 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Residuals
Mar 16, 2026Residual connections with PreNorm are standard in modern LLMs, yet they accumulate all layer outputs with fixed unit weights. This uniform aggregation causes uncontrolled hidden-state growth with depth, progressively diluting each layer's contribution. We propose Attention Residuals (AttnRes), which replaces this fixed accumulation with softmax attention over preceding layer outputs, allowing each layer to selectively aggregate earlier representations with learned, input-dependent weights. To address the memory and communication overhead of attending over all preceding layer outputs for large-scale model training, we introduce Block AttnRes, which partitions layers into blocks and attends over block-level representations, reducing the memory footprint while preserving most of the gains of full AttnRes. Combined with cache-based pipeline communication and a two-phase computation strategy, Block AttnRes becomes a practical drop-in replacement for standard residual connections with minimal overhead. Scaling law experiments confirm that the improvement is consistent across model sizes, and ablations validate the benefit of content-dependent depth-wise selection. We further integrate AttnRes into the Kimi Linear architecture (48B total / 3B activated parameters) and pre-train on 1.4T tokens, where AttnRes mitigates PreNorm dilution, yielding more uniform output magnitudes and gradient distribution across depth, and improves downstream performance across all evaluated tasks.
Open Rubric System: Scaling Reinforcement Learning with Pairwise Adaptive Rubric
Feb 15, 2026Scalar reward models compress multi-dimensional human preferences into a single opaque score, creating an information bottleneck that often leads to brittleness and reward hacking in open-ended alignment. We argue that robust alignment for non-verifiable tasks is fundamentally a principle generalization problem: reward should not be a learned function internalized into a judge, but an explicit reasoning process executed under inspectable principles. To operationalize this view, we present the Open Rubric System (OpenRS), a plug-and-play, rubrics-based LLM-as-a-Judge framework built around Pairwise Adaptive Meta-Rubrics (PAMR) and lightweight Pointwise Verifiable Rubrics (PVRs), which provide both hard-constraint guardrails and verifiable reward components when ground-truth or programmatic checks are available. OpenRS uses an explicit meta-rubric -- a constitution-like specification that governs how rubrics are instantiated, weighted, and enforced -- and instantiates adaptive rubrics on the fly by conditioning on the semantic differences between two candidate responses. It then performs criterion-wise pairwise comparisons and aggregates criterion-level preferences externally, avoiding pointwise weighted scalarization while improving discriminability in open-ended settings. To keep principles consistent yet editable across various domains, we introduce a two-level meta-rubric refinement pipeline (automated evolutionary refinement for general principles and a reproducible human-in-the-loop procedure for domain principles), complemented with pointwise verifiable rubrics that act as both guardrails against degenerate behaviors and a source of verifiable reward for objective sub-tasks. Finally, we instantiate OpenRS as reward supervision in pairwise RL training.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Surrogate Ensemble in Expensive Multi-Objective Optimization via Deep Q-Learning
Jan 31, 2026Surrogate-assisted Evolutionary Algorithms~(SAEAs) have shown promising robustness in solving expensive optimization problems. A key aspect that impacts SAEAs' effectiveness is surrogate model selection, which in existing works is predominantly decided by human developer. Such human-made design choice introduces strong bias into SAEAs and may hurt their expected performance on out-of-scope tasks. In this paper, we propose a reinforcement learning-assisted ensemble framework, termed as SEEMOO, which is capable of scheduling different surrogate models within a single optimization process, hence boosting the overall optimization performance in a cooperative paradigm. Specifically, we focus on expensive multi-objective optimization problems, where multiple objective functions shape a compositional landscape and hence challenge surrogate selection. SEEMOO comprises following core designs: 1) A pre-collected model pool that maintains different surrogate models; 2) An attention-based state-extractor supports universal optimization state representation of problems with varied objective numbers; 3) a deep Q-network serves as dynamic surrogate selector: Given the optimization state, it selects desired surrogate model for current-step evaluation. SEEMOO is trained to maximize the overall optimization performance under a training problem distribution. Extensive benchmark results demonstrate SEEMOO's surrogate ensemble paradigm boosts the optimization performance of single-surrogate baselines. Further ablation studies underscore the importance of SEEMOO's design components.
Kimi Linear: An Expressive, Efficient Attention Architecture
Oct 30, 2025We introduce Kimi Linear, a hybrid linear attention architecture that, for the first time, outperforms full attention under fair comparisons across various scenarios -- including short-context, long-context, and reinforcement learning (RL) scaling regimes. At its core lies Kimi Delta Attention (KDA), an expressive linear attention module that extends Gated DeltaNet with a finer-grained gating mechanism, enabling more effective use of limited finite-state RNN memory. Our bespoke chunkwise algorithm achieves high hardware efficiency through a specialized variant of the Diagonal-Plus-Low-Rank (DPLR) transition matrices, which substantially reduces computation compared to the general DPLR formulation while remaining more consistent with the classical delta rule. We pretrain a Kimi Linear model with 3B activated parameters and 48B total parameters, based on a layerwise hybrid of KDA and Multi-Head Latent Attention (MLA). Our experiments show that with an identical training recipe, Kimi Linear outperforms full MLA with a sizeable margin across all evaluated tasks, while reducing KV cache usage by up to 75% and achieving up to 6 times decoding throughput for a 1M context. These results demonstrate that Kimi Linear can be a drop-in replacement for full attention architectures with superior performance and efficiency, including tasks with longer input and output lengths. To support further research, we open-source the KDA kernel and vLLM implementations, and release the pre-trained and instruction-tuned model checkpoints.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
G1: Bootstrapping Perception and Reasoning Abilities of Vision-Language Model via Reinforcement Learning
May 19, 2025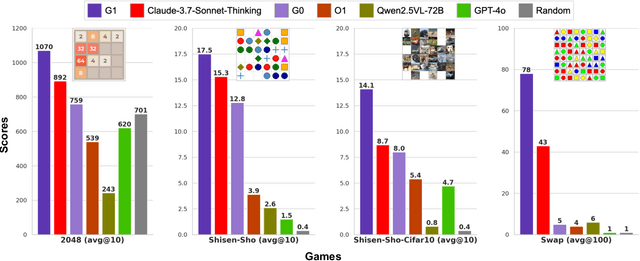
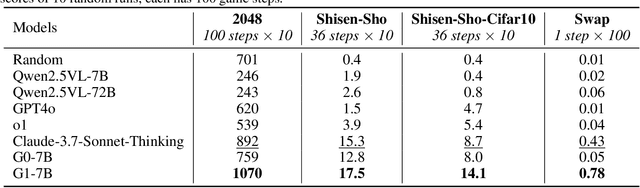
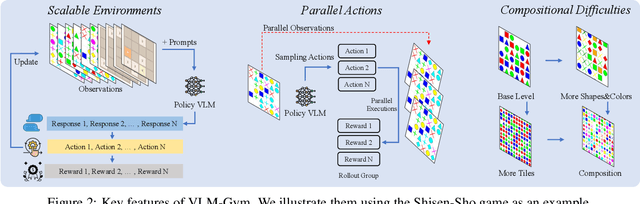
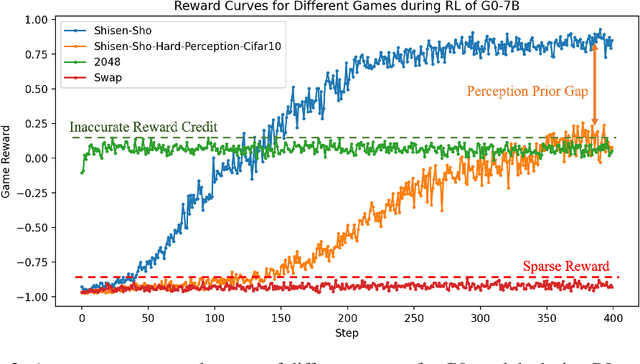
Vision-Language Models (VLMs) excel in many direct multimodal tasks but struggle to translate this prowess into effective decision-making within interactive, visually rich environments like games. This ``knowing-doing'' gap significantly limits their potential as autonomous agents, as leading VLMs often performing badly in simple games. To address this, we introduce VLM-Gym, a curated reinforcement learning (RL) environment featuring diverse visual games with unified interfaces and adjustable, compositional difficulty, specifically designed for scalable multi-game parallel training. Leveraging VLM-Gym, we train G0 models using pure RL-driven self-evolution, which demonstrate emergent perception and reasoning patterns. To further mitigate challenges arising from game diversity, we develop G1 models. G1 incorporates a perception-enhanced cold start prior to RL fine-tuning. Our resulting G1 models consistently surpass their teacher across all games and outperform leading proprietary models like Claude-3.7-Sonnet-Thinking. Systematic analysis reveals an intriguing finding: perception and reasoning abilities mutually bootstrap each other throughout the RL training process. Source code including VLM-Gym and RL training are released at https://github.com/chenllliang/G1 to foster future research in advancing VLMs as capable interactive agents.
Kimi-Audio Technical Report
Apr 25, 2025



We present Kimi-Audio, an open-source audio foundation model that excels in audio understanding, generation, and conversation. We detail the practices in building Kimi-Audio, including model architecture, data curation, training recipe, inference deployment, and evaluation. Specifically, we leverage a 12.5Hz audio tokenizer, design a novel LLM-based architecture with continuous features as input and discrete tokens as output, and develop a chunk-wise streaming detokenizer based on flow matching. We curate a pre-training dataset that consists of more than 13 million hours of audio data covering a wide range of modalities including speech, sound, and music, and build a pipeline to construct high-quality and diverse post-training data. Initialized from a pre-trained LLM, Kimi-Audio is continual pre-trained on both audio and text data with several carefully designed tasks, and then fine-tuned to support a diverse of audio-related tasks. Extensive evaluation shows that Kimi-Audio achieves state-of-the-art performance on a range of audio benchmarks including speech recognition, audio understanding, audio question answering, and speech conversation. We release the codes, model checkpoints, as well as the evaluation toolkits in https://github.com/MoonshotAI/Kimi-Audio.
Kimi-VL Technical Report
Apr 10, 2025



We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities - all while activating only 2.8B parameters in its language decoder (Kimi-VL-A3B). Kimi-VL demonstrates strong performance across challenging domains: as a general-purpose VLM, Kimi-VL excels in multi-turn agent tasks (e.g., OSWorld), matching flagship models. Furthermore, it exhibits remarkable capabilities across diverse challenging vision language tasks, including college-level image and video comprehension, OCR, mathematical reasoning, and multi-image understanding. In comparative evaluations, it effectively competes with cutting-edge efficient VLMs such as GPT-4o-mini, Qwen2.5-VL-7B, and Gemma-3-12B-IT, while surpassing GPT-4o in several key domains. Kimi-VL also advances in processing long contexts and perceiving clearly. With a 128K extended context window, Kimi-VL can process diverse long inputs, achieving impressive scores of 64.5 on LongVideoBench and 35.1 on MMLongBench-Doc. Its native-resolution vision encoder, MoonViT, further allows it to see and understand ultra-high-resolution visual inputs, achieving 83.2 on InfoVQA and 34.5 on ScreenSpot-Pro, while maintaining lower computational cost for common tasks. Building upon Kimi-VL, we introduce an advanced long-thinking variant: Kimi-VL-Thinking. Developed through long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL), this model exhibits strong long-horizon reasoning capabilities. It achieves scores of 61.7 on MMMU, 36.8 on MathVision, and 71.3 on MathVista while maintaining the compact 2.8B activated LLM parameters, setting a new standard for efficient multimodal thinking models. Code and models are publicly accessible at https://github.com/MoonshotAI/Kimi-VL.
Muon is Scalable for LLM Training
Feb 24, 2025Recently, the Muon optimizer based on matrix orthogonalization has demonstrated strong results in training small-scale language models, but the scalability to larger models has not been proven. We identify two crucial techniques for scaling up Muon: (1) adding weight decay and (2) carefully adjusting the per-parameter update scale. These techniques allow Muon to work out-of-the-box on large-scale training without the need of hyper-parameter tuning. Scaling law experiments indicate that Muon achieves $\sim\!2\times$ computational efficiency compared to AdamW with compute optimal training. Based on these improvements, we introduce Moonlight, a 3B/16B-parameter Mixture-of-Expert (MoE) model trained with 5.7T tokens using Muon. Our model improves the current Pareto frontier, achieving better performance with much fewer training FLOPs compared to prior models. We open-source our distributed Muon implementation that is memory optimal and communication efficient. We also release the pretrained, instruction-tuned, and intermediate checkpoints to support future research.