 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi-Audio Technical Report
Apr 25, 2025



We present Kimi-Audio, an open-source audio foundation model that excels in audio understanding, generation, and conversation. We detail the practices in building Kimi-Audio, including model architecture, data curation, training recipe, inference deployment, and evaluation. Specifically, we leverage a 12.5Hz audio tokenizer, design a novel LLM-based architecture with continuous features as input and discrete tokens as output, and develop a chunk-wise streaming detokenizer based on flow matching. We curate a pre-training dataset that consists of more than 13 million hours of audio data covering a wide range of modalities including speech, sound, and music, and build a pipeline to construct high-quality and diverse post-training data. Initialized from a pre-trained LLM, Kimi-Audio is continual pre-trained on both audio and text data with several carefully designed tasks, and then fine-tuned to support a diverse of audio-related tasks. Extensive evaluation shows that Kimi-Audio achieves state-of-the-art performance on a range of audio benchmarks including speech recognition, audio understanding, audio question answering, and speech conversation. We release the codes, model checkpoints, as well as the evaluation toolkits in https://github.com/MoonshotAI/Kimi-Audio.
MoonCast: High-Quality Zero-Shot Podcast Generation
Mar 19, 2025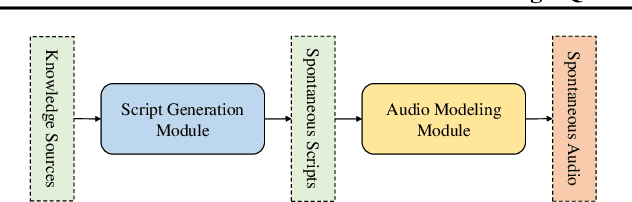

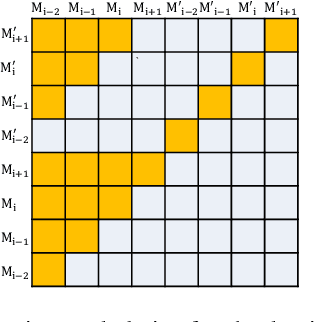

Recent advances in text-to-speech synthesis have achieved notable success in generating high-quality short utterances for individual speakers. However, these systems still face challenges when extending their capabilities to long, multi-speaker, and spontaneous dialogues, typical of real-world scenarios such as podcasts. These limitations arise from two primary challenges: 1) long speech: podcasts typically span several minutes, exceeding the upper limit of most existing work; 2) spontaneity: podcasts are marked by their spontaneous, oral nature, which sharply contrasts with formal, written contexts; existing works often fall short in capturing this spontaneity. In this paper, we propose MoonCast, a solution for high-quality zero-shot podcast generation, aiming to synthesize natural podcast-style speech from text-only sources (e.g., stories, technical reports, news in TXT, PDF, or Web URL formats) using the voices of unseen speakers. To generate long audio, we adopt a long-context language model-based audio modeling approach utilizing large-scale long-context speech data. To enhance spontaneity, we utilize a podcast generation module to generate scripts with spontaneous details, which have been empirically shown to be as crucial as the text-to-speech modeling itself. Experiments demonstrate that MoonCast outperforms baselines, with particularly notable improvements in spontaneity and coherence.
FlashSpeech: Efficient Zero-Shot Speech Synthesis
Apr 25, 2024



Recent progress in large-scale zero-shot speech synthesis has been significantly advanced by language models and diffusion models. However, the generation process of both methods is slow and computationally intensive. Efficient speech synthesis using a lower computing budget to achieve quality on par with previous work remains a significant challenge. In this paper, we present FlashSpeech, a large-scale zero-shot speech synthesis system with approximately 5\% of the inference time compared with previous work. FlashSpeech is built on the latent consistency model and applies a novel adversarial consistency training approach that can train from scratch without the need for a pre-trained diffusion model as the teacher. Furthermore, a new prosody generator module enhances the diversity of prosody, making the rhythm of the speech sound more natural. The generation processes of FlashSpeech can be achieved efficiently with one or two sampling steps while maintaining high audio quality and high similarity to the audio prompt for zero-shot speech generation. Our experimental results demonstrate the superior performance of FlashSpeech. Notably, FlashSpeech can be about 20 times faster than other zero-shot speech synthesis systems while maintaining comparable performance in terms of voice quality and similarity. Furthermore, FlashSpeech demonstrates its versatility by efficiently performing tasks like voice conversion, speech editing, and diverse speech sampling. Audio samples can be found in https://flashspeech.github.io/.
RALL-E: Robust Codec Language Modeling with Chain-of-Thought Prompting for Text-to-Speech Synthesis
Apr 06, 2024



We present RALL-E, a robust language modeling method for text-to-speech (TTS) synthesis. While previous work based on large language models (LLMs) shows impressive performance on zero-shot TTS, such methods often suffer from poor robustness, such as unstable prosody (weird pitch and rhythm/duration) and a high word error rate (WER), due to the autoregressive prediction style of language models. The core idea behind RALL-E is chain-of-thought (CoT) prompting, which decomposes the task into simpler steps to enhance the robustness of LLM-based TTS. To accomplish this idea, RALL-E first predicts prosody features (pitch and duration) of the input text and uses them as intermediate conditions to predict speech tokens in a CoT style. Second, RALL-E utilizes the predicted duration prompt to guide the computing of self-attention weights in Transformer to enforce the model to focus on the corresponding phonemes and prosody features when predicting speech tokens. Results of comprehensive objective and subjective evaluations demonstrate that, compared to a powerful baseline method VALL-E, RALL-E significantly improves the WER of zero-shot TTS from $6.3\%$ (without reranking) and $2.1\%$ (with reranking) to $2.8\%$ and $1.0\%$, respectively. Furthermore, we demonstrate that RALL-E correctly synthesizes sentences that are hard for VALL-E and reduces the error rate from $68\%$ to $4\%$.
NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models
Mar 05, 2024While recent large-scale text-to-speech (TTS) models have achieved significant progress, they still fall short in speech quality, similarity, and prosody. Considering speech intricately encompasses various attributes (e.g., content, prosody, timbre, and acoustic details) that pose significant challenges for generation, a natural idea is to factorize speech into individual subspaces representing different attributes and generate them individually. Motivated by it, we propose NaturalSpeech 3, a TTS system with novel factorized diffusion models to generate natural speech in a zero-shot way. Specifically, 1) we design a neural codec with factorized vector quantization (FVQ) to disentangle speech waveform into subspaces of content, prosody, timbre, and acoustic details; 2) we propose a factorized diffusion model to generate attributes in each subspace following its corresponding prompt. With this factorization design, NaturalSpeech 3 can effectively and efficiently model the intricate speech with disentangled subspaces in a divide-and-conquer way. Experiments show that NaturalSpeech 3 outperforms the state-of-the-art TTS systems on quality, similarity, prosody, and intelligibility. Furthermore, we achieve better performance by scaling to 1B parameters and 200K hours of training data.
PromptTTS 2: Describing and Generating Voices with Text Prompt
Sep 05, 2023



Speech conveys more information than just text, as the same word can be uttered in various voices to convey diverse information. Compared to traditional text-to-speech (TTS) methods relying on speech prompts (reference speech) for voice variability, using text prompts (descriptions) is more user-friendly since speech prompts can be hard to find or may not exist at all. TTS approaches based on the text prompt face two challenges: 1) the one-to-many problem, where not all details about voice variability can be described in the text prompt, and 2) the limited availability of text prompt datasets, where vendors and large cost of data labeling are required to write text prompt for speech. In this work, we introduce PromptTTS 2 to address these challenges with a variation network to provide variability information of voice not captured by text prompts, and a prompt generation pipeline to utilize the large language models (LLM) to compose high quality text prompts. Specifically, the variation network predicts the representation extracted from the reference speech (which contains full information about voice) based on the text prompt representation. For the prompt generation pipeline, it generates text prompts for speech with a speech understanding model to recognize voice attributes (e.g., gender, speed) from speech and a large language model to formulate text prompt based on the recognition results. Experiments on a large-scale (44K hours) speech dataset demonstrate that compared to the previous works, PromptTTS 2 generates voices more consistent with text prompts and supports the sampling of diverse voice variability, thereby offering users more choices on voice generation. Additionally, the prompt generation pipeline produces high-quality prompts, eliminating the large labeling cost. The demo page of PromptTTS 2 is available online\footnote{https://speechresearch.github.io/prompttts2}.
NaturalSpeech 2: Latent Diffusion Models are Natural and Zero-Shot Speech and Singing Synthesizers
May 04, 2023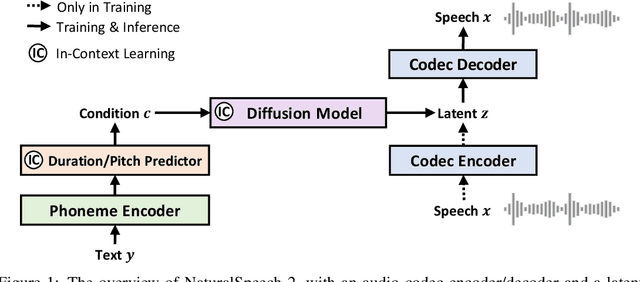


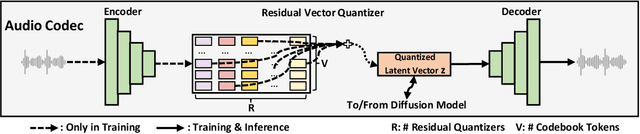
Scaling text-to-speech (TTS) to large-scale, multi-speaker, and in-the-wild datasets is important to capture the diversity in human speech such as speaker identities, prosodies, and styles (e.g., singing). Current large TTS systems usually quantize speech into discrete tokens and use language models to generate these tokens one by one, which suffer from unstable prosody, word skipping/repeating issue, and poor voice quality. In this paper, we develop NaturalSpeech 2, a TTS system that leverages a neural audio codec with residual vector quantizers to get the quantized latent vectors and uses a diffusion model to generate these latent vectors conditioned on text input. To enhance the zero-shot capability that is important to achieve diverse speech synthesis, we design a speech prompting mechanism to facilitate in-context learning in the diffusion model and the duration/pitch predictor. We scale NaturalSpeech 2 to large-scale datasets with 44K hours of speech and singing data and evaluate its voice quality on unseen speakers. NaturalSpeech 2 outperforms previous TTS systems by a large margin in terms of prosody/timbre similarity, robustness, and voice quality in a zero-shot setting, and performs novel zero-shot singing synthesis with only a speech prompt. Audio samples are available at https://speechresearch.github.io/naturalspeech2.
AUDIT: Audio Editing by Following Instructions with Latent Diffusion Models
Apr 05, 2023Audio editing is applicable for various purposes, such as adding background sound effects, replacing a musical instrument, and repairing damaged audio. Recently, some diffusion-based methods achieved zero-shot audio editing by using a diffusion and denoising process conditioned on the text description of the output audio. However, these methods still have some problems: 1) they have not been trained on editing tasks and cannot ensure good editing effects; 2) they can erroneously modify audio segments that do not require editing; 3) they need a complete description of the output audio, which is not always available or necessary in practical scenarios. In this work, we propose AUDIT, an instruction-guided audio editing model based on latent diffusion models. Specifically, AUDIT has three main design features: 1) we construct triplet training data (instruction, input audio, output audio) for different audio editing tasks and train a diffusion model using instruction and input (to be edited) audio as conditions and generating output (edited) audio; 2) it can automatically learn to only modify segments that need to be edited by comparing the difference between the input and output audio; 3) it only needs edit instructions instead of full target audio descriptions as text input. AUDIT achieves state-of-the-art results in both objective and subjective metrics for several audio editing tasks (e.g., adding, dropping, replacement, inpainting, super-resolution). Demo samples are available at https://audit-demo.github.io/.
TeleMelody: Lyric-to-Melody Generation with a Template-Based Two-Stage Method
Sep 20, 2021
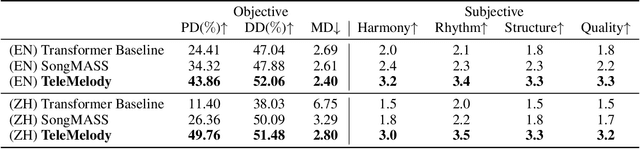
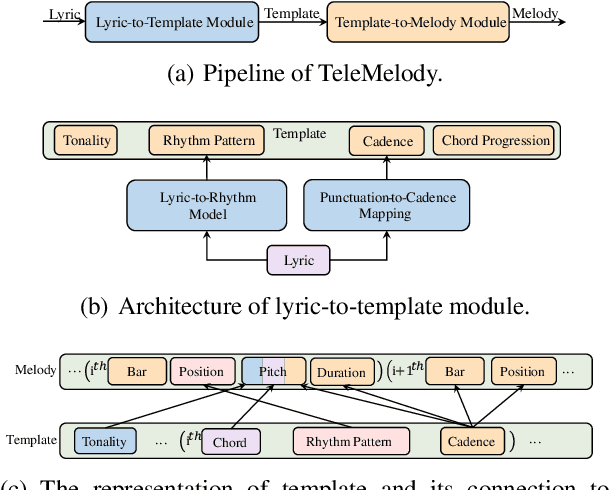
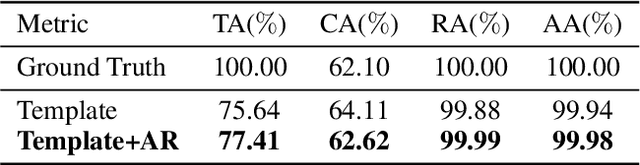
Lyric-to-melody generation is an important task in automatic songwriting. Previous lyric-to-melody generation systems usually adopt end-to-end models that directly generate melodies from lyrics, which suffer from several issues: 1) lack of paired lyric-melody training data; 2) lack of control on generated melodies. In this paper, we develop TeleMelody, a two-stage lyric-to-melody generation system with music template (e.g., tonality, chord progression, rhythm pattern, and cadence) to bridge the gap between lyrics and melodies (i.e., the system consists of a lyric-to-template module and a template-to-melody module). TeleMelody has two advantages. First, it is data efficient. The template-to-melody module is trained in a self-supervised way (i.e., the source template is extracted from the target melody) that does not need any lyric-melody paired data. The lyric-to-template module is made up of some rules and a lyric-to-rhythm model, which is trained with paired lyric-rhythm data that is easier to obtain than paired lyric-melody data. Second, it is controllable. The design of template ensures that the generated melodies can be controlled by adjusting the musical elements in template. Both subjective and objective experimental evaluations demonstrate that TeleMelody generates melodies with higher quality, better controllability, and less requirement on paired lyric-melody data than previous generation systems.
MusicBERT: Symbolic Music Understanding with Large-Scale Pre-Training
Jun 10, 2021

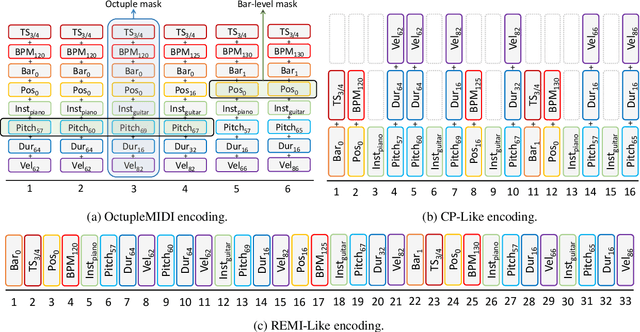

Symbolic music understanding, which refers to the understanding of music from the symbolic data (e.g., MIDI format, but not audio), covers many music applications such as genre classification, emotion classification, and music pieces matching. While good music representations are beneficial for these applications, the lack of training data hinders representation learning. Inspired by the success of pre-training models in natural language processing, in this paper, we develop MusicBERT, a large-scale pre-trained model for music understanding. To this end, we construct a large-scale symbolic music corpus that contains more than 1 million music songs. Since symbolic music contains more structural (e.g., bar, position) and diverse information (e.g., tempo, instrument, and pitch), simply adopting the pre-training techniques from NLP to symbolic music only brings marginal gains. Therefore, we design several mechanisms, including OctupleMIDI encoding and bar-level masking strategy, to enhance pre-training with symbolic music data. Experiments demonstrate the advantages of MusicBERT on four music understanding tasks, including melody completion, accompaniment suggestion, genre classification, and style classification. Ablation studies also verify the effectiveness of our designs of OctupleMIDI encoding and bar-level masking strategy in MusicBERT.