 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBigCodec: Pushing the Limits of Low-Bitrate Neural Speech Codec
Sep 09, 2024



We present BigCodec, a low-bitrate neural speech codec. While recent neural speech codecs have shown impressive progress, their performance significantly deteriorates at low bitrates (around 1 kbps). Although a low bitrate inherently restricts performance, other factors, such as model capacity, also hinder further improvements. To address this problem, we scale up the model size to 159M parameters that is more than 10 times larger than popular codecs with about 10M parameters. Besides, we integrate sequential models into traditional convolutional architectures to better capture temporal dependency and adopt low-dimensional vector quantization to ensure a high code utilization. Comprehensive objective and subjective evaluations show that BigCodec, with a bitrate of 1.04 kbps, significantly outperforms several existing low-bitrate codecs. Furthermore, BigCodec achieves objective performance comparable to popular codecs operating at 4-6 times higher bitrates, and even delivers better subjective perceptual quality than the ground truth.
RALL-E: Robust Codec Language Modeling with Chain-of-Thought Prompting for Text-to-Speech Synthesis
Apr 06, 2024



We present RALL-E, a robust language modeling method for text-to-speech (TTS) synthesis. While previous work based on large language models (LLMs) shows impressive performance on zero-shot TTS, such methods often suffer from poor robustness, such as unstable prosody (weird pitch and rhythm/duration) and a high word error rate (WER), due to the autoregressive prediction style of language models. The core idea behind RALL-E is chain-of-thought (CoT) prompting, which decomposes the task into simpler steps to enhance the robustness of LLM-based TTS. To accomplish this idea, RALL-E first predicts prosody features (pitch and duration) of the input text and uses them as intermediate conditions to predict speech tokens in a CoT style. Second, RALL-E utilizes the predicted duration prompt to guide the computing of self-attention weights in Transformer to enforce the model to focus on the corresponding phonemes and prosody features when predicting speech tokens. Results of comprehensive objective and subjective evaluations demonstrate that, compared to a powerful baseline method VALL-E, RALL-E significantly improves the WER of zero-shot TTS from $6.3\%$ (without reranking) and $2.1\%$ (with reranking) to $2.8\%$ and $1.0\%$, respectively. Furthermore, we demonstrate that RALL-E correctly synthesizes sentences that are hard for VALL-E and reduces the error rate from $68\%$ to $4\%$.
Building speech corpus with diverse voice characteristics for its prompt-based representation
Mar 20, 2024



In text-to-speech synthesis, the ability to control voice characteristics is vital for various applications. By leveraging thriving text prompt-based generation techniques, it should be possible to enhance the nuanced control of voice characteristics. While previous research has explored the prompt-based manipulation of voice characteristics, most studies have used pre-recorded speech, which limits the diversity of voice characteristics available. Thus, we aim to address this gap by creating a novel corpus and developing a model for prompt-based manipulation of voice characteristics in text-to-speech synthesis, facilitating a broader range of voice characteristics. Specifically, we propose a method to build a sizable corpus pairing voice characteristics descriptions with corresponding speech samples. This involves automatically gathering voice-related speech data from the Internet, ensuring its quality, and manually annotating it using crowdsourcing. We implement this method with Japanese language data and analyze the results to validate its effectiveness. Subsequently, we propose a construction method of the model to retrieve speech from voice characteristics descriptions based on a contrastive learning method. We train the model using not only conservative contrastive learning but also feature prediction learning to predict quantitative speech features corresponding to voice characteristics. We evaluate the model performance via experiments with the corpus we constructed above.
NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models
Mar 05, 2024While recent large-scale text-to-speech (TTS) models have achieved significant progress, they still fall short in speech quality, similarity, and prosody. Considering speech intricately encompasses various attributes (e.g., content, prosody, timbre, and acoustic details) that pose significant challenges for generation, a natural idea is to factorize speech into individual subspaces representing different attributes and generate them individually. Motivated by it, we propose NaturalSpeech 3, a TTS system with novel factorized diffusion models to generate natural speech in a zero-shot way. Specifically, 1) we design a neural codec with factorized vector quantization (FVQ) to disentangle speech waveform into subspaces of content, prosody, timbre, and acoustic details; 2) we propose a factorized diffusion model to generate attributes in each subspace following its corresponding prompt. With this factorization design, NaturalSpeech 3 can effectively and efficiently model the intricate speech with disentangled subspaces in a divide-and-conquer way. Experiments show that NaturalSpeech 3 outperforms the state-of-the-art TTS systems on quality, similarity, prosody, and intelligibility. Furthermore, we achieve better performance by scaling to 1B parameters and 200K hours of training data.
JVNV: A Corpus of Japanese Emotional Speech with Verbal Content and Nonverbal Expressions
Oct 09, 2023



We present the JVNV, a Japanese emotional speech corpus with verbal content and nonverbal vocalizations whose scripts are generated by a large-scale language model. Existing emotional speech corpora lack not only proper emotional scripts but also nonverbal vocalizations (NVs) that are essential expressions in spoken language to express emotions. We propose an automatic script generation method to produce emotional scripts by providing seed words with sentiment polarity and phrases of nonverbal vocalizations to ChatGPT using prompt engineering. We select 514 scripts with balanced phoneme coverage from the generated candidate scripts with the assistance of emotion confidence scores and language fluency scores. We demonstrate the effectiveness of JVNV by showing that JVNV has better phoneme coverage and emotion recognizability than previous Japanese emotional speech corpora. We then benchmark JVNV on emotional text-to-speech synthesis using discrete codes to represent NVs. We show that there still exists a gap between the performance of synthesizing read-aloud speech and emotional speech, and adding NVs in the speech makes the task even harder, which brings new challenges for this task and makes JVNV a valuable resource for relevant works in the future. To our best knowledge, JVNV is the first speech corpus that generates scripts automatically using large language models.
Coco-Nut: Corpus of Japanese Utterance and Voice Characteristics Description for Prompt-based Control
Sep 24, 2023



In text-to-speech, controlling voice characteristics is important in achieving various-purpose speech synthesis. Considering the success of text-conditioned generation, such as text-to-image, free-form text instruction should be useful for intuitive and complicated control of voice characteristics. A sufficiently large corpus of high-quality and diverse voice samples with corresponding free-form descriptions can advance such control research. However, neither an open corpus nor a scalable method is currently available. To this end, we develop Coco-Nut, a new corpus including diverse Japanese utterances, along with text transcriptions and free-form voice characteristics descriptions. Our methodology to construct this corpus consists of 1) automatic collection of voice-related audio data from the Internet, 2) quality assurance, and 3) manual annotation using crowdsourcing. Additionally, we benchmark our corpus on the prompt embedding model trained by contrastive speech-text learning.
How Generative Spoken Language Modeling Encodes Noisy Speech: Investigation from Phonetics to Syntactics
Jun 01, 2023



We examine the speech modeling potential of generative spoken language modeling (GSLM), which involves using learned symbols derived from data rather than phonemes for speech analysis and synthesis. Since GSLM facilitates textless spoken language processing, exploring its effectiveness is critical for paving the way for novel paradigms in spoken-language processing. This paper presents the findings of GSLM's encoding and decoding effectiveness at the spoken-language and speech levels. Through speech resynthesis experiments, we revealed that resynthesis errors occur at the levels ranging from phonology to syntactics and GSLM frequently resynthesizes natural but content-altered speech.
Laughter Synthesis using Pseudo Phonetic Tokens with a Large-scale In-the-wild Laughter Corpus
May 26, 2023



We present a large-scale in-the-wild Japanese laughter corpus and a laughter synthesis method. Previous work on laughter synthesis lacks not only data but also proper ways to represent laughter. To solve these problems, we first propose an in-the-wild corpus comprising $3.5$ hours of laughter, which is to our best knowledge the largest laughter corpus designed for laughter synthesis. We then propose pseudo phonetic tokens (PPTs) to represent laughter by a sequence of discrete tokens, which are obtained by training a clustering model on features extracted from laughter by a pretrained self-supervised model. Laughter can then be synthesized by feeding PPTs into a text-to-speech system. We further show PPTs can be used to train a language model for unconditional laughter generation. Results of comprehensive subjective and objective evaluations demonstrate that the proposed method significantly outperforms a baseline method, and can generate natural laughter unconditionally.
JNV Corpus: A Corpus of Japanese Nonverbal Vocalizations with Diverse Phrases and Emotions
May 21, 2023We present JNV (Japanese Nonverbal Vocalizations) corpus, a corpus of Japanese nonverbal vocalizations (NVs) with diverse phrases and emotions. Existing Japanese NV corpora lack phrase or emotion diversity, which makes it difficult to analyze NVs and support downstream tasks like emotion recognition. We first propose a corpus-design method that contains two phases: (1) collecting NVs phrases based on crowd-sourcing; (2) recording NVs by stimulating speakers with emotional scenarios. We then collect $420$ audio clips from $4$ speakers that cover $6$ emotions based on the proposed method. Results of comprehensive objective and subjective experiments demonstrate that the collected NVs have high emotion recognizability and authenticity that are comparable to previous corpora of English NVs. Additionally, we analyze the distributions of vowel types in Japanese NVs. To our best knowledge, JNV is currently the largest Japanese NVs corpus in terms of phrase and emotion diversities.
Duration-aware pause insertion using pre-trained language model for multi-speaker text-to-speech
Feb 27, 2023
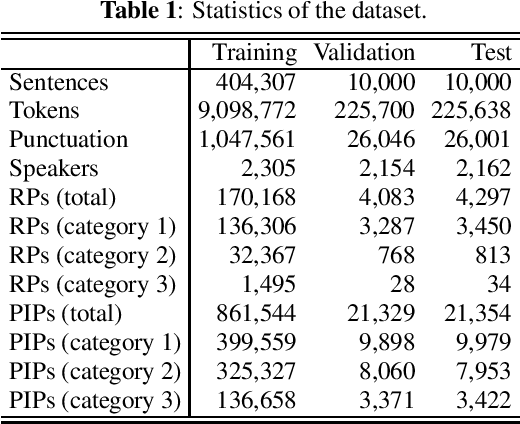
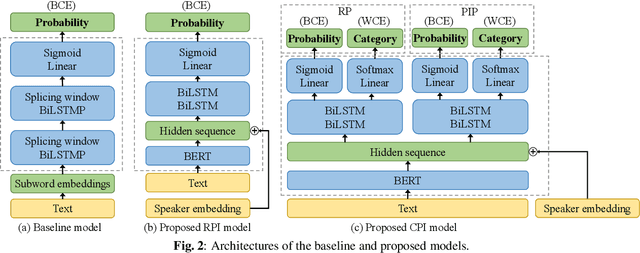
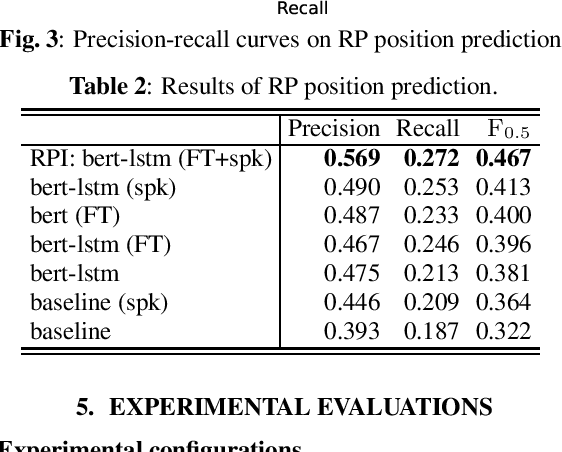
Pause insertion, also known as phrase break prediction and phrasing, is an essential part of TTS systems because proper pauses with natural duration significantly enhance the rhythm and intelligibility of synthetic speech. However, conventional phrasing models ignore various speakers' different styles of inserting silent pauses, which can degrade the performance of the model trained on a multi-speaker speech corpus. To this end, we propose more powerful pause insertion frameworks based on a pre-trained language model. Our approach uses bidirectional encoder representations from transformers (BERT) pre-trained on a large-scale text corpus, injecting speaker embedding to capture various speaker characteristics. We also leverage duration-aware pause insertion for more natural multi-speaker TTS. We develop and evaluate two types of models. The first improves conventional phrasing models on the position prediction of respiratory pauses (RPs), i.e., silent pauses at word transitions without punctuation. It performs speaker-conditioned RP prediction considering contextual information and is used to demonstrate the effect of speaker information on the prediction. The second model is further designed for phoneme-based TTS models and performs duration-aware pause insertion, predicting both RPs and punctuation-indicated pauses (PIPs) that are categorized by duration. The evaluation results show that our models improve the precision and recall of pause insertion and the rhythm of synthetic speech.