics and related settings. However, current multimodal large language models typically process videos with passive sampling or weakly grounded inspection, which limits their ability to iteratively locate, verify, and justify predictions with temporally targeted evidence. To close this gap, we propose MedScope, a tool-using clinical video reasoning model that performs coarse-to-fine evidence seeking over long-form procedures. By interleaving intermediate reasoning with targeted tool calls and verification on retrieved observations, MedScope produces more accurate and trustworthy predictions that are explicitly grounded in temporally localized visual evidence. To address the lack of high-fidelity supervision, we build ClinVideoSuite, an evidence-centric, fine-grained clinical video suite. We then optimize MedScope with Grounding-Aware Group Relative Policy Optimization (GA-GRPO), which directly reinforces tool use with grounding-aligned rewards and evidence-weighted advantages. On full and fine-grained video understanding benchmarks, MedScope achieves state-of-the-art performance in both in-domain and out-of-domain evaluations. Our approach illuminates a path toward medical AI agents that can genuinely "think with videos" through tool-integrated reasoning. We will release our code, models, and data.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Research on World Models Is Not Merely Injecting World Knowledge into Specific Tasks
Feb 02, 2026World models have emerged as a critical frontier in AI research, aiming to enhance large models by infusing them with physical dynamics and world knowledge. The core objective is to enable agents to understand, predict, and interact with complex environments. However, current research landscape remains fragmented, with approaches predominantly focused on injecting world knowledge into isolated tasks, such as visual prediction, 3D estimation, or symbol grounding, rather than establishing a unified definition or framework. While these task-specific integrations yield performance gains, they often lack the systematic coherence required for holistic world understanding. In this paper, we analyze the limitations of such fragmented approaches and propose a unified design specification for world models. We suggest that a robust world model should not be a loose collection of capabilities but a normative framework that integrally incorporates interaction, perception, symbolic reasoning, and spatial representation. This work aims to provide a structured perspective to guide future research toward more general, robust, and principled models of the world.
How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use
Jan 31, 2026As Large Language Models (LLMs) are increasingly applied in high-stakes domains, their ability to reason strategically under uncertainty becomes critical. Poker provides a rigorous testbed, requiring not only strong actions but also principled, game-theoretic reasoning. In this paper, we conduct a systematic study of LLMs in multiple realistic poker tasks, evaluating both gameplay outcomes and reasoning traces. Our analysis reveals LLMs fail to compete against traditional algorithms and identifies three recurring flaws: reliance on heuristics, factual misunderstandings, and a "knowing-doing" gap where actions diverge from reasoning. An initial attempt with behavior cloning and step-level reinforcement learning improves reasoning style but remains insufficient for accurate game-theoretic play. Motivated by these limitations, we propose ToolPoker, a tool-integrated reasoning framework that combines external solvers for GTO-consistent actions with more precise professional-style explanations. Experiments demonstrate that ToolPoker achieves state-of-the-art gameplay while producing reasoning traces that closely reflect game-theoretic principles.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
Representation Entanglement for Generation:Training Diffusion Transformers Is Much Easier Than You Think
Jul 02, 2025
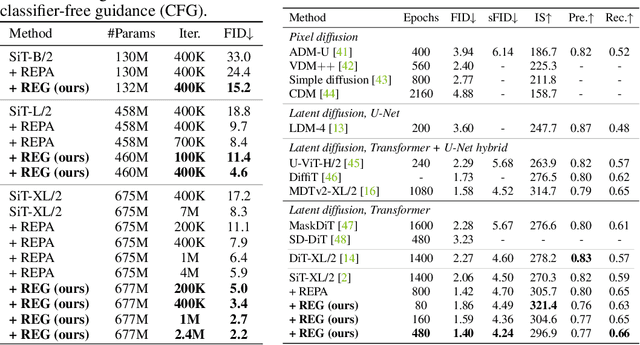
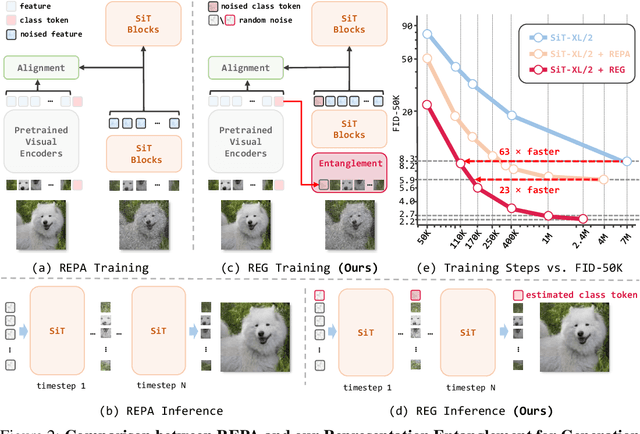
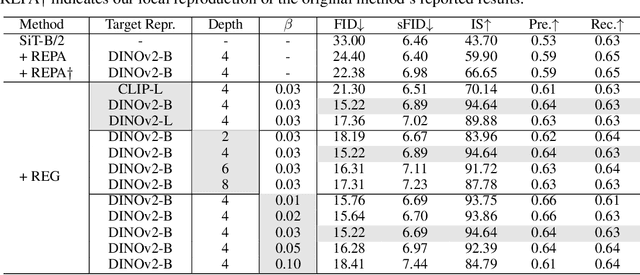
REPA and its variants effectively mitigate training challenges in diffusion models by incorporating external visual representations from pretrained models, through alignment between the noisy hidden projections of denoising networks and foundational clean image representations. We argue that the external alignment, which is absent during the entire denoising inference process, falls short of fully harnessing the potential of discriminative representations. In this work, we propose a straightforward method called Representation Entanglement for Generation (REG), which entangles low-level image latents with a single high-level class token from pretrained foundation models for denoising. REG acquires the capability to produce coherent image-class pairs directly from pure noise, substantially improving both generation quality and training efficiency. This is accomplished with negligible additional inference overhead, requiring only one single additional token for denoising (<0.5\% increase in FLOPs and latency). The inference process concurrently reconstructs both image latents and their corresponding global semantics, where the acquired semantic knowledge actively guides and enhances the image generation process. On ImageNet 256$\times$256, SiT-XL/2 + REG demonstrates remarkable convergence acceleration, achieving $\textbf{63}\times$ and $\textbf{23}\times$ faster training than SiT-XL/2 and SiT-XL/2 + REPA, respectively. More impressively, SiT-L/2 + REG trained for merely 400K iterations outperforms SiT-XL/2 + REPA trained for 4M iterations ($\textbf{10}\times$ longer). Code is available at: https://github.com/Martinser/REG.
G1: Bootstrapping Perception and Reasoning Abilities of Vision-Language Model via Reinforcement Learning
May 19, 2025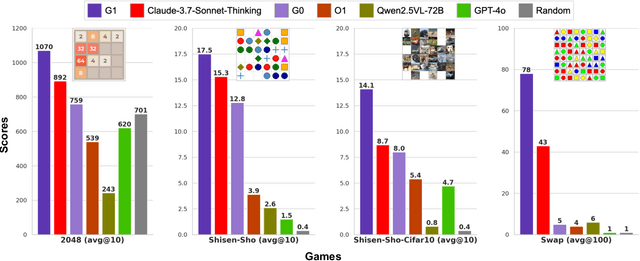
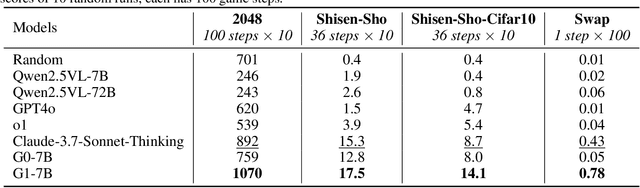
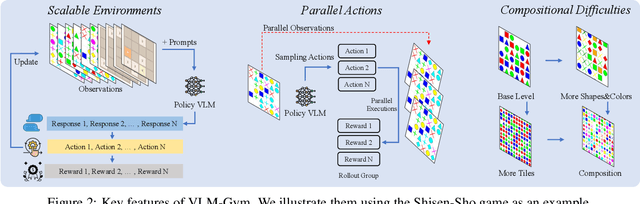
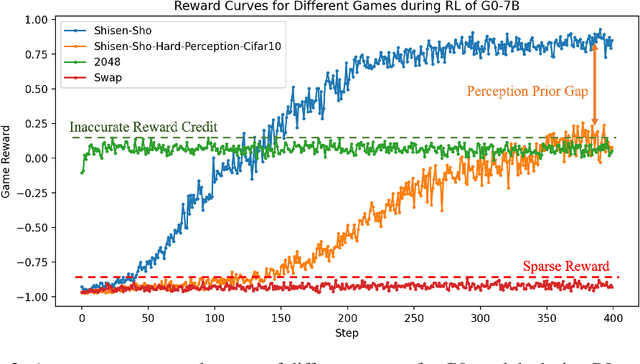
Vision-Language Models (VLMs) excel in many direct multimodal tasks but struggle to translate this prowess into effective decision-making within interactive, visually rich environments like games. This ``knowing-doing'' gap significantly limits their potential as autonomous agents, as leading VLMs often performing badly in simple games. To address this, we introduce VLM-Gym, a curated reinforcement learning (RL) environment featuring diverse visual games with unified interfaces and adjustable, compositional difficulty, specifically designed for scalable multi-game parallel training. Leveraging VLM-Gym, we train G0 models using pure RL-driven self-evolution, which demonstrate emergent perception and reasoning patterns. To further mitigate challenges arising from game diversity, we develop G1 models. G1 incorporates a perception-enhanced cold start prior to RL fine-tuning. Our resulting G1 models consistently surpass their teacher across all games and outperform leading proprietary models like Claude-3.7-Sonnet-Thinking. Systematic analysis reveals an intriguing finding: perception and reasoning abilities mutually bootstrap each other throughout the RL training process. Source code including VLM-Gym and RL training are released at https://github.com/chenllliang/G1 to foster future research in advancing VLMs as capable interactive agents.
GuardReasoner-VL: Safeguarding VLMs via Reinforced Reasoning
May 16, 2025To enhance the safety of VLMs, this paper introduces a novel reasoning-based VLM guard model dubbed GuardReasoner-VL. The core idea is to incentivize the guard model to deliberatively reason before making moderation decisions via online RL. First, we construct GuardReasoner-VLTrain, a reasoning corpus with 123K samples and 631K reasoning steps, spanning text, image, and text-image inputs. Then, based on it, we cold-start our model's reasoning ability via SFT. In addition, we further enhance reasoning regarding moderation through online RL. Concretely, to enhance diversity and difficulty of samples, we conduct rejection sampling followed by data augmentation via the proposed safety-aware data concatenation. Besides, we use a dynamic clipping parameter to encourage exploration in early stages and exploitation in later stages. To balance performance and token efficiency, we design a length-aware safety reward that integrates accuracy, format, and token cost. Extensive experiments demonstrate the superiority of our model. Remarkably, it surpasses the runner-up by 19.27% F1 score on average. We release data, code, and models (3B/7B) of GuardReasoner-VL at https://github.com/yueliu1999/GuardReasoner-VL/
FlowReasoner: Reinforcing Query-Level Meta-Agents
Apr 21, 2025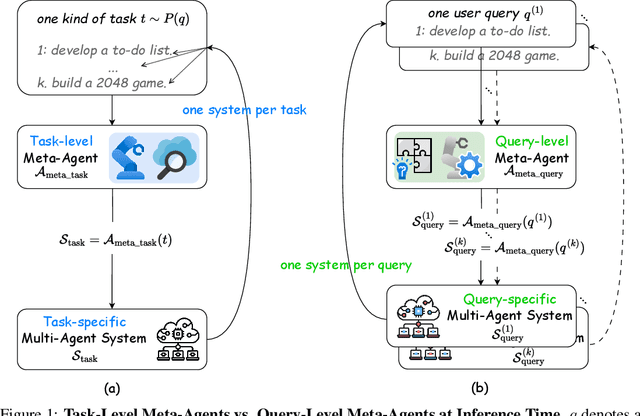
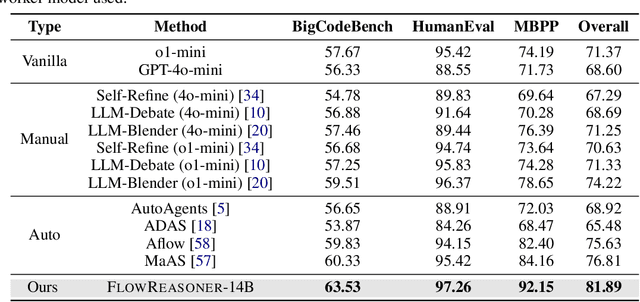
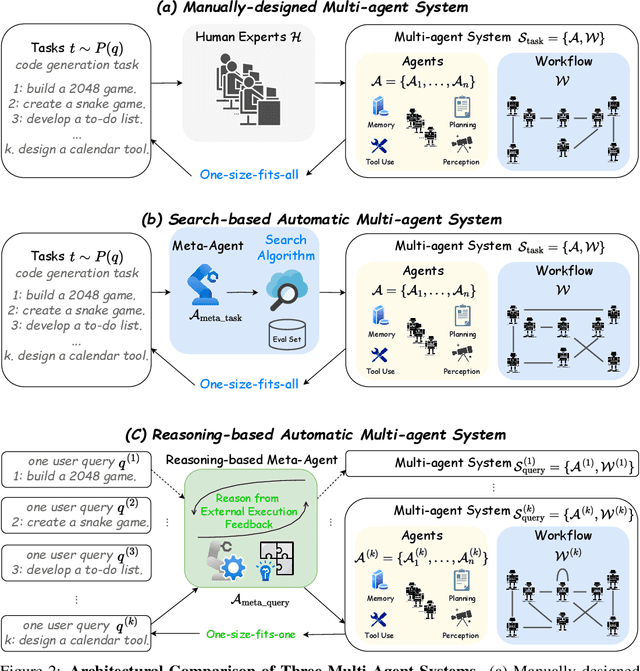
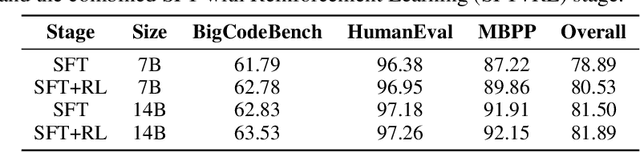
This paper proposes a query-level meta-agent named FlowReasoner to automate the design of query-level multi-agent systems, i.e., one system per user query. Our core idea is to incentivize a reasoning-based meta-agent via external execution feedback. Concretely, by distilling DeepSeek R1, we first endow the basic reasoning ability regarding the generation of multi-agent systems to FlowReasoner. Then, we further enhance it via reinforcement learning (RL) with external execution feedback. A multi-purpose reward is designed to guide the RL training from aspects of performance, complexity, and efficiency. In this manner, FlowReasoner is enabled to generate a personalized multi-agent system for each user query via deliberative reasoning. Experiments on both engineering and competition code benchmarks demonstrate the superiority of FlowReasoner. Remarkably, it surpasses o1-mini by 10.52% accuracy across three benchmarks. The code is available at https://github.com/sail-sg/FlowReasoner.